KNN算法是一种较为简单的分类算法(也可用于回归问题),其可以实现多分类问题。本篇博客将详细地讲解KNN算法,并采用python与scikit-learn库两种方式,对KNN算法进行实现。
KNN算法介绍 KNN算法是比较简单的。它的整个应用过程如下:
输入:给定训练数据集$X=\{(x_1,y_1),(x_2,y_2),…,(x_N,y_N)\}$,其中,$x_i=\{x_i^{(1)},x_i^{(2)},…,x_i^{(n)}\}$,即每一个特征向量都有n维,$y_i\in \{c_1,c_2,…,c_k\}$,即总共有$k$个标签类别;待预测实例$x$。
输出:输出实例$x$所属的标签类别$y$。
计算实例$x$与所有训练集实例的距离,并从中选取$K$个最近的实例,这$K$个点所组成的区域叫做$x$的邻域。
根据分类决策规则,确定$x$所属的标签类别$y$。
是不是很简单?🤩从上述过程中,我们可以看到,KNN算法中,最重要的三个要素是:K值的选择、距离的计算、分类决策规则 。下面就讲一一介绍。
K值的选择 K值的选择,可以说是整个模型的核心。但是在实际上,并没有具体的公式精确地告诉我们,K值的选择。不过我们可以来分析一下:
当K值非常大的时候(譬如K=N),我们会发现,不管输入的$x$是什么,结果都不会变,都会偏向于训练集中大多数的那个标签类别,模型过于简单。
当K值非常小的时候(譬如K=1),那么,只有与输入实例相近的点才会起作用,那么如果恰巧是噪声的话,就会预测错误,所以,我们可以看到,K值太小的话,模型会变得复杂,容易发生过拟合。
所以,在实际中,会让K值取一个适中的值,或者采用交叉验证的方式来选取最优的K值。
距离的计算 在KNN算法中,一般我们会使用欧式距离,但是也有其他的距离,具体如下:
在KNN中,使用不同的距离度量,所得到的最近邻点是不一样的。
分类决策规则 在KNN中,分类决策规则一般都是多数表决。即:由K个实例中的多数标签类别决定。 使用公式表达如下:
其中,$I$是指示函数。
kd tree 其实,介绍完三要素后,KNN算法算是完成了。但是我们来思考一下KNN算法。我们每预测一个实例,都需要计算其与训练集所有实例的距离,并且从中取出K个实例。如果说,数据是高维的,并且训练集非常的大(mnist训练数据集中,有60000个),那么计算就会变得非常的慢。如果说测试集也非常大的话,那么所花费的时候就会更长。为了解决这个问题,就有人提出了kdtree。注意:这里的k说的是对k维空间进行划分,与K值不是一个概念!
所谓的kdtree,就是将特征空间划分为多个区域,如果说一些区域离待预测的实例的距离太远,那么就可以放弃掉这些区域,这样就大大减小了比较次数,提高了计算效率。
那我们具体来剖析一下kdtree。它其实是BST的变体。BST,相信只要学过数据结构,应该都非常熟悉。BST的左子树都比起父节点的值要小,其右子树都比父节点的值要大。 但是在BST中,所有节点都是一维数据,而在,kdtree中,所有节点都是多维数据。下面举个例子来说明kdtree是怎么工作的(《统计学习方法》中其实并没有讲地特别清楚😩):
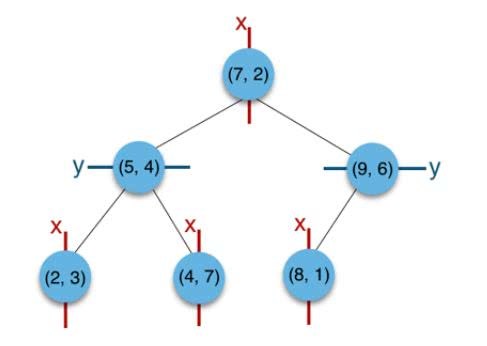
譬如说有集合$\{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)\}$。那么kdtree构建过程如下:
构建根节点时,此时的切分维度为$x$,集合在x维从小到大排序为$(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)$;它的中值为(7,2)。注意:2,4,5,7,8,9在数学中的中值为(5 + 7)/2=6,但因该算法的中值需在点集合之内,所以中值计算用的是 $len(points)//2=3, points[3]=(7,2) $)。 所以,$(2,3),(4,7),(5,4)$挂在$(7,2)$节点的左子树,$(8,1),(9,6)$挂在$(7,2)$节点的右子树。
构建$(7,2)$节点的左子树时,点集合$(2,3),(4,7)$ ,(5,4)此时的切分维度为y,中值为$(5,4)$作为分割平面,$(2,3)$挂在其左子树,$(4,7)$挂在其右子树。
构建$(7,2)$节点的右子树时,点集合$(8,1),(9,6)$此时的切分维度也为y,中值为$(9,6)$作为分割平面,$(8,1)$挂在其左子树。至此kd tree构建完成。使用二维空间画出来的话,如下:
OK,当构建完kdtree之后,那么如何对其进行搜索呢?
