最近在看GAN相关的内容的时候,看到一篇关于预训练模型的新作:ELECTRA,核心是将GAN的思想引入到NLP中,非常地新颖。所以这篇文章将具体地讲解一下关于ELECTRA的内容,我个人是很喜欢这样精巧且优雅的文章的~🤩
ELECTRA模型是今年google在ICLR上放出的一篇论文。它的核心思想是:将GAN引入到NLP中,但是它所使用的Generator与Discriminator与GAN中的会稍微不同,通过设计新的预训练任务,从而大幅提升BERT的训练效率,节省算力。下面详细介绍一下~
ELECTRA要解决的问题
BERT已经被证明效果在多个自然语言处理任务中表现良好,但是BERT也存在非常大的问题:需要大量的训练数据与算力。导致这一问题的原因在于:MLM任务。在MLM任务中,我们是去MASK掉15%的tokens,再利用上下文来预测被MASK掉的tokens,这样的话,只有15%的tokens被用来训练,导致了BERT的训练非常的慢,并且也需要大量的训练数据才能将BERT训练的非常好。此外,MASK标签,也会使得也正是这个原因,从BERT到T5,再到GPT3,随着预训练模型效果越来越好的同时,模型也越来越大。而作者希望能够在不降低模型效果的情况下,去减小模型的大小以及所需的算力。于是,便提出来了ELECTRA模型。
ELECTRA模型架构
在ELECTRA模型中,针对上述问题的解决办法是:使用replaced token detection(RTD)预训练任务。具体来说,RTD预训练任务是去训练一个用来判别输入的token是原始文本的token还是被替换的token的Discriminator。不同于MLM任务,RTD不使用MASKING,而是用从一个给定的distribution中采样得到的一些tokens来替换掉原始的一些tokens,这个给定的distribution通常是一个小的MLM模型的输出(可以看作是Generator的输出)。