deftransformer_model(input_tensor, attention_mask=None, hidden_size=768, num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072, intermediate_act_fn=gelu, hidden_dropout_prob=0.1, attention_probs_dropout_prob=0.1, initializer_range=0.02, do_return_all_layers=False, adapter_fn=None): """Multi-headed, multi-layer Transformer from "Attention is All You Need". This is almost an exact implementation of the original Transformer encoder. See the original paper: https://arxiv.org/abs/1706.03762 Also see: https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py Returns: float Tensor of shape [batch_size, seq_length, hidden_size], the final hidden layer of the Transformer. Raises: ValueError: A Tensor shape or parameter is invalid. """ if hidden_size % num_attention_heads != 0: raise ValueError( "The hidden size (%d) is not a multiple of the number of attention " "heads (%d)" % (hidden_size, num_attention_heads))
# The Transformer performs sum residuals on all layers so the input needs # to be the same as the hidden size. if input_width != hidden_size: raise ValueError("The width of the input tensor (%d) != hidden size (%d)" % (input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and # forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on # the GPU/CPU but may not be free on the TPU, so we want to minimize them to # help the optimizer.
attention_output = None iflen(attention_heads) == 1: attention_output = attention_heads[0] else: # In the case where we have other sequences, we just concatenate # them to the self-attention head before the projection. attention_output = tf.concat(attention_heads, axis=-1)
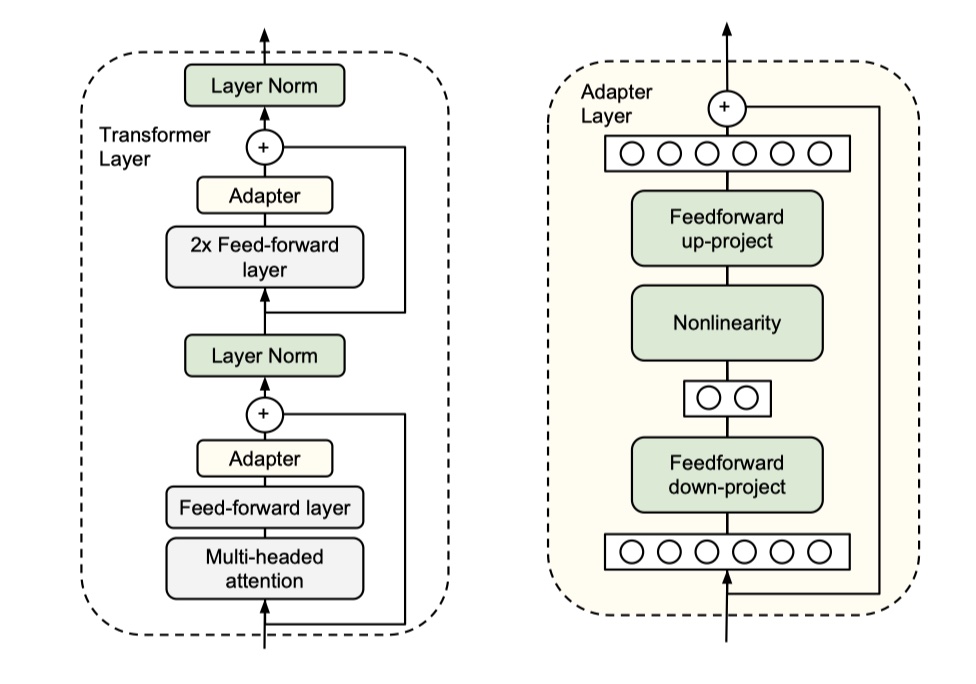
# Run a linear projection of `hidden_size` then add a residual # with `layer_input`. with tf.variable_scope("output"): # [batch_size*seq_length,hidden_size] attention_output = tf.layers.dense( attention_output, hidden_size, kernel_initializer=create_initializer(initializer_range)) attention_output = dropout(attention_output, hidden_dropout_prob) if adapter_fn: # adapter结构 attention_output = adapter_fn(attention_output) attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer. with tf.variable_scope("intermediate"): intermediate_output = tf.layers.dense( attention_output, intermediate_size, activation=intermediate_act_fn, kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual. with tf.variable_scope("output"): layer_output = tf.layers.dense( intermediate_output, hidden_size, kernel_initializer=create_initializer(initializer_range)) layer_output = dropout(layer_output, hidden_dropout_prob) if adapter_fn: # adapter 结构 layer_output = adapter_fn(layer_output) layer_output = layer_norm(layer_output + attention_output) prev_output = layer_output all_layer_outputs.append(layer_output)
if do_return_all_layers: final_outputs = [] for layer_output in all_layer_outputs: final_output = reshape_from_matrix(layer_output, input_shape) final_outputs.append(final_output) return final_outputs else: # [batch_size,seq_length,hidden_size] final_output = reshape_from_matrix(prev_output, input_shape) return final_output
deffeedforward_adapter(input_tensor, hidden_size=64, init_scale=1e-3): """A feedforward adapter layer with a bottleneck. Implements a bottleneck layer with a user-specified nonlinearity and an identity residual connection. All variables created are added to the "adapters" collection. Args: input_tensor: input Tensor of shape [batch size, hidden dimension] hidden_size: dimension of the bottleneck layer. init_scale: Scale of the initialization distribution used for weights. Returns: Tensor of the same shape as x. """ ''' input_tensor:[batch_size*seq_length,hidden_size] ''' with tf.variable_scope("adapters"): # in_size是self-attention layer的hidden_size,与这里的hidden_size不是一个概念! in_size = input_tensor.get_shape().as_list()[1] w1 = tf.get_variable( "weights1", [in_size, hidden_size], initializer=tf.truncated_normal_initializer(stddev=init_scale), collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES]) b1 = tf.get_variable( "biases1", [1, hidden_size], initializer=tf.zeros_initializer(), collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES]) # [batch_size*seq_length,hidden_size] net = tf.tensordot(input_tensor, w1, [[1], [0]]) + b1
# Implements linear decay of the learning rate. learning_rate = tf.train.polynomial_decay( learning_rate, global_step, num_train_steps, end_learning_rate=0.0, power=1.0, cycle=False)
# Implements linear warmup. I.e., if global_step < num_warmup_steps, the # learning rate will be `global_step/num_warmup_steps * init_lr`. if num_warmup_steps: global_steps_int = tf.cast(global_step, tf.int32) warmup_steps_int = tf.constant(num_warmup_steps, dtype=tf.int32)
# It is recommended that you use this optimizer for fine tuning, since this # is how the model was