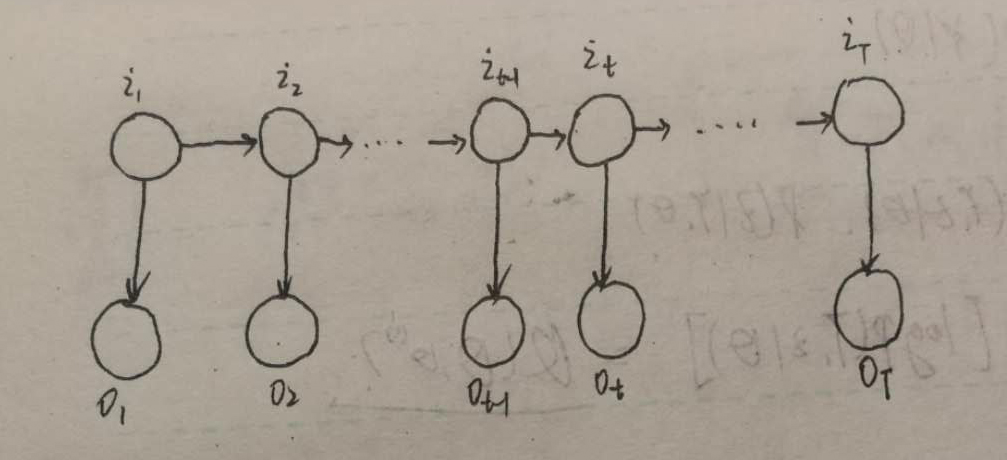
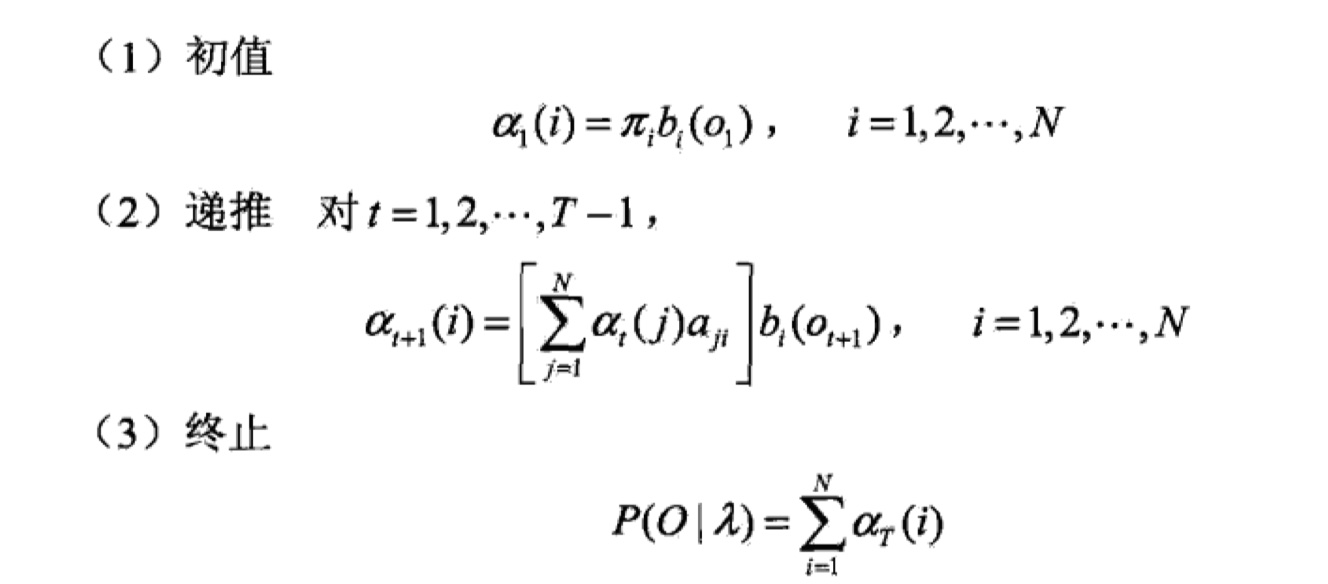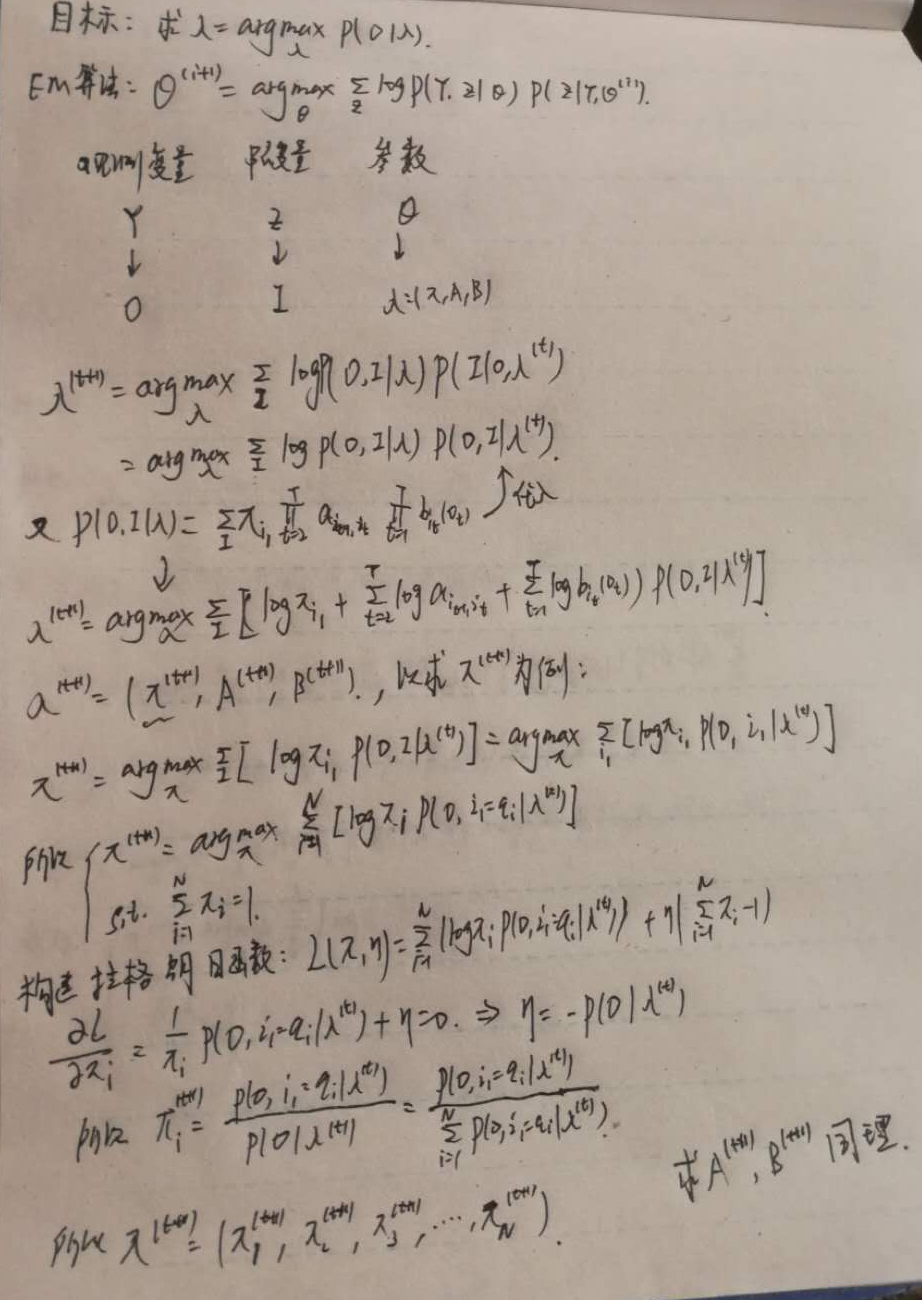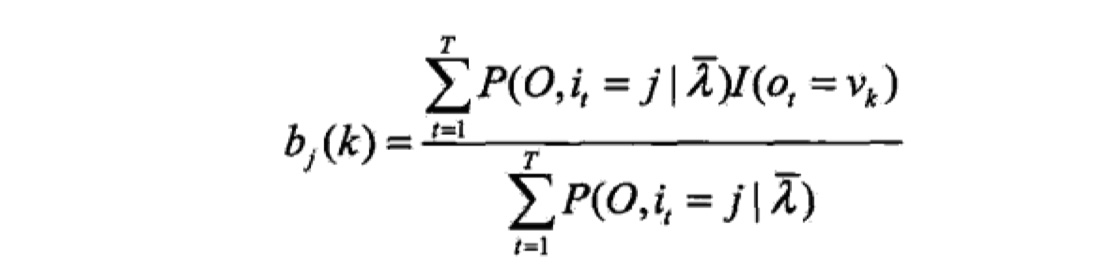# 公式 10.15 for i inrange(self.N): self.alpha[0][i] = self.Pi[i] * self.B[i][self.O[0]]
# 公式10.16 for t inrange(1, self.T): for i inrange(self.N): sum = 0 for j inrange(self.N): sum += self.alpha[t - 1][j] * self.A[j][i] self.alpha[t][i] = sum * self.B[i][self.O[t]]
for i inrange(self.N): for j inrange(self.N): denominator += self.alpha[t][i] * self.A[i][j] * self.B[j][self.O[t + 1]] * self.beta[t + 1][j]
return numerator / denominator
definit(self): """ 随机生成 A,B,Pi 并保证每行相加等于 1 """ import random for i inrange(self.N): randomlist = [random.randint(0, 100) for t inrange(self.N)] Sum = sum(randomlist) for j inrange(self.N): self.A[i][j] = randomlist[j] / Sum
for i inrange(self.N): randomlist = [random.randint(0, 100) for t inrange(self.M)] Sum = sum(randomlist) for j inrange(self.M): self.B[i][j] = randomlist[j] / Sum
