这篇文章主要是来总结一下目前在跨语言预训练模型方面的工作,当然啦,今年ACL有很多改进的工作,之后会再写一篇。这篇主要讲解的模型是:Multingual-BERT、XLM、XLM-R、MASS、MultiFiT。
Multilingual-BERT(m-BERT)
提出背景
m-BERT来源于《How multilingual is Multilingual BERT?》论文。主要是想探索:多语言BERT到底学到了什么?以及多语言BERT在零样本迁移学习上的表现如何?主要思路是将m-BERT在多语言上进行预训练,然后使用一个语言进行fine-tune,并在另一种语言上进行评估,fine-tune+eval在NER与POS两个任务进行了实验,最后并做了一些probing实验来探究m-BERT的跨语言迁移学习效果以及其表征能力。
实验思路
m-BERT仍然是由12层的transformer layer组成,但是它的训练语料是104种语言的维基百科页面数据,并且所有语言共享一个词汇表。注意:多语言BERT在训练的时候,既没有使用任何输入数据的语言标注,也没有使用任何翻译机制来计算对应语言的表示。最后作者是在NER与POS两个任务上进行实验,这两个任务都是先在一种语言上进行微调,然后在另一种语言上进行评估,从而来探究m-BERT在跨语言迁移学习上的效果。具体结果如下:

从结果上来看,fine-tune与eval阶段所使用的语言越相似,效果越好;结果最好的情况是fine-tune与eval使用同一种语言。
除了上述实验外,作者还探究了lexical overlap对结果的影响。所谓的lexical overlap,指的是:由于在m-BERT当中,所有语言共享一个词汇表,当fine-tune阶段出现了评估阶段所使用的语言的单词后,就会产生一种跨语言的迁移。作者设计了一些实验来探究了跨语言迁移学习的效果是有多大程度依赖于这个lexical overlap;以及当没有这种lexical overlap的时候,跨语言迁移学习的效果。
在NER任务中,为了测量lexical overlap的影响,定义了$E_{train}$与$E_{eval}$来分别表示训练集与测试集上的实体的集合,计算overlap的公式是:
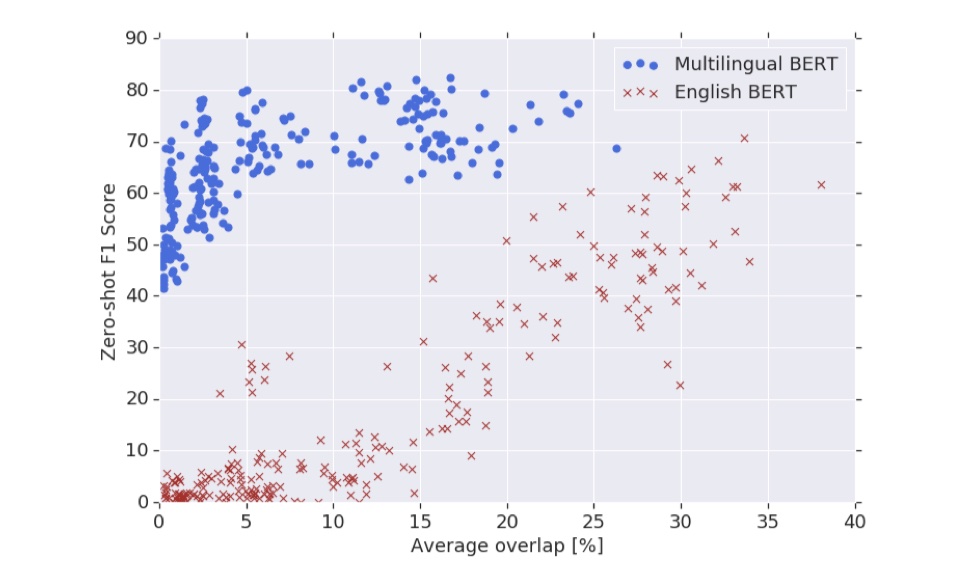