trained (note that the Adam m/v variables are NOT # loaded from init_checkpoint.) optimizer = AdamWeightDecayOptimizer( learning_rate=learning_rate, weight_decay_rate=0.01, adapter_weight_decay_rate=0.01, beta_1=0.9, beta_2=0.999, epsilon=1e-6, exclude_from_weight_decay=["LayerNorm", "layer_norm", "bias"])
if use_tpu: optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer)
# Normally the global step update is done inside of `apply_gradients`. # However, `AdamWeightDecayOptimizer` doesn't do this. But if you use # a different optimizer, you should probably take this line out. new_global_step = global_step + 1 train_op = tf.group(train_op, [global_step.assign(new_global_step)]) return train_op
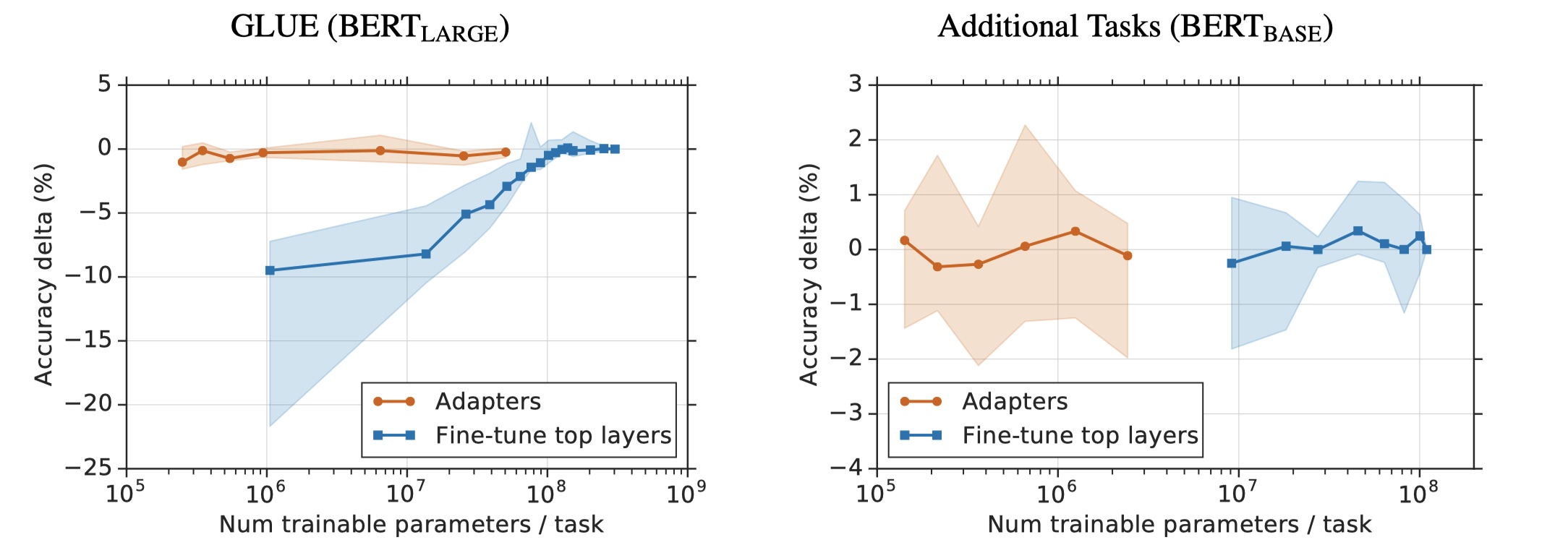
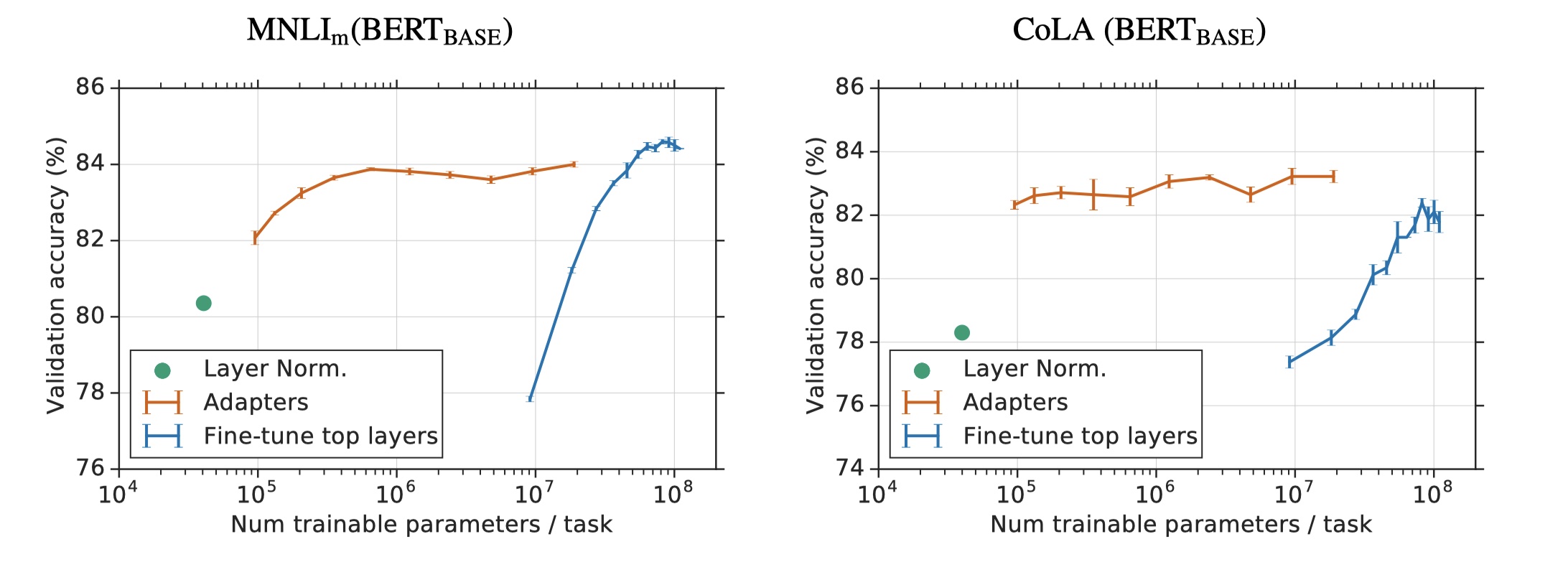
到此,Adapter-BERT的论文预代码部分都讲完了☕️~
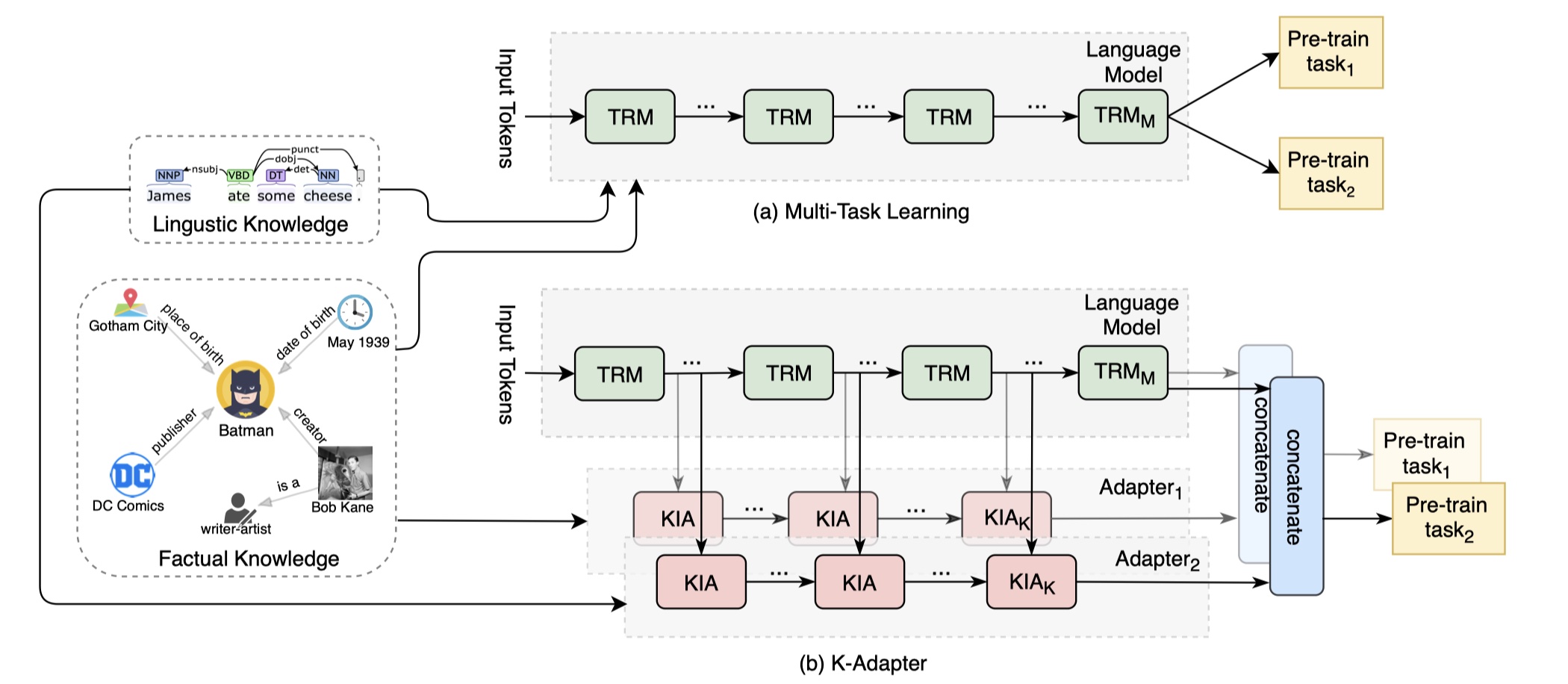
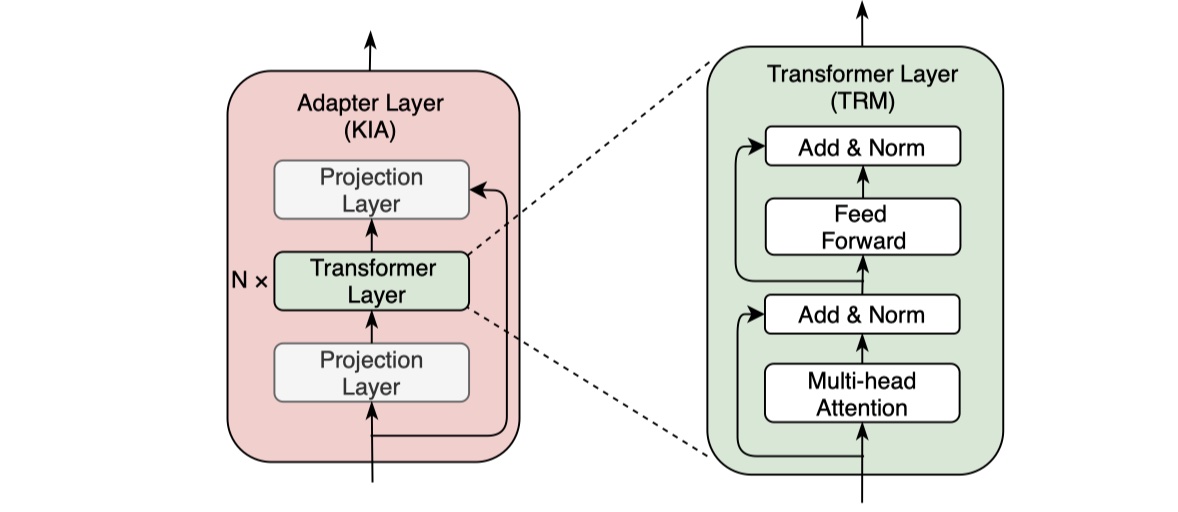
K-Adapter
K-Adapter模型来源于MSRA的《K-A DAPTER: Infusing Knowledge into Pre-Trained Models with Adapters》论文。它所要解决的问题是:在预训练模型中嵌入知识是非常重要的,因为当前的预训练模型无法学习到非常的知识信息;此外,在训练multi-task时,会出现灾难性遗忘问题,所谓的灾难性遗忘问题指的是:同一个模型,在学习完一个task之后,如果再学习新的任务,那么在原先的task上学习到的权重会被完全破坏掉,如果我们想要解决灾难性遗忘的问题,我们就需要用到持续学习。在这个背景下,K-Adapter预训练模型被提出来了。