这样的话,MLM只使用了被MASK掉tokens,而RTD则使用全部的tokens,做一个序列标注任务,所以RTD任务需要的算力就会小很多。最终我们预训练好之后,抛弃Generator,只使用Discriminator来进行fine-tune。RTD的架构如下:
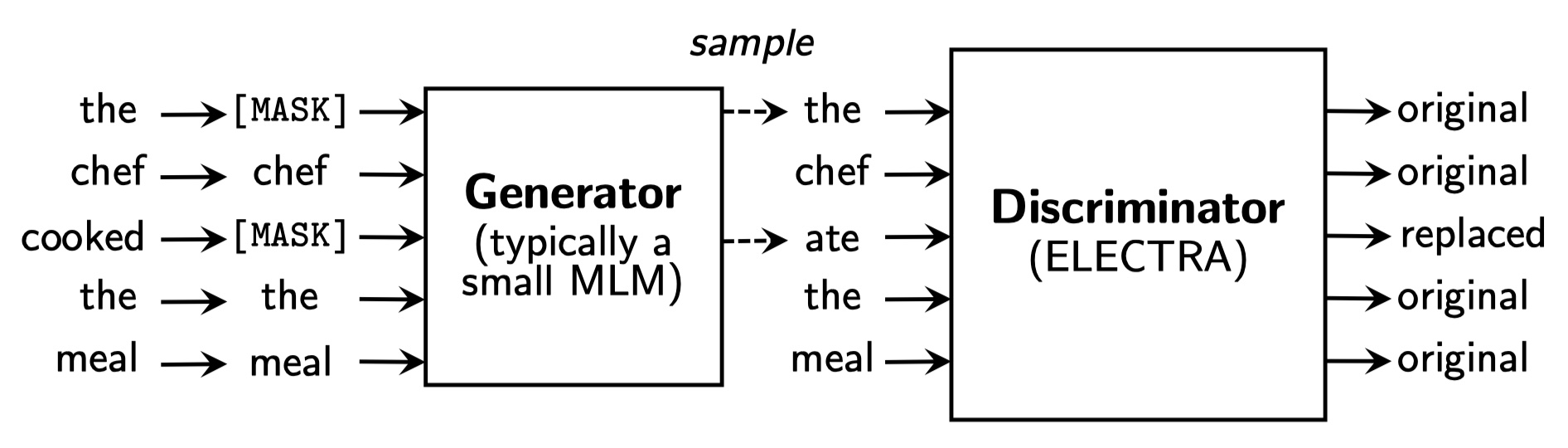
从上图中,我们可以看到,RTD的整个架构与GAN非常的类似,但是又存在不同的地方。具体细节如下:
- For Generator:在ELECTRA中,Generator一般是一个小型的MLM模型,其输入是tokens,其输出是替换过一些token之后的token。如果对GAN熟悉的话,我们就知道,input是满足某种的distribution的样本,通过generator之后,我们得到是另一种distribution的sample,尽管这种distribution我们不知道它的formulation,但是输出的tokens一定是满足这种distribution的。得到输出之后,我们并不将输出通过输入到DIscriminator中,来训练Generator。由于文本是离散的,GAN对于离散的数据是不好训练的,因为Discriminator的梯度无法反向传播到Generator中(其实也是有办法的,就是使用RL中的policy gradient来做,但是非常麻烦,并且后面的实验也表明,其结果并不如MLE)。那怎么训练Generator呢?在ELECTRA中,使用极大似然估计,来得到被MASK掉的token的概率,具体公式如下:
对于输入序列:$x=[x_1,x_2,…,x_n]$,通过Generator之后,得到$h_G(x)=[h_1,h_2,…,h_n]$,对于被MASK的位置$t$,Generator最后通过softmax来产生一个$x_t$的概率是: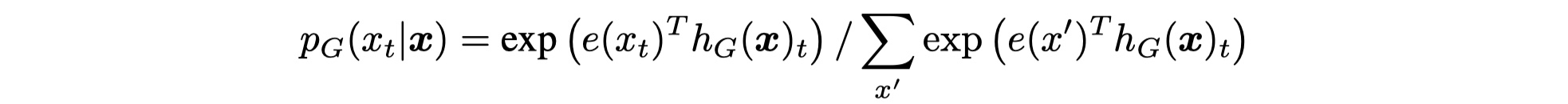