从上述结果中我们可以看到,英文BERT的效果非常依赖于overlap,迁移学习的效果会随着overlap的下降而下降;而对于多语言BERT而言,overlap对于其效果的影响并不大,说明多语言BERT在不同的文本上具有良好的泛化能力。
另外,作者还做了一些实验来探究多语言BERT在多语言文本混合(Code-switching)和音译(transliteration)的情况下表征能力。具体来说,作者进一步在UD语料库上测试了印地语(HI)和英语(EN)。多语言文本混合是指一个表达里面参杂多种语言,而音译则指将发音相似的外来词语直接通过读音翻译过来,比如酷 (cool)和迪斯科(disco)等。
XLM
提出背景
模型来源于《Cross-lingual Language Model Pretraining》论文。它的提出背景是:向BERT、XLNet等模型都是在单一语言上进行预训练和fine-tune,换一种语言就需要重新进行预训练+fine-tune,那能不能使用多种语言同时训练一个模型,之后通过一个模型就可以在多个语言上进行下游的任务呢?这就是XLM模型。具体做法是:提出了只使用单种语言的无监督学习方法与使用跨语言的平行语料的有监督学习方法,从而在跨语言分类、监督翻译与无监督翻译中取得了SOTA的效果。
实验思路
作者主要提出了三种loss fucntion:CLM、MLM、TLM。
- CLM:无监督单语单向LM训练任务,使用Transformer在给定前序词语的情况下预测下一个词的概率,实际上是一个transformer语言模型。
- MLM:无监督单语双向LM训练任务,这个与BERT的MLM基本上一样的, 不同的地方在于:BERT中,输入的是句子对,并且我们是去随机MASK掉15%的token,使用的时候,80%使用 [MASK] token 替换,10%用随机 token 替换,最后10%不变;而在XLM中,使用的是由任意数量的句子组成的文本流代替成对的句子(最长为256个token)。为了均衡稀有tokens和高频tokens,借鉴来word2vec中对高频词采样的方法:文本流中的tokens是以多项式分布进行采样的,并且其权重与它们的逆文本频率的平方根成正比。另外,去掉了segment embedding,从而换用了language embedding。
