目前关于预训练模型的改进大概是:模型小型化(蒸馏、剪枝、量化(混合精度训练)等)、网络结构的改进、多任务学习、更大的模型(增加模型capacity、增加算力等)、跨语言预训练模型等等,具体的可以看看FDU邱锡鹏老师关于PTMs的survey。这一篇博客主要介绍distill系列的预训练模型,主要是介绍distiilBERT、tinyBERT、fastBERT。(ps:最近和大佬们交流,深刻地意识到自己太菜了。。。害,努力吧。)
distillBERT模型
Google所发布的BERT以及后续对BERT进行改进的一系列预训练模型,虽然效果非常好,但是在infernce的速度仍然是比较慢的,无法满足生产环境中很多的场景。而hinton等人在2014年提出的知识蒸馏方法是提升速度的方法之一。而distillBERT正是将知识蒸馏方法应用于BERT模型所产生的一种预训练模型。
首先简单的介绍一下知识蒸馏,具体来说,我们定义两个网络:teacher model与student model。teacher model原有的预训练模型(譬如BERT),通过teacher model得到的结果的soft label作为student model学习的一部分。student model的训练由soft label与hard label组成。
为什么要用soft label呢?因为作者认为softlabel中包含有hard label中没有信息,也就是样本的概率信息,可以达到泛化的效果。
distillBERT模型架构
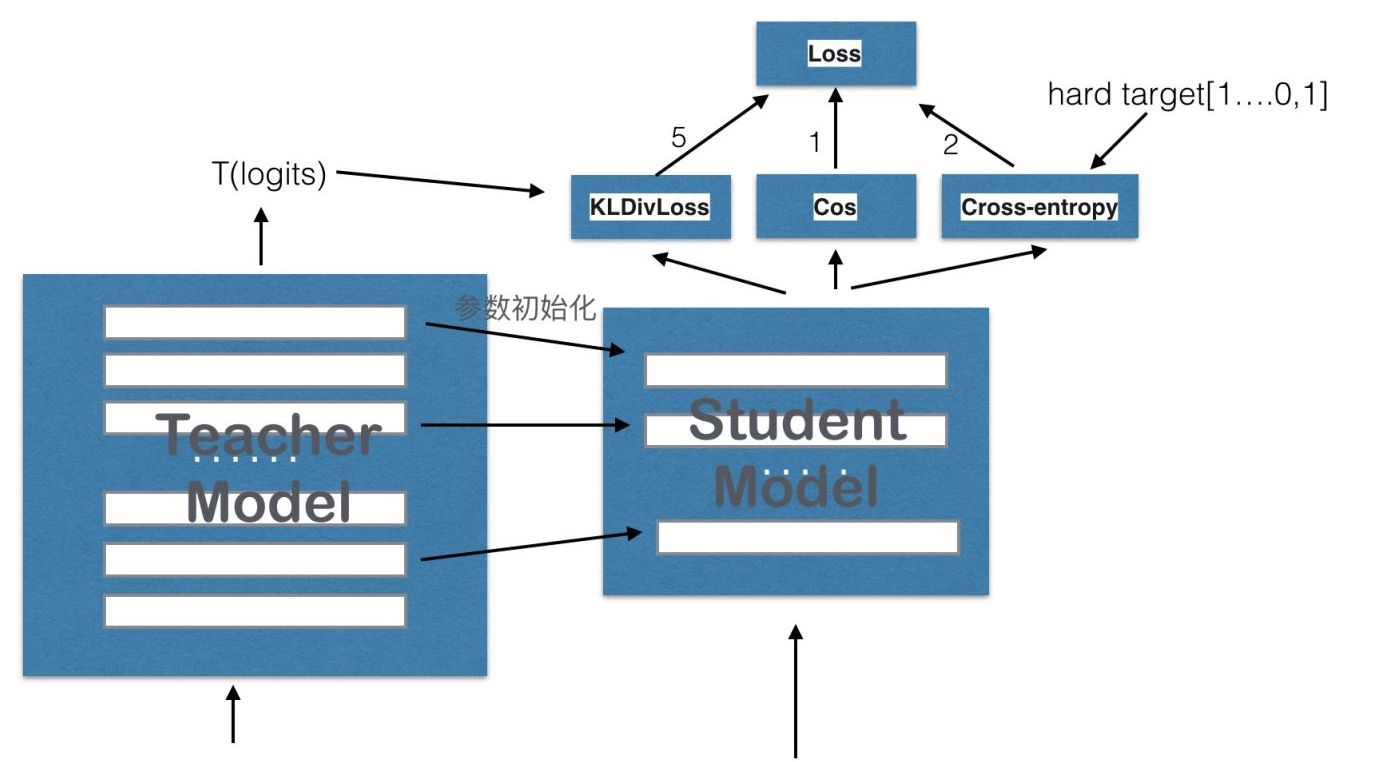
上面是distllBERT的结构图,整体来说与BERT非常类似,改动的地方如下:
- 将原始的BERT-base作为teacher model,并每两层只选择一层作为student model的layer,也就是说将BERT的层数减少了一半,每一层的参数初始化为teacher model的参数,即:用teacher的第2层初始化student的第1层,teacher的第4层初始化student的第2层;