deftrain(self, O, MaxSteps=100): self.T = len(O) self.O = O
# a_{ij} for i inrange(self.N): for j inrange(self.N): numerator = 0.0 denominator = 0.0 for t inrange(self.T - 1): numerator += self.cal_ksi(i, j, t) denominator += self.cal_gamma(i, t) tmp_A[i][j] = numerator / denominator
# b_{jk} for j inrange(self.N): for k inrange(self.M): numerator = 0.0 denominator = 0.0 for t inrange(self.T): if k == self.O[t]: numerator += self.cal_gamma(j, t) denominator += self.cal_gamma(j, t) tmp_B[j][k] = numerator / denominator
# pi_i for i inrange(self.N): tmp_pi[i] = self.cal_gamma(i, 0)
self.A = tmp_A self.B = tmp_B self.Pi = tmp_pi
defgenerate(self, length): import random I = []
# start ran = random.randint(0, 1000) / 1000.0 i = 0 while self.Pi[i] < ran or self.Pi[i] < 0.0001: ran -= self.Pi[i] i += 1 I.append(i)
# 生成状态序列 for i inrange(1, length): last = I[-1] ran = random.randint(0, 1000) / 1000.0 i = 0 while self.A[last][i] < ran or self.A[last][i] < 0.0001: ran -= self.A[last][i] i += 1 I.append(i)
# 生成观测序列 Y = [] for i inrange(length): k = 0 ran = random.randint(0, 1000) / 1000.0 while self.B[I[i]][k] < ran or self.B[I[i]][k] < 0.0001: ran -= self.B[I[i]][k] k += 1 Y.append(k)
return Y
deftriangle(length): ''' 三角波 ''' X = [i for i inrange(length)] Y = []
for x in X: x = x % 6 if x <= 3: Y.append(x) else: Y.append(6 - x) return X, Y
defsin(length): ''' 三角波 ''' import math X = [i for i inrange(length)] Y = []
for x in X: x = x % 20 Y.append(int(math.sin((x * math.pi) / 10) * 50) + 50) return X, Y
defshow_data(x, y): import matplotlib.pyplot as plt plt.plot(x, y, 'g') plt.show()
return y
if __name__ == '__main__':
hmm = HMM(15,101) sin_x, sin_y = sin(40) show_data(sin_x, sin_y) hmm.train(sin_y) y = hmm.generate(100) x = [i for i inrange(100)] show_data(x,y)