- TLM:有监督翻译LM训练任务,这个任务主要是为跨语言任务所准备的。TLM是对MLM的一种扩展。具体来说,我们将并行的翻译句子拼接在一起,然后对两个句子进行mask操作。譬如我们要做翻译的任务,那么我们通过TLM,就可以引导source与target句子的表征进行对齐。另外,这里也是去掉了segment embedding,换用了language embedding。

然后我们一般使用CLM或者MLM来进行单语言的预训练,然后根据下游任务来决定是否要加TLM。论文里主要是在跨语言分类(XNLI数据集)、有监督翻译与无监督翻译任务上进行实验。结果如下:
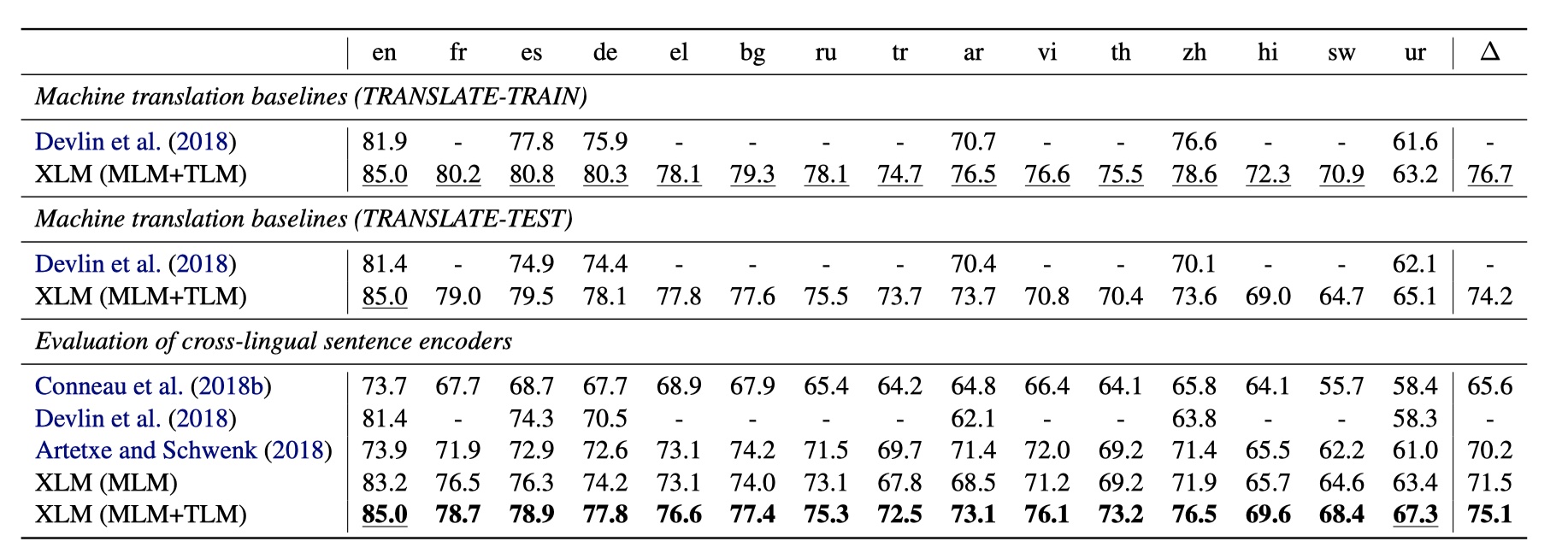
XNLI
作者是先用MLM在各个语言的单语语料上进行训练,然后再用英文训练集进行finetune,最后在多个语种上评估。结果如下:
无监督机翻
一般的套路是:DAE+back translation。DAE指的是:譬如我们要进行英译中这样一个任务,我们搭建一个encoder-decoder框架,将英文数据+噪声输入到encoder中,然后decoder出原始的英文数据,中文也可以这样做;back translation指的是:我们可以将英文通过encoder-decoder,得翻译的中文,然后将翻译后的中文+噪声再通过encoder-decoder,还原成原始的英文。在XLM中,使用CLM/MLM来初始化encoder与decoder部分,然后按照DAE+back translation的框架来训练即可,结果如下:

有监督机翻
这个就是普通的翻译,没什么可说的,结果如下:

论文另外还探究来模型在low-resource language上的结果以及无监督多语言情况下生成的embedding的情况。
XLM-R
XLM-R来源于《Unsupervised Cross-lingual Representation Learning at Scale》论文,是对XLM模型的拓展,主要是借鉴了RoBERTa模型的套路(大力出奇迹?)。具体而言就是,XLM-R模型在100种语言上使用超过2.5T的数据进行训练。相对于XLM,XLM-R使用了过滤后的CommonCrawl数据集,最终XLM-R在XNLI、MLQA、multilingual-NER这些多语言任务上均取得了最好的实验效果。主要的改进有以下几点:
- 在模型部分,整体与XLM基本一样,与XLM模型不同的地方在于:去掉了language embedding;
- XLM-R扩展到100种语言,与XLM-100不同的在于:在消融分析中使用了七种不同的语言:英语、法语、德语、俄语、中文、斯瓦希里语、乌尔多语,这样的话就可以将high-resource language与low-resource language都包含进来,可以比较正确的评价模型。
- 使用更多的数据,这与RoBERTa类似,更多的数据能够提升最终的效果。具体来说,对于low-resource language,我们去增加它的数目(类似于上采样?)。
最后就是一些实验结果,没什么太多可说的。
MASS
MASS来源于《MASS: Masked Sequence to Sequence Pre-training for Language Generation》论文。MASS模型提出的背景是:目前像BERT这样的预训练模型在各种NLU任务中表现的都已经很好了,但是在NLG任务上,却一直表现不佳,而且由于NLG任务标注数据较少,所以更加需要进行pre-train。在seq2seq架构中,一般的想法是:对encoder与decoder都进行pre-train,但是这样导致的问题就在于:这样训练得到的encoder与decoder的分布有可能会不一样,因为就是硬生生地将两个语言模型揉在一起。所以:要怎么对encoder与decoder都进行pre-train,同时还能保证它们的分布是一致的呢?这就有了MASS。

上面是MASS的架构,它整体的训练过程如下:
- encoder:输入是被随机mask掉之后的句子,但是与BERT不同的地方在于:MASS中是随机mask掉一段连续的token片段,而不是随机mask,这样做的好处在于:迫使模型从未被mask掉的词中提取更多的语义信息,从而用于后续decoder部分的预测。在实验中,mask的最佳比例在50%左右。
- decoder:输入是与encoder同样的句子,但是mask掉的正好和encoder相反,和翻译一样,迫使decoder通过encoder来得到的语义信息,强化attention部分,另外,只预测encoder部分别mask掉的词,能够加快训练。
MASS模型的loss function就是log-似然函数,这个没太多可讲的。
