条件随机场(CRF),属于判别模型,它在自然语言处理领域用途非常广泛。由于其涉及较多的概率图模型的知识,所以,这篇博客将首先介绍一下关于CRF模型的提出的原因,接着再介绍CRF模型需要解决的问题,并针对每个问题介绍其解决的算法,最后将使用python与sklearn库来对其进行实现。
条件随机场模型提出的原因
如果用一句话来总结CRF被提出的原因就是:CRF解决了MEMM模型的标注偏差问题,打破了齐次markov假设,使得模型更加合理。(如果不想看分析过程的话,可以直接跳过,看第二部分CRF模型的介绍。)具体分析过程,如下:
分类模型
首先,我们可以大致看一下分类模型。整个分类模型可以被分为:硬分类与软分类。硬分类的代表模型有:感知机(PLA)、支持向量机(SVM)、线性判别分析(LDA);软分类模型又可分为两类:判别模型与生成模型。判别模型的代表:逻辑回归(LR)模型以及最大熵(MaxEnt)模型;生成模型的代表:朴素贝叶斯(Naive Bayes)模型、隐马尔可夫(HMM)模型。之后,我们根据MaxEnt模型与HMM模型,可以得出一个判别模型——最大熵马尔可夫模型(MEMM),最后在MEMM模型的基础上,得出了条件随机场(CRF)模型。
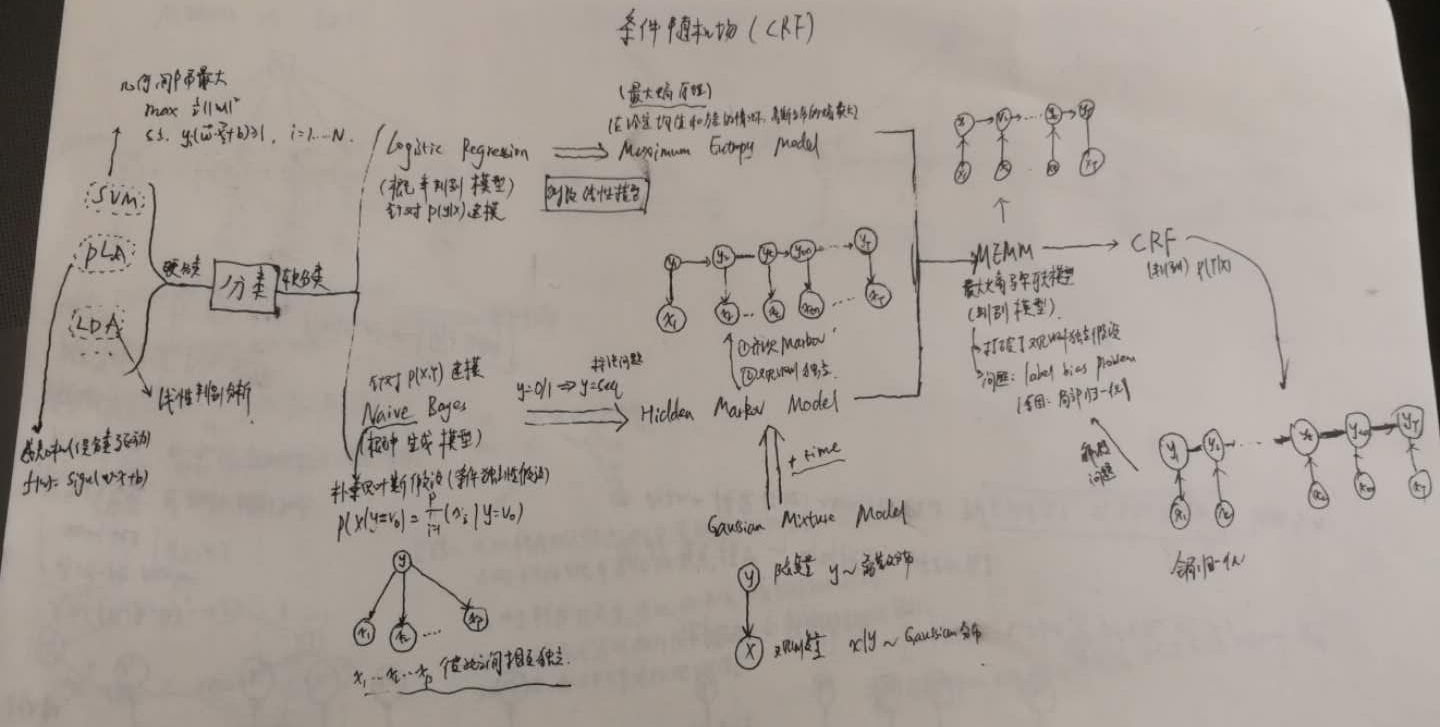
所以,CRF模型是从HMM到MEMM模型,一步步推出来的。那么,接下来,我们来具体看看是怎么得来的。
HMM vs MEMM
HMM模型,相信大家都很熟悉了,它可被用来解决词性标注等问题。HMM模型有两个很著名的假设:齐次一阶Markov假设与观测独立性假设。但是这两个假设都是合理的吗?其实不是的,如果对概率图模型的基本知识有些了解的话,我们会发现这两个假设其实都是为了简化运算。譬如说,我们来看观测独立性假设。它被描述为观测变量 $o_t$ 只与 $i_t$ 有关系,其实这是不合理的。以词性标注问题为例,单词与单词之间其实都是有关系的。