- 去掉了token type embedding和pooler,也就是去掉了segment embedding;
- 使用与RoBERTa类似的动态masking的方法,并且去掉了NSP loss。
另外,关于distillBERT的预训练阶段的loss,共分为3部分,这里需要好好提一下:
$L_{ce}$ loss
所谓的$L_{ce}$ loss指的是:teacher网络softmax层输出的概率分布和student网络softmax层输出的概率分布的交叉熵(注:MLM任务的输出)。公式如下:
这里有点问题,在代码里使用的KL divergence,而不是CE。。。就按代码来吧。。。
其中,$t_i、s_i$分别表示teacher model与student model的soft label,他们的计算公式是$softmax-temperature$。
$L_{mlm}$ loss
$L_{mlm}$损失就是BERT当中所说的MLM loss,注意:这个是student model本身的mlm。
$L_{cos}$ loss
计算teacher hidden state和student hidden state的余弦相似度。官方代码用的是:nn.CosineEmbeddingLoss。
我们最终的loss是三种loss的线性相加,来对student model进行pre-training。
结果

从结果来看,distillBERT的表现与BERT接近,保留了97%的效果,参数量减少了40%,速度快出71%,可以说非常的优秀了。
tinyBERT模型
tinyBERT是另外一种使用知识蒸馏方法的预训练模型。它提出的背景是:transformer layer中的attention机制能够提取出非常丰富的语言知识,但是在之前的distillBERT中并没有将这些语言知识让student model给学习到。所以tinyBERT提出了一个两段式的知识蒸馏的框架,来解决这个问题。