另外,值得一提的是:作者对k(mask掉的token的长度)进行了探究,并将BERT与GPT归结于MASS模型的特例。具体来说,当k为1的时候,encoder部分就只mask掉一个token,decoder部分mask掉所有token,来预测encoder中被mask掉的token,从这个角度来看的话,encoder就像是BERT中的backbone,而decoder就像是classifier;当k等于句子长度的时候,encoder部分我们全部mask掉,decoder部分我们都不mask,这样的话,encoder部分没有输入,decoder部分就相当于GPT。架构图如下:

MultiFiT
MultiFiT来源于《MultiFiT: Efficient Multi-lingual Language Model Fine-tuning》论文。它提出的背景是:目前大多数预训练模型都是在high source语言上进行的,譬如:英语、汉语等等,但是在那些low source语言上表现不好。所以这篇文章就提出了一个MultiFiT模型,能够在low source语言上取得较好的结果。
这里说的high source与low source是以标注数据的多少来判断的,如果标注数据比较多,那么我们就是它是high source语言,如果标注的数据比较少,甚至没有,我们就说它是low source语言。
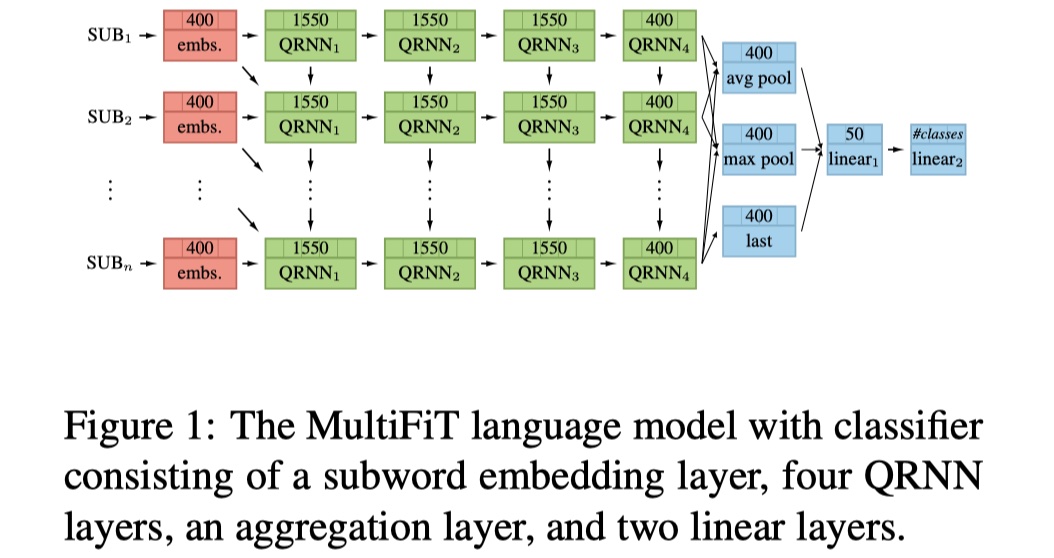
上面是MultifiT模型的架构图,总共是:1个subword embedidng layer+4个QRNN layer+1个aggregation layer+2个linear layer。这是有监督的情形,对于无监督的情形,也就是没有标注数据,论文中也提出了框架,如下:
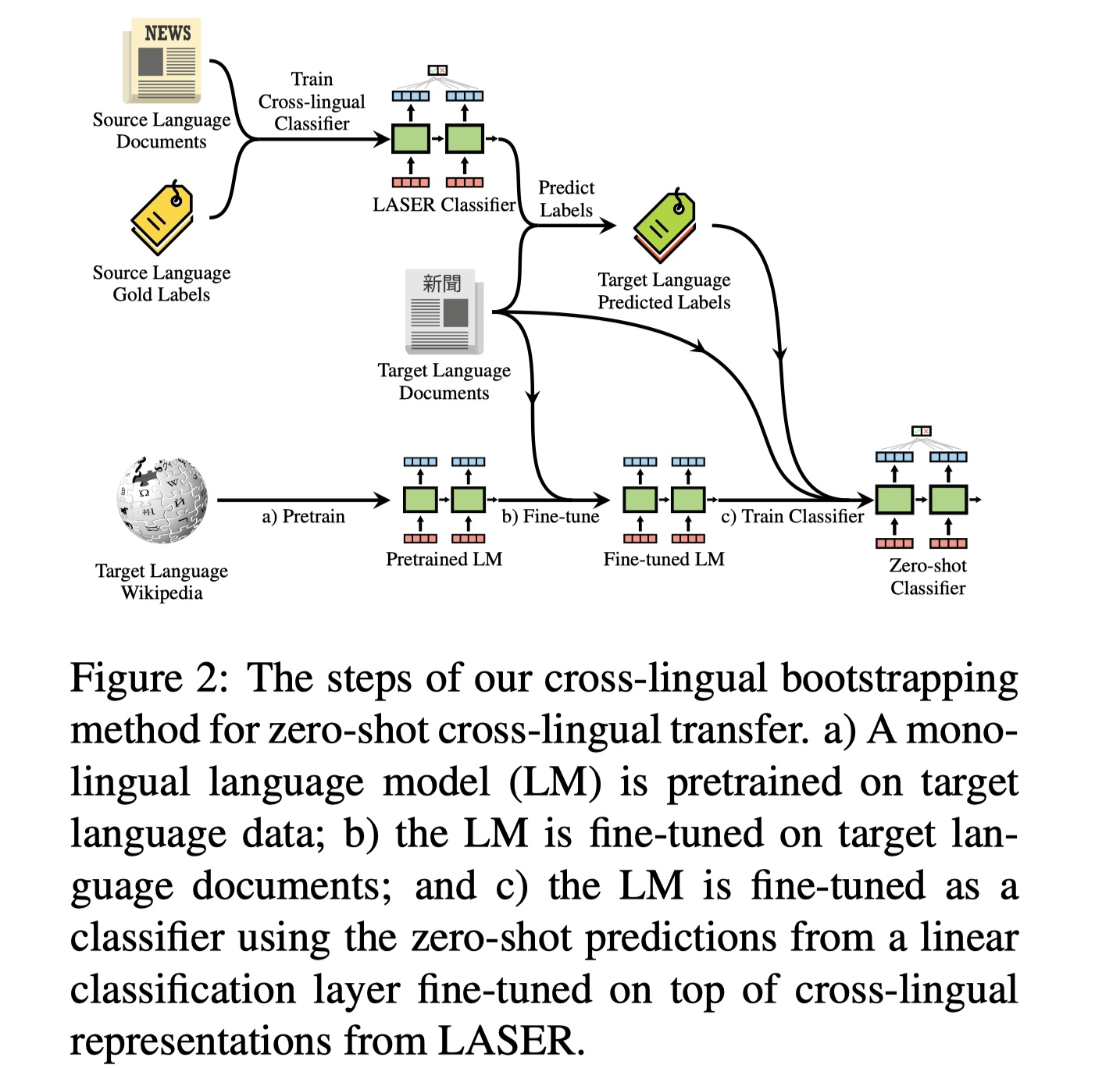
具体步骤如下:
- 预训练:首先在目标语言语料中进行单语预料的预训练;
- fine-tune:使用目标语言的任务预料进行fine-tune,其实就是使用任务语料再一次进行了预训练;
- 使用跨语言分类器(图中的是LASER),来对目标任务语料进行预测,并使用预测标签来进行单语的训练,相当于知识蒸馏。

最后是在MLDoc与CLS数据集上进行了实验,可以看到,不管是在有监督的情形下还是无监督的情形下,MultiFiT模型取的结果都要比之前的结果要好。