那么,为了解决这个问题,MEMM模型便被提出来了,具体做法是:将原来的观测变量变为输入(从图的角度来说,就是剪箭头反向,具体为什么这样做就打破了观测独立性假设呢?其实和有向图的D-seperation有关,感兴趣的可以去了解了解这个)。MEMM的优点有:1.打破了观测独立性假设,使得模型更加合理;2.MEMM模型是判别模型,相比HMM模型来说,计算更为简单。但是MEMM模型也存在一个非常严重的缺陷:标注偏差问题(label bias problem)。这个问题会导致词性标注准确率大为降低。这也是MEMM模型没有流行的原因。
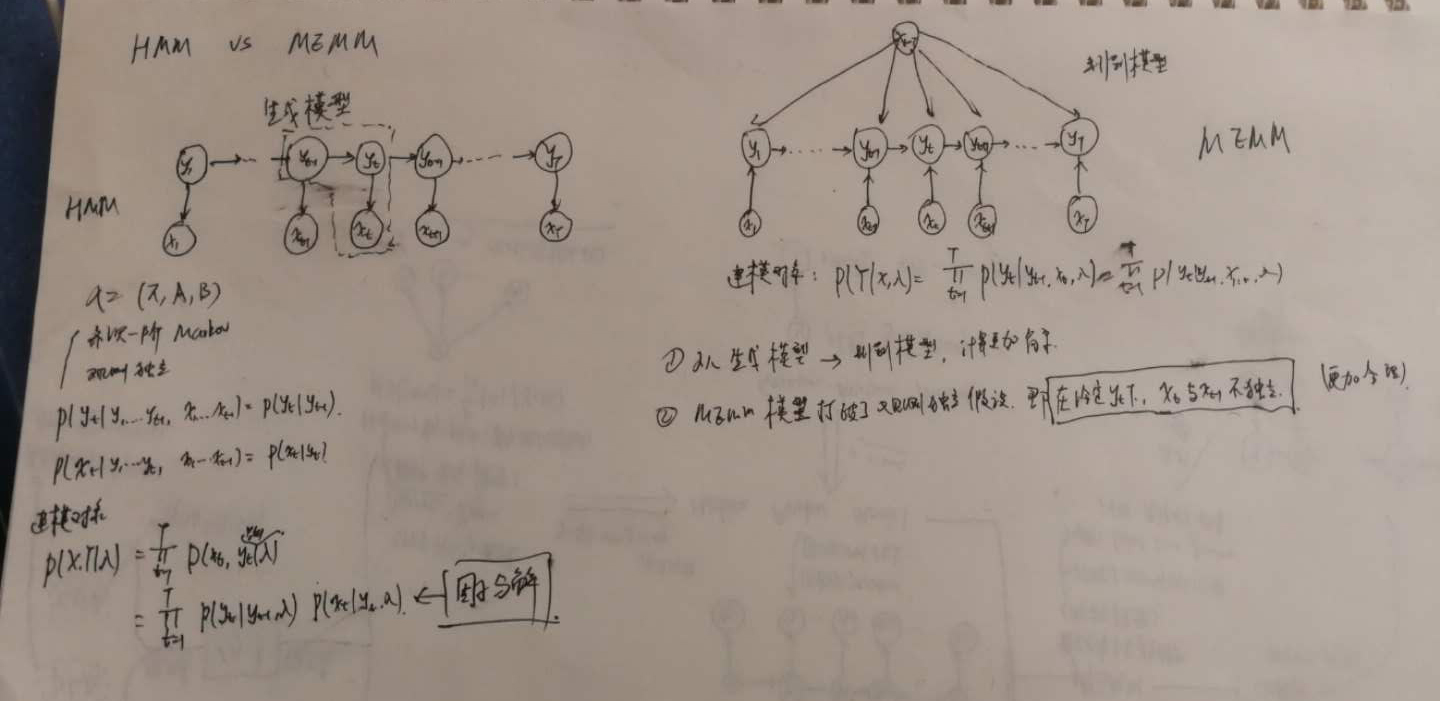
MEMM vs CRF
MEMM模型存在标注偏差问题,那么到底什么是标注偏差问题呢?(如果想深入了解的话,可以去看John Lafferty的那篇论文)。 如下:
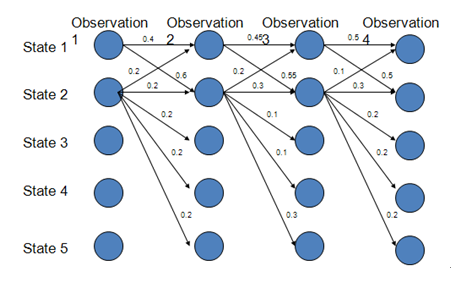
图中,每一列表示一个时刻,也就代表一个状态。当我们使用Viterbi算法去求具有最大概率的路径的时候,我们会得到1->2->2->2,概率是0.6*0.3*0.3=0.054,然而实际上最大概率的路径是:1->1->1->1,其概率是:0.4*0.45*0.5=0.09。那么,如果在词性标注问题中,就会导致标注发生错误。这就是标注偏差问题。那么导致这一问题的根本原因在于:局部归一化。也就是每一次从t时刻转移到t+1时刻的时候,都会对转移概率做归一化。从而,就会导致模型偏向于状态转移少的标签,从而使得后验概率最大,导致模型越不会去理睬观测变量的值,就会进行词性标注。
为了解决这一问题,就提出了CRF模型。CRF模型的具体做法是:将模型变成无向图,这样一来,就不需要在每一步都进行归一化,只需要进行全局归一化即可。这样,就解决了标注偏差问题。下面就讲具体介绍CRF模型。
条件随机场模型介绍
