这篇文章主要是记录一下SBERT模型,其实这个模型思路很简单,基本上就是将InferSent中的BILSTM换成了BERT。但是呢,这篇文章对sentence embedding做了较为详细的介绍,读完之后,对sentence embedding有了较为详细的了解,所以,记录一下~
Sentence-BERT模型
BERT模型在各种NLU任务中基本上是都远超传统的深度学习模型,但是仍然有不足。譬如在文本匹配(or文本相似度计算)任务中,BERT的做法是:将两个句子用[SEP]token连接起来作为一个句子,再输入到BERT中。但是这么做的缺点是:当我们的数据量特别大的时候,论文说的是从10000个句子中找到与目标句子最为相似的句子,花费的时间为65小时,这显然是非常低效的。另外,也有研究人员将单个句子输入到BERT当中,对最后一个transformer layer进行平均或者只使用[CLS]token的张量,但是效果还不如GloVe embedding。于是,为了降低文本匹配的计算量与时间,并得到好的sentence embedding,就有了Sentence-BERT模型。
Sentence-BERT模型架构
根据不同的数据组织形式,SBERT有着不同的结构。在论文当中,提出了三种情况下的模型结构,如下:
- 当输入数据是[sentence1,sentence2,label],label是离散的,(对应的任务有NLI/RTE),具体结构如下:

这个结构完全借鉴于InferSent模型,只不过是将BILSTM部分用BERT来进行替换,注意:两个句子使用的BERT部分共享权重。对于BERT部分输出的结果,论文中探究了不同的pooling策略:只使用[CLS]token对应的张量、使用Global max pooling、使用Global avg pooling。(最终是avg pooling策略或者只使用[CLS]token对应的张量最好,这与InferSent中所得出的结论是不一样的,InferSent中使用max pooling最好)。得到$u$ 和$v$这两个句向量之后,然后再进行拼接,在这里,去掉了$u*v$这一部分,因为实验表明,加了这一部分,效果反而下降了。最后将拼接后的结果输入到softmax中进行分类即可。loss function采用交叉熵。数据采用SNLI和MultiNLI进行fine-tune,pre-train直接采用使用wikipedia预训练得到的权重即可。
优化器采用Adam,16 batch size,warm up 16%,pooling策略是avg。
- 当输入数据是[sentence1,sentence2,label],label是连续的,(对应的任务有STS(语义相似度计算)),具体结构如下:
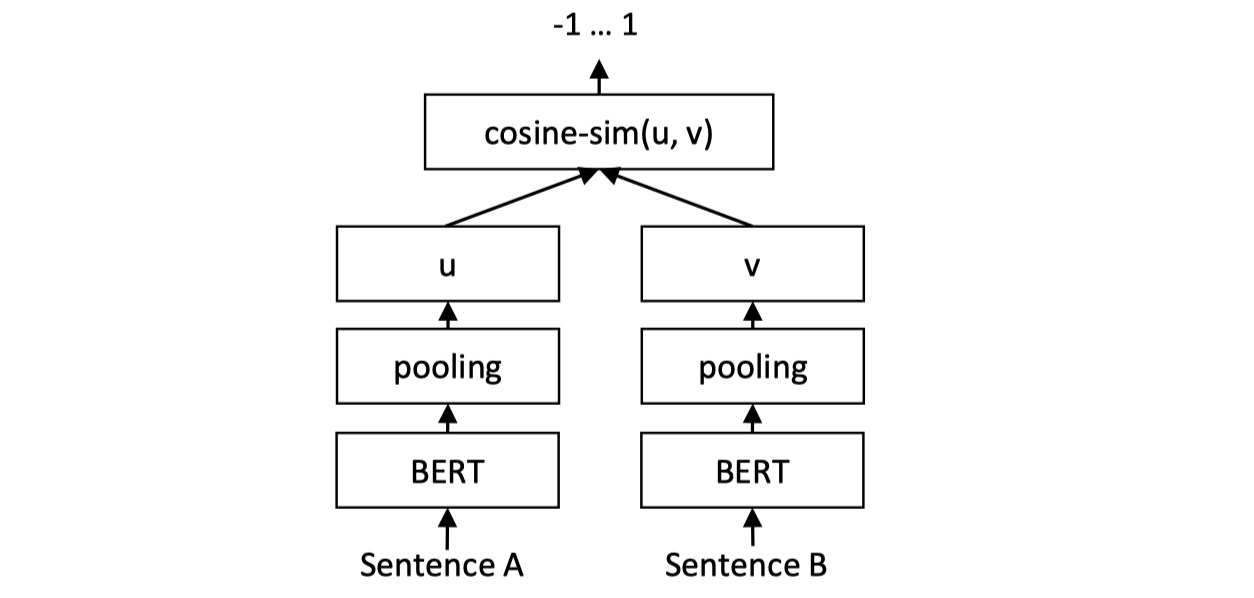
整体结构与第一种相同,不同的地方是:在得到各自的句向量之后,我们使用余弦相似度来进行度量,当然也可以使用其他的譬如皮尔森相关系数。loss function采用MSE。注意:论文里说没有任何与STS相关的数据进行训练,也就是说,在使用第一种架构进行fine-tune之后,我们将拼接与softmax给拿掉,换成cosine similarity就可以了。