tinyBERT模型架构
首先直接放tinyBERT的结构图,如下:
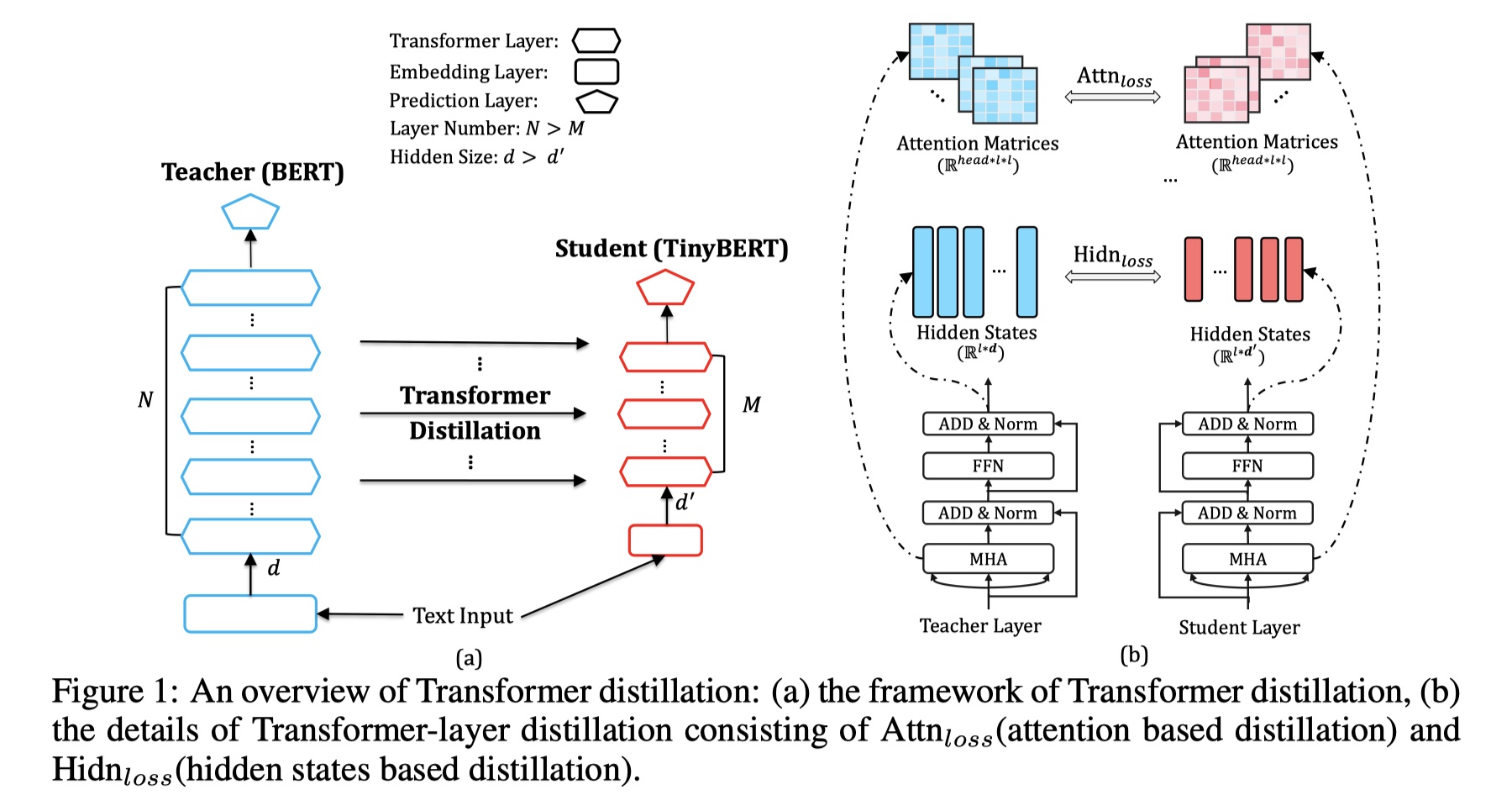
a图是tinyBERT的架构图,主要是对四个部分进行蒸馏,如下:
- embedding-layer distillation:在tinyBERT模型中,因为我们想要希望模型能够学到与teacher model相似甚至是相同的语义,所以我们采用MSE损失函数来对进行蒸馏。具体公式是:假设teacher model的embedding $E^S$的维度是$d$,tinyBERT的embedding $E^T$维度是$d’$,并且$d’<d$,loss formation 如下:
- Transformer-layer distillation:对于transformer layer来说,蒸馏的有两部分:attention loss与hidden loss。attention loss主要是希望tinyBERT中的multi-head self attention得到的scores能够接近teacher model的scores,因为有研究表明attention能够学到很多语义知识,包括语法等等。公式如下:
其中,h表示head的数目。
hidden loss指的是希望通过一个transformer layer得到的输出结果尽可能的靠近teacher model的结果,具体是b图。公式是:
- predcition-layer distillation:这是采用了交叉熵。公式如下:
在tinyBERT中,我们是首先在预训练阶段,使用embedding-layer distillation与transformer-layer distillation,在finetune阶段使用prediction-layer distillation。另外,需要讲解的是:tinyBERT是如何对层数进行蒸馏的?