在介绍CRF之前,首先得先去了解有向图模型(贝叶斯网络)的因子分解与D-seperation,以及无向图(markov随机场)的D-separation(严格来讲,无向图没有D-seperation,但是它的结构和有向图的D-separation差不多,其实就是全局markov性)与因子分解。实际上,所谓的因子分解其实都是为了体现概率图模型的条件独立性。在无向图中,条件独立性表现在三个方面:全局markov性、局部markov性、成对markov性。那么因子分解为了表现其条件独立性,使用了基于团的方法,并有hammesley-Clifford定理得以保证。在这里,我就不详细讲了,如果讲的话,那就太多太多啦~感兴趣的同学可以去补补概率图的知识,就按照我上面讲的这些即可~
OK,直接进入主题。
CRF模型是给定随机变量$X$的条件下,随机变量$Y$的markov随机场。其概率图如下:

由于CRF模型是判别式模型,所以建模对象就是:$P(Y|X)$。也就是说,我们要求的是$P(Y|X)$。下面我们就来推导一下线性链CRF的参数形式。如下:

所以,我们现在得到了CRF的参数形式,当随机变量$X$取$x$,随机变量$Y$取$y$的时候,如下:
其中,$\lambda、\eta$ 都是需要训练的参数,$f、g$ 是特征函数,当满足某一条件的时候,为1,否则为0。在这里,需要注意的是,我所使用的符号与李航老师的《统计学习方法》不太一样,但是表达都是一样的,《统计学习方法》中将最外面的那个$\sum$放进去了,所以特征函数的参数就会多一个。其实都是一样的,我觉得最重要的是自己能够理解,并且方便自己记忆和推导就可以了:
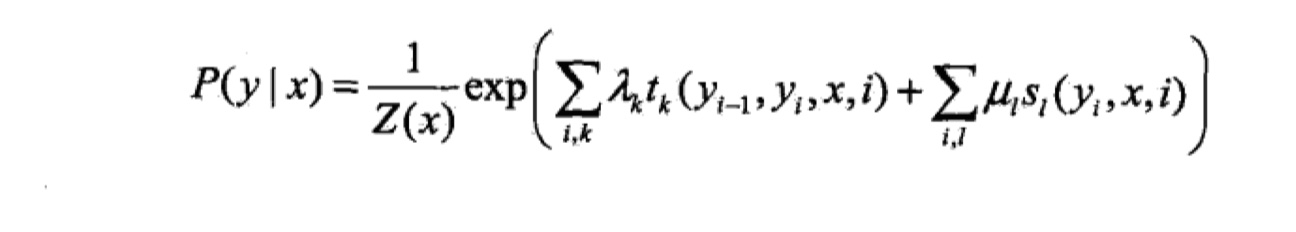
那么,我们使用将其化简为向量化的形式,如下:

所以,我们就得到了CRF的向量化形式:
那么,得到这个之后,我们就来解决CRF模型中的问题。CRF总共需要解决三个问题:
- 求边缘概率。即:求$P(y_t|x)$。