其中,$e(x_t)$表示token embedding。
- For Discriminator:在ELECTRA中,对于位置$t$,Discriminator来判别token是原始的token还是来自于Generator产生的distribution的token。formulation如下:
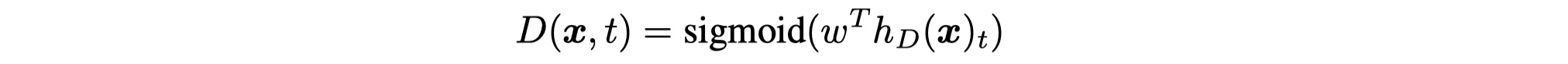
最终整个Generator与Discriminator用公式来表达其输入与loss的话,如下:

loss function应该不难理解,我们最终需要minimize如下formulation:
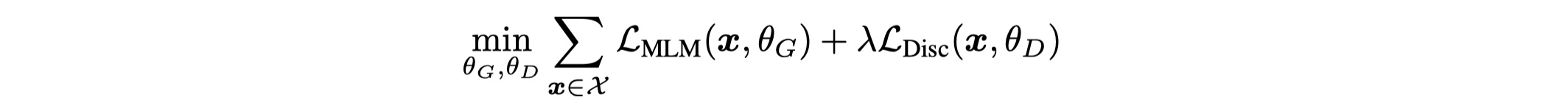
训练好之后,抛弃Generator,使用Discriminator来进行下游任务的微调即可。
ELECTRA模型优化与改进
weight sharing
作者想知道将Generator与Discriminator的参数共享是否会提升效果。作者设置了相同大小的Generator与Discriminator,在不共享参数的情况下,GLUE结果为83.6,只共享token embedding的结果为84.3,共享所有参数的结果是84.4。可以看到共享token embedding的效果很明显。这也说明Generator对于embedding有更好的学习能力。因为在MLM中,最后通过softmax,会去更新所有的vocab 的embedding;而在Discriminator中,只会更新输入的token的embedding。所以,最终作者选择了共享token embedding。
smaller Generator
作者探索了Generator的大小是否会对结果有提升。结果如下:
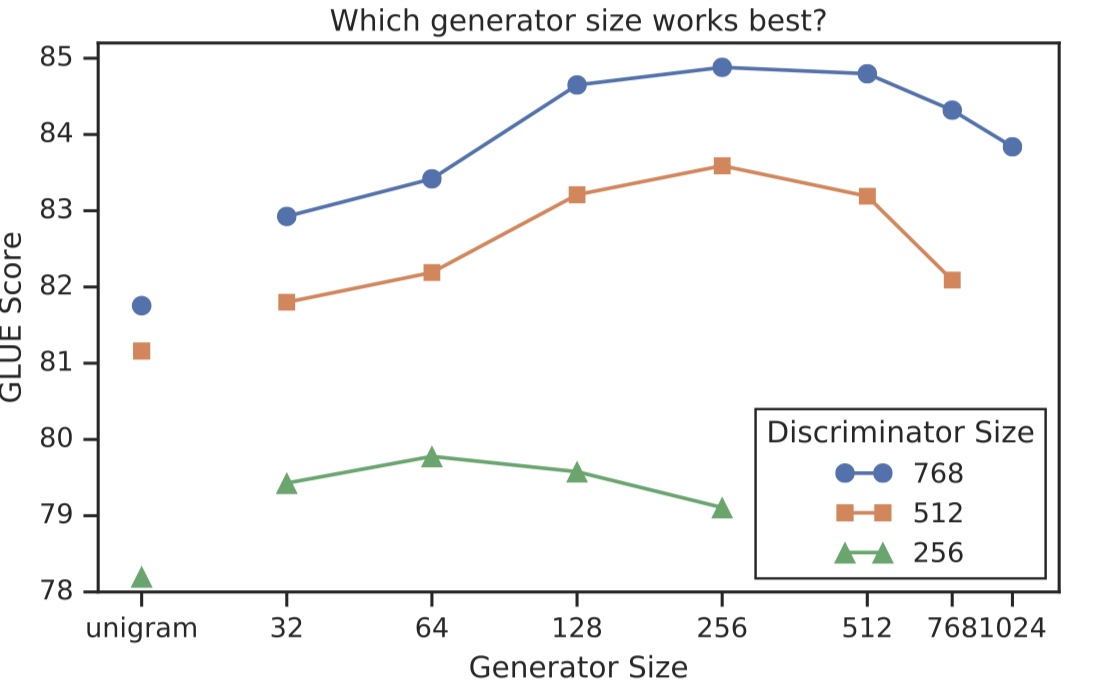