在distllBERT中,我们是每两层选择一层,但是在tinyBERT中并不是这么的简单粗暴。假设teacher model有N层,我们的student model由M层,怎么进行映射呢?具体是:$0=g(0),N+1=g(M+1),n=g(m)$。也就说,embedding层对应于teacher model的embedding层,prediction layer对对应于teacher model的prediction layer,对于中间的 Transformer 层,TinyBERT 采用 k 层蒸馏的方法,即 g(m) = m × N / M。例如 TinyBERT 有 4 层 Transformer,BERT 有 12 层 Transformer,则 TinyBERT 第 1 层 Transformer 学习的是 BERT 的第 3 层;而TinyBERT 第 2 层学习 BERT 的第 6 层。
结果
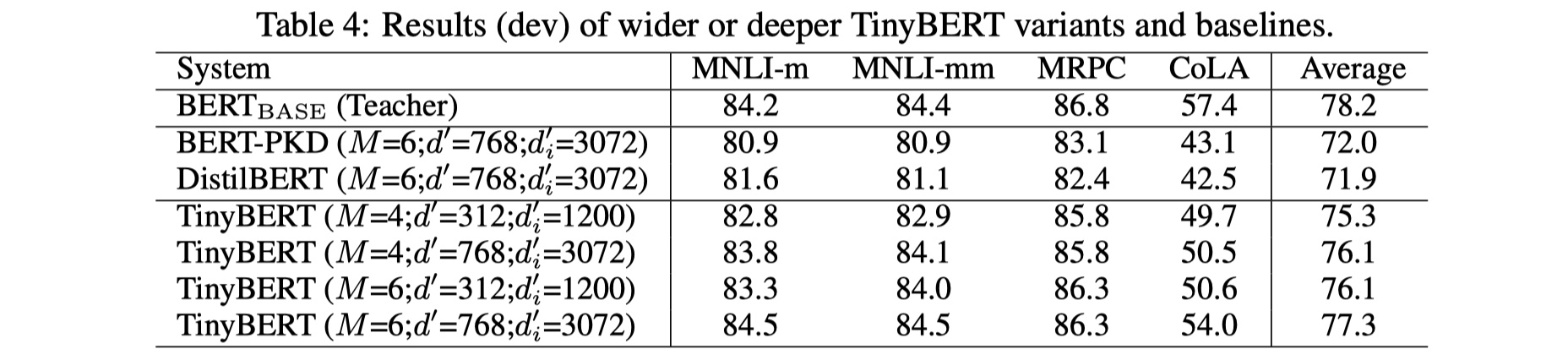
可以看到,在蒸馏成同样的层数的时候,tinyBERT的结果要比distillBERT要好很多,在某些数据集上甚至可以与BERT持平,还是非常非常优秀的。然后作者又做了很多消融分析,具体结果如下:
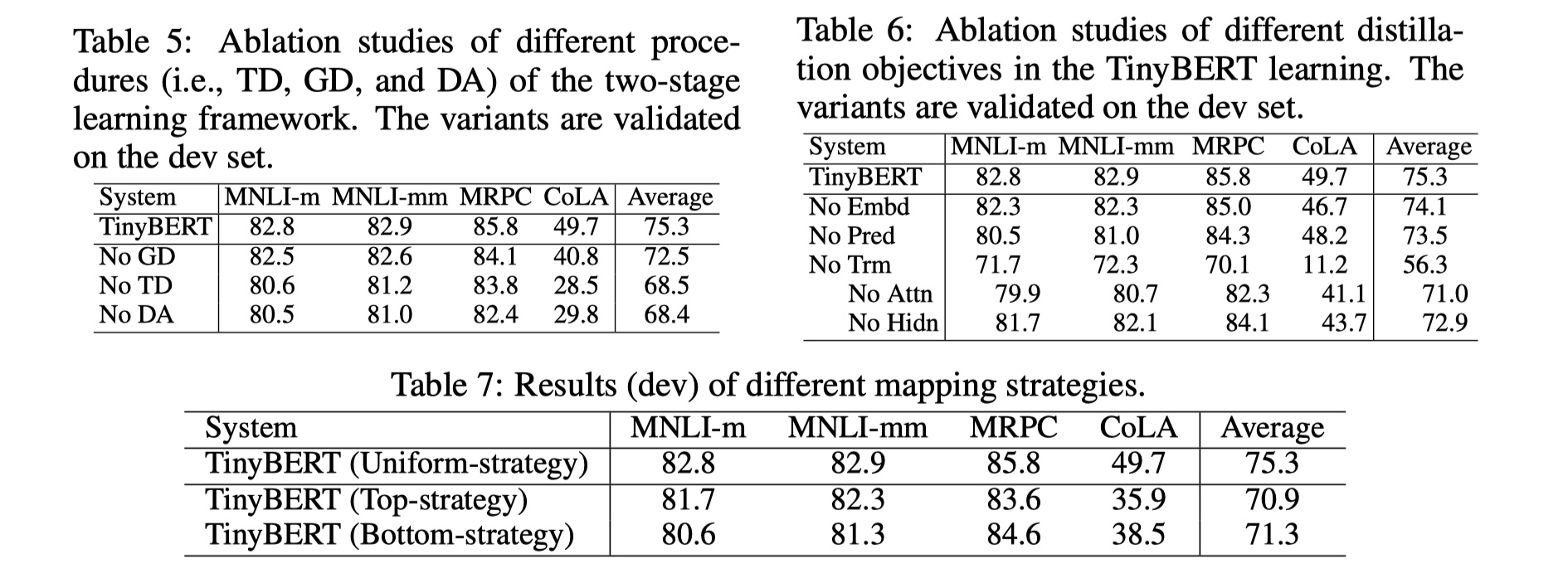
从结果上来说,所有的蒸馏objective都是有用的,尤其是对transfomer layer的蒸馏,当我们去掉transformer layer的时候,结果下降的非常厉害,所以,对于transformer layer的蒸馏是关键。
fastBERT模型
fastBERT是今年在ACL上发布的一个新的预训练模型,个人觉得在减小模型参数与加速inference速度上是非常优雅的,值得一读。它整体的创新有两个:样本自适应机制与自蒸馏方法。具体的,下面一一介绍~
fastBERT模型结构
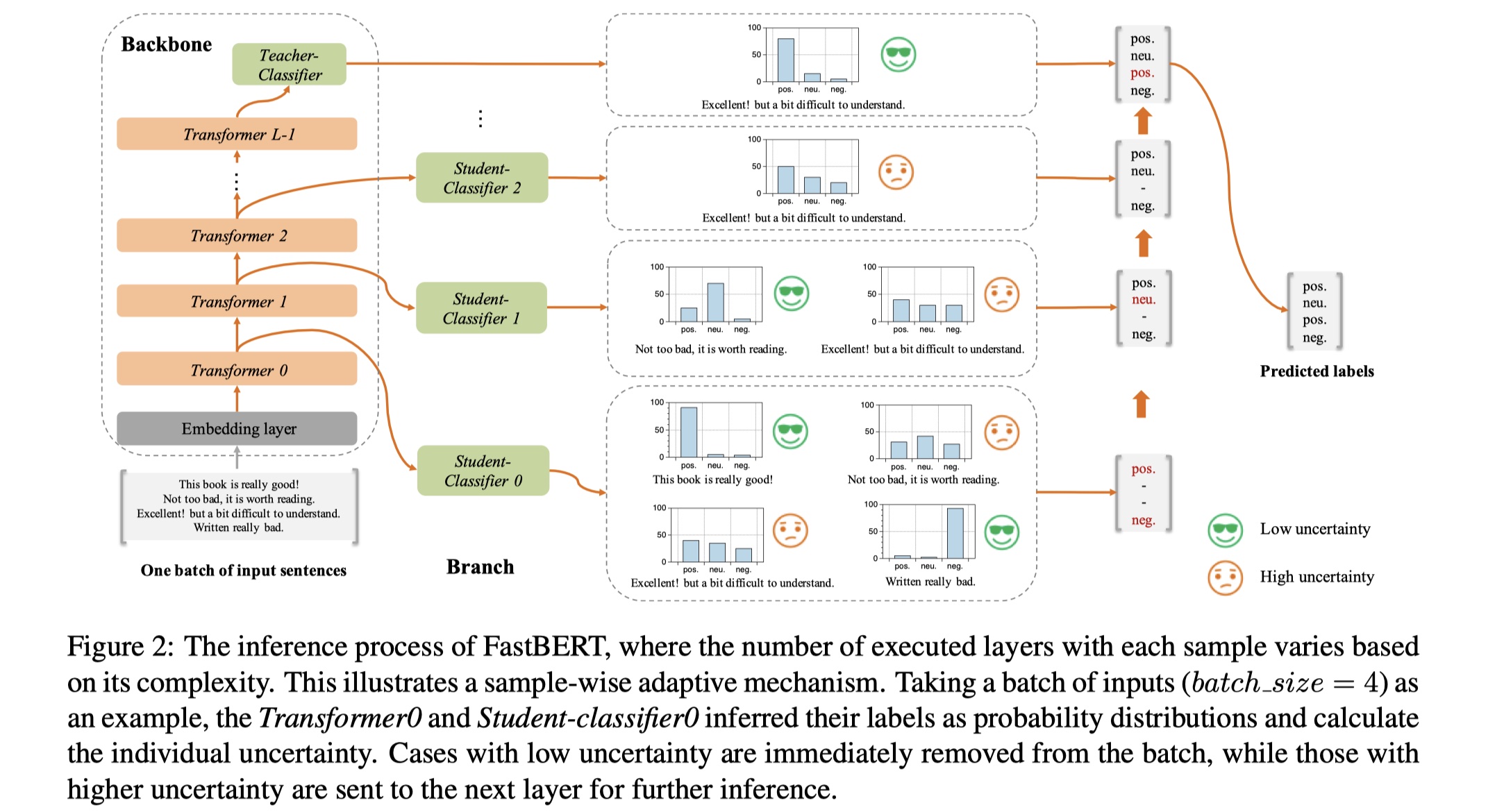
整体架构还是很好懂的,主要分为backbone与branch两部分,如下:
- backbone:与BERT-base一样,12层的transformer,在最后加了一层teacher classifier。
- branch:branch使用的是classifier,注意这里的classifier是根据teacher classifier蒸馏来的。论文称为自蒸馏方法。