- 学习问题。即:给定训练集$\{x^{(i)},y^{(i)}\}_1^N$,求:$\theta=\mathop{argmax}\limits_{\theta}\prod_{i=1}^{N}P(y^{(i)}|x^{(i)})$。N个样本,其中x都是T维的。
- Decoding问题。即:求:$y=\mathop{argmax}\limits_{y}P(y|x)$。
边缘概率问题的求解
在这里,其实计算过程与HMM中的概率计算其实是一样的,同样引进前向后向算法,来减小计算复杂度。具体推导过程如下(推导过程采用了变量消除法):

我们可以看到,原来的计算复杂度为:$O(T|S|^T)$。当$T$很大的时候,复杂度是以指数形式增长的,这是不可解的。当我们已经引进前向向量与后向向量,那么就可解了。
模型参数的求解
关于CRF模型参数的求解方法,其实有很多。比如有:改进的迭代尺度法、拟牛顿法、牛顿法等等。在这里,我采用的是梯度上升法,因为是求最大,当然也可以将其转换为求最小问题,使用梯度下降法来解决。其实过程差不多的。具体推导过程如下(原谅我手机的渣渣像素,以后有时间再用markdown把公式打出来吧😩):

Decoding问题的求解
每次写博客,都感觉好累🥱。CRF的decoding问题,仍然是使用Viterbi算法进行求解,在这里,我就不推导了,直接放《统计学习方法》的截图吧,如果你之前看过我关于HMM模型的讲解那一篇的话,那么CRF的Viterbi算法也绝对能看得懂~

至此,关于CRF的理论部分就讲完了~
CRF模型的实现
把模型实现一遍才算是真正的吃透了这个模型呀。在这里,我采取了两种方式来实现CRF模型:python实现以及调用scikit-learn库来实现。我的github里面可以下在到所有的代码,欢迎访问我的github,也欢迎大家star和fork。附上GitHub地址: 《统计学习方法》及常规机器学习模型实现。具体代码如下:
python实现
1 | #coding:utf-8 |
sklearn实现
1 | #coding:utf-8 |