从结果上可以看到,Generator的大小在Discriminator大小的1/4-1/2之间效果比较好。原因在于:Generator如果太强了,会导致Discriminator的效果下降。
training algorithms
除了上述提及的训练策略,作者还试了其他两种策略,如下:
- Adversarial Contrastive Estimation:这实际上就是按照GAN的思路来做,即:将Generator的loss从MLM loss改为最大化被替换的token在Discriminator上的RTD loss,和GAN是一样的。但是一个很严重的问题是:Discriminator的梯度无法反向传播到Generator中,怎么解决呢?作者使用了RL中的policy gradient,使得梯度可以进行传导。最后的效果只有54%的准确率,而MLE的训练策略下,可以达到65%的准确率。
- Two-stage training:也就是我们先只去训练Generator,然后freeze掉Generator,将Discriminator的参数使用Generator的参数来进行初始化,之后对Discriminator训练与Generator同样的步数。
三种预训练策略结果对比如下:
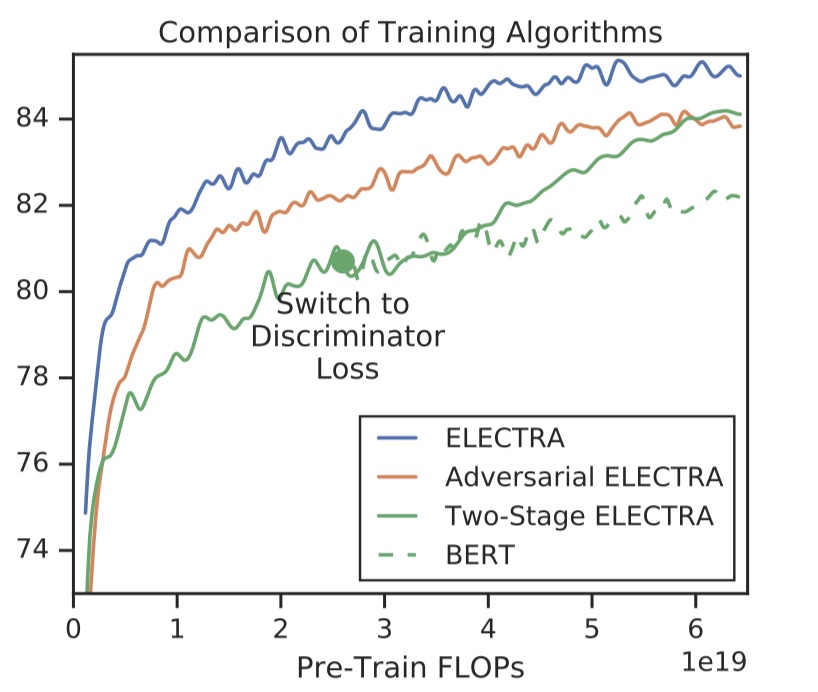
从结果可以看到,MLE的方式结果最好。
ELECTRA模型结果
在这里,作者疯狂地将ELECTRA与各种预训练模型进行对比,结果如下:
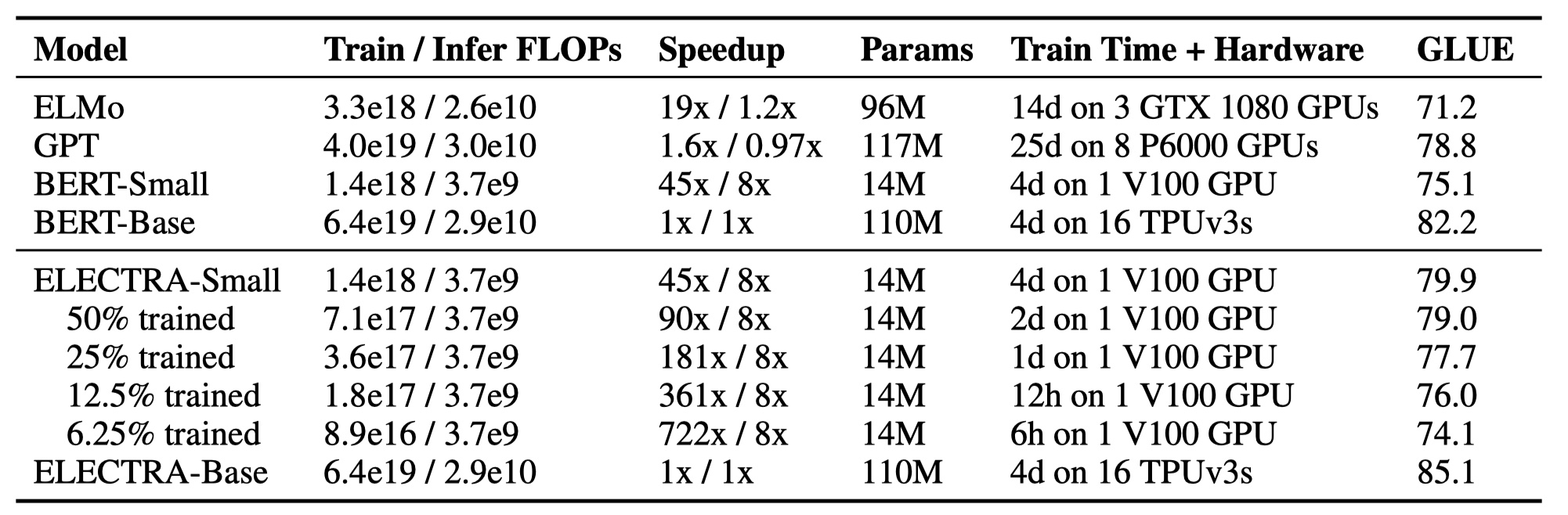
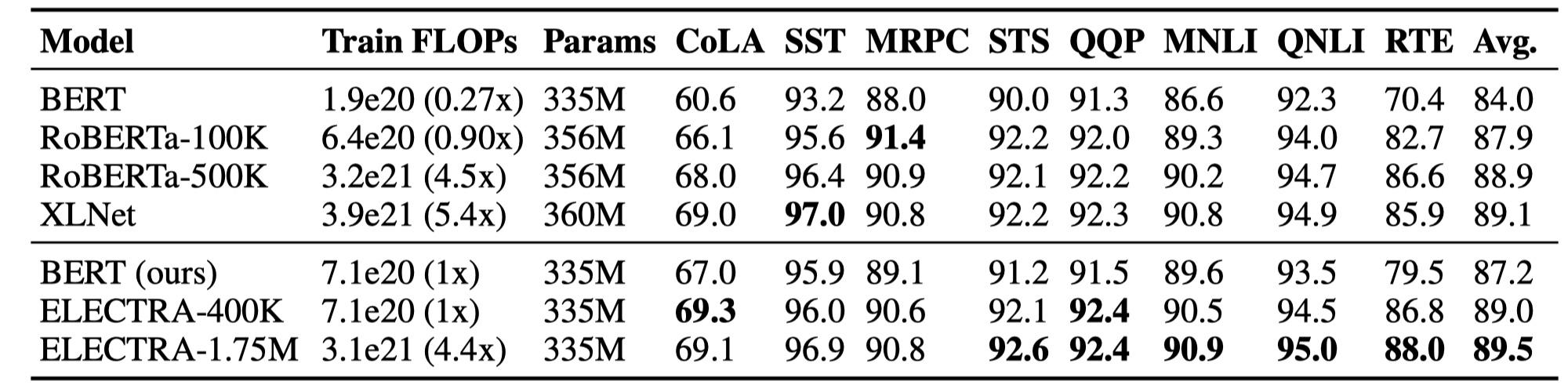
可以看到效果可以说是非常优秀了~
参考文献
《ELECTRA: P RE - TRAINING T EXT E NCODERS AS D ISCRIMINATORS R ATHER T HAN G ENERATORS》