我们来查找点$(2.1,3.1)$,在$(7,2)$点测试到达$(5,4)$,在$(5,4)$点测试到达$(2,3)$,然后search_path中的结点为<(7,2), (5,4), (2,3)>,从search_path中取出$(2,3)$作为当前最佳结点nearest, dist为$0.141$;
然后回溯至$(5,4)$,以$(2.1,3.1)$为圆心,以$dist=0.141$为半径画一个圆,并不和超平面$y=4$相交,所以不必跳到结点$(5,4)$的右子空间去搜索,因为右子空间中不可能有更近样本点了。
于是在回溯至$(7,2)$,同理,以$(2.1,3.1)$为圆心,以$dist=0.141$为半径画一个圆并不和超平面$x=7$相交,所以也不用跳到结点$(7,2)$的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest$(2,3)$作为$(2.1,3.1)$的最近邻点,最近距离为0.141。
注意:上述是最近邻的过程,得出一个最靠近待预测实例的点,如果是K近邻的话,同样地,我们可以通过这样的方法,来得到K个最近邻的点。 至此,KNN算法的理论部分就讲完啦🎉
KNN算法的实现 把模型实现一遍才算是真正的吃透了这个模型呀。在这里,我采取了两种方式来实现KNN模型:python实现以及调用scikit-learn库来实现。我的github里面可以下载到所有的代码,欢迎访问我的github,也欢迎大家star和fork。附上GitHub地址: 《统计学习方法》及常规机器学习模型实现 。具体代码如下:
python实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 ''' 数据集:Mnist数据集(只使用了1000来训练,只使用了1000来测试。) 结果(准确率):0.738 时间:28.6643168926239 ''' import numpy as npimport timedef loadData (fileName ): ''' 加载数据 :param fileName: 数据路径 :return: 返回特征向量与标签类别 ''' data_list=[] label_list=[] with open (fileName,"r" ) as f: for line in f.readlines(): curline=line.strip().split("," ) data_list.append([int (feature) for feature in curline[1 :]]) label_list.append(int (curline[0 ])) data_matrix=np.array(data_list) label_matrix=np.array(label_list) return data_matrix,label_matrix class KNN (object def __init__ (self,train_data,train_label,K ): ''' 构造函数 :param train_data: 训练集的特征向量 :param train_label: 训练集的类别向量 :param K: 指定的K值 ''' self.train_data=train_data self.train_label=train_label self.input_num=self.train_data.shape[0 ] self.feature=self.train_data.shape[1 ] self.K=K def cal_distance (self,x1,x2 ): ''' 计算两个样本之间的距离,使用欧式距离 :param x1: 第一个样本 :param x2: 第二步样本 :return: 样本之间的距离 ''' return np.sqrt(np.sum (np.square(x1-x2))) def get_K (self,x ): dist_group=np.zeros(self.input_num) for i in range (self.input_num): x1=self.train_data[i] dist=self.cal_distance(x,x1) dist_group[i]=dist topK=np.argsort(dist_group)[:self.K] labeldist=np.zeros(10 ) for i in range (len (topK)): labeldist[int (self.train_label[topK[i]])]+=1 return np.argmax(labeldist) def test (self,test_data,test_label ): ''' 在测试集上测试 :param test_data: 测试集的特征向量 :param test_label: 测试集的标签向量 :return: 准确率 ''' error=0 test_num=test_data.shape[0 ] for i in range (test_num): print(f"the current sample is {i+1 } ,the total samples is{test_num} ." ) x=test_data[i] y=self.get_K(x) if (y!=test_label[i]): error+=1 accuracy=(test_num-error)/test_num return accuracy if __name__=="__main__" : start=time.time() print("start load data." ) train_data,train_label=loadData("../MnistData/mnist_train.csv" ) test_data,test_label=loadData("../MnistData/mnist_test.csv" ) print("finished load data." ) a=KNN(train_data[:1000 ],train_label[:1000 ],30 ) print("finished training." ) accuracy=a.test(test_data[:1000 ],test_label[:1000 ]) print(f"the accuracy is {accuracy} ." ) end=time.time() print(f"the total time is {end-start} ." )
scikit-learn实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 ''' 数据集:Mnist数据集(只使用了1000来训练,只使用了1000来测试。) 结果(准确率):0.799 时间:16.832828998565674 --------------------------- 果然,自己写的python没有编写kdtree等部分,效果与时间上都比不上sklearn。 ''' import numpy as npimport timefrom sklearn.neighbors import KNeighborsClassifierdef loadData (fileName ): ''' 加载数据 :param fileName: 数据路径 :return: 返回特征向量与标签类别 ''' data_list=[] label_list=[] with open (fileName,"r" ) as f: for line in f.readlines(): curline=line.strip().split("," ) data_list.append([int (feature) for feature in curline[1 :]]) label_list.append(int (curline[0 ])) data_matrix=np.array(data_list) label_matrix=np.array(label_list) return data_matrix,label_matrix if __name__=="__main__" : start = time.time() print("start load data." ) train_data, train_label = loadData("../MnistData/mnist_train.csv" ) test_data, test_label = loadData("../MnistData/mnist_test.csv" ) print("finished load data." ) knn=KNeighborsClassifier(n_neighbors=10 ) knn.fit(train_data[:1000 ],train_label[:1000 ]) prediction=knn.predict(test_data[:1000 ]) for i in range (1000 ): print(f"predict is {prediction[i]} ,the true is {test_label[i]} ." ) accuracy=knn.score(test_data[:1000 ],test_label[:1000 ]) print(f"the accuracy is {accuracy} ." ) end=time.time() print(f"the total time is {end-start} ." )