- 当输入数据是[query,positive_answer,negative_answer],(对应的任务有问答匹配),具体结构与第一种结构相同,但是采用的loss function为triplet loss,公式如下:
也就是说,我们希望query与positive answer的距离比query与negative answer的距离要小至少$\epsilon$。这样的话,譬如在问答匹配里面,我们最后就会更加倾向于召回正确的回答,而不是错误的回答。在论文中,衡量query句向量与答案句向量之间的距离采用的是欧几里得距离,$\epsilon=1$。
实验结果
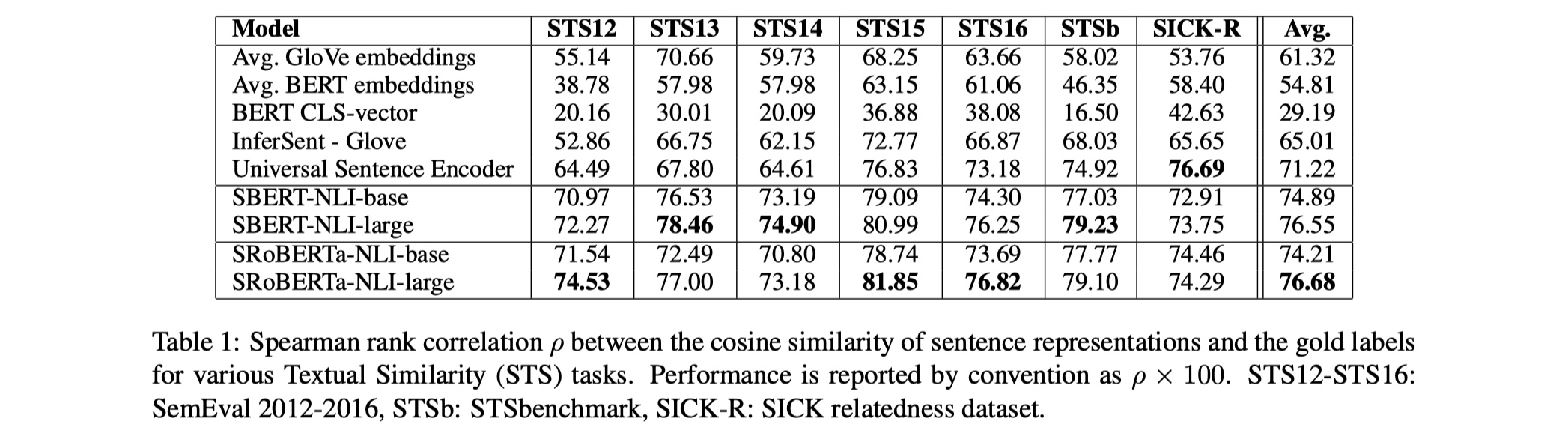
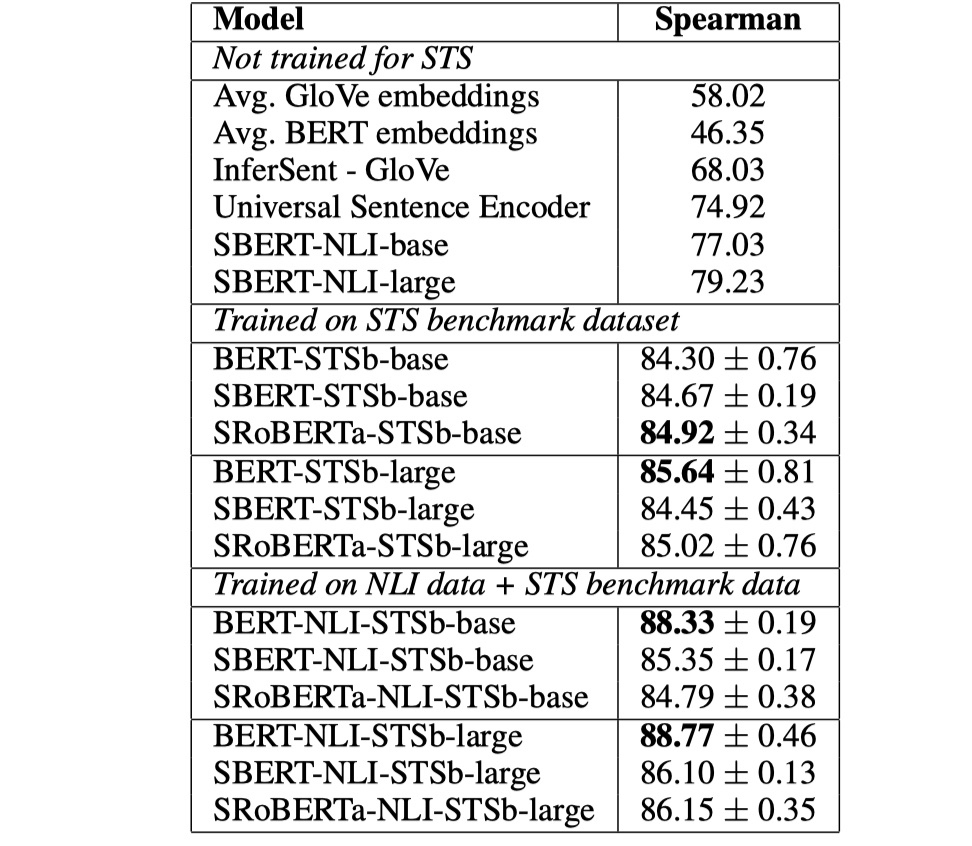
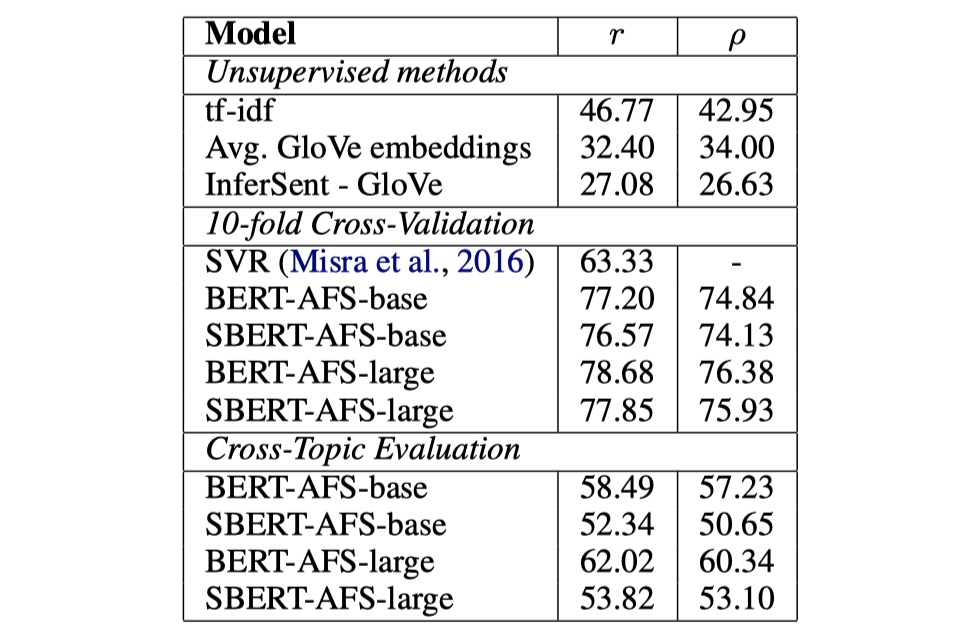
从结果来看,确实要比普通的InferSent或者USE要好。另外,我觉得这篇论文更大的意义在于实际应用吧,整体没有太大的创新。
Universal Sentence Encoder模型
打算再来看一下sentence embedding的部分吧,因为之前被问到了,我却只答上了InferSent以及一些普通的方案。。。惭愧啊。其实除了InferSent之外,USE也是非常著名的一个模型,下面具体讲解一下~大致来说,就是USE有两个encoder:一个是transformer,一个是DAN,前者准确率高但是计算代价大,后者准确率略有下降但是计算代价小,两者都在多个数据上进行迁移学习。