即:在pre-training与fine-tuning的时候,我们都只去更新backbone的参数,之后再frozenbackbone的参数,用branch classifier来蒸馏backbone中的classifier的概率分布。
整体模型的训练与inference的过程如下:
- pre-training:直接采用BERT、ROBERTa等模型就可以;
- fine-tuning for backbone:给BERT加上最后一层的classifier,用标注的来进行训练,这与传统的BERT的finetuning是一样的;
- self-distillation for branch:这里使用无标签数据就可以了。我们将backbone的分布蒸馏给branch classfier。这里使用KL散度来衡量两者概率分布,和distillBERT一样;最后的loss就是所有branch的KL散度之和;
- Adaptive inference:根据branch的分类器的结果来对样本进行过滤,简单的样本越早给出结果,越难的样本越晚给出结果。在论文里,作者基于熵给出了不确定性度量,来衡量样本的不确定程度。公式如下:
在每一层,作者都是用不确定性来衡量样本是否被舍弃,样本的不确定性如果在每一层低于阈值,然后就被立即丢弃,否则的话,就保留进入下一层;另外作者做实验验证了:低不确定性的样本被正确分类的概率高,高不确定性的样本被正确分类的概率低,所以即便在第一层就被舍弃了,但是被错误分类的概率很小。这个机制叫做样本自适应机制。这样做的一个好处就是:如果我们想要大幅提高inference的速度,那么我们就可以将阈值设置的大一点,这样的话,大部分的样本的结果在早期就被输出了。
结果
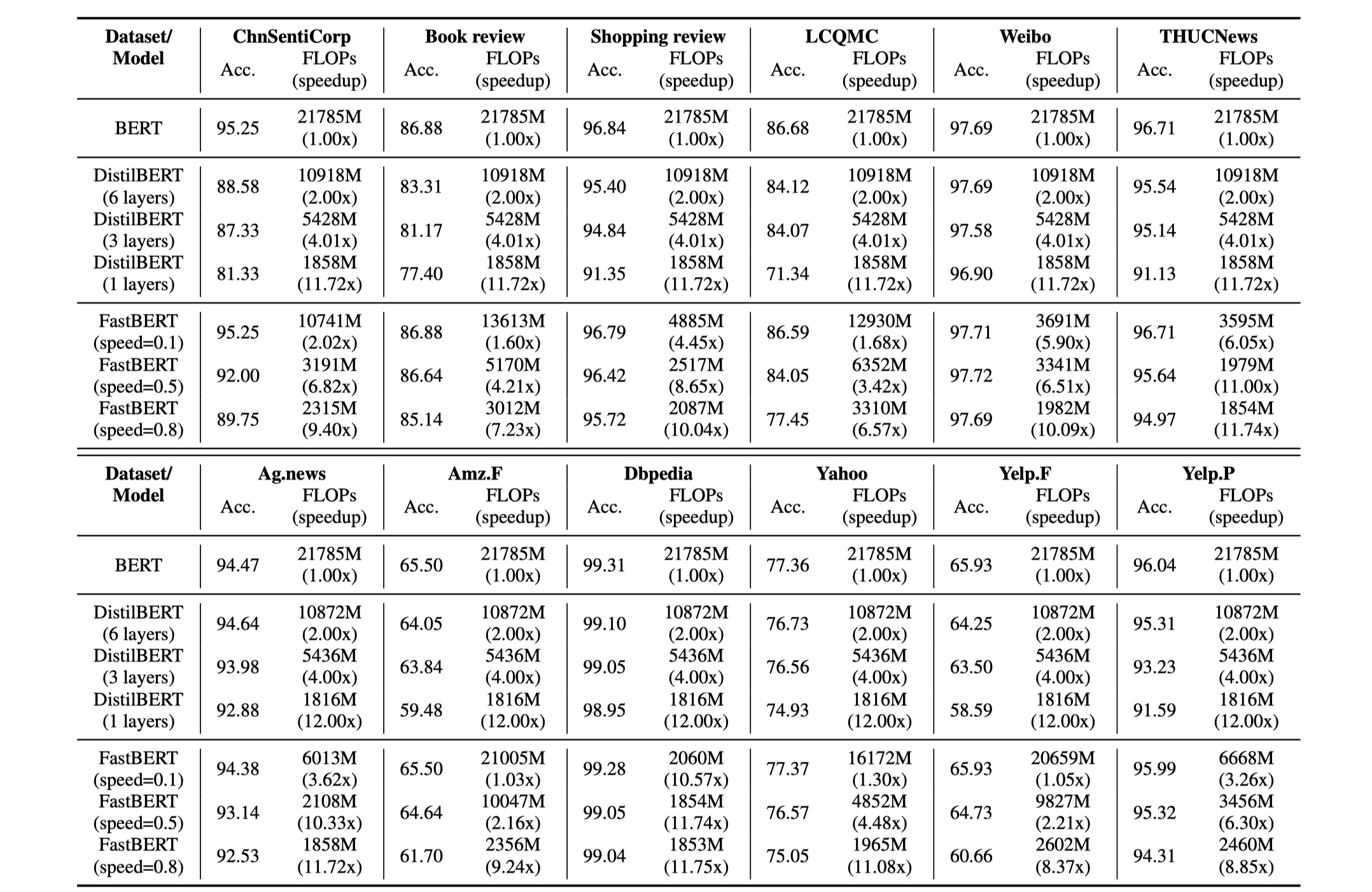
从结果来看,fastBERT要比distilBERT要好,其实我觉得它应该和tinybert这样的模型比较,distilbert算是很早的模型,总觉得结果不太solid。另外fastBERT模型目前只适用于分类任务,对于其他的序列标注等任务都不太适用,不过我觉得已经够了,现实中很多任务都可以被当作分类任务来做,还是有很大的应用价值的。
MobileBERT模型
mobile-BERT来源于《MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices》论文。我个人觉得整体模型并不优雅
MobileBERT模型架构
pass

