XGBoost模型是集成学习中最为著名的一个模型。不用我说,我相信只要做ML/DM/DL领域的筒子们,都会听说过这个模型。这篇博客将详细地讲解XGBoost模型的原理,并且使用XGBoost库来实践。注意:在看XGBoost之前,请务必要读懂CART与GBDT,具体可参看我之前的文章:CART、GBDT。
XGBoost模型介绍
XGBoost模型是对GBDT很好地工程化的实现。所以,XGBoost模型也是加法模型,对于给定的样本$x_i$,我们使用XGBoost对其分数$\hat y_i$进行预测,可以表示为:
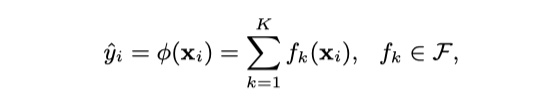
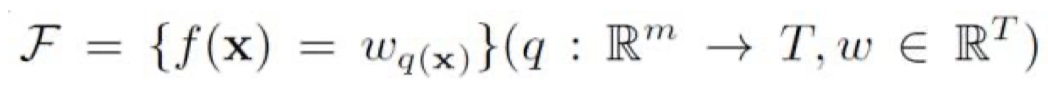
其中,$K$表示总共有$K$个决策树,$f_k$表示第$k$个决策树,在XGBoost中使用CART树;$\cal F$表示假设假设空间,即所有决策树的集合。那么,接下来,我们需要给出XGBoost模型的损失函数(严格来讲,叫做 cost function),以便求出所有的$f_k$。那么,如下:

其中,$\sum_{i}l(\hat y_i,y_i)$是损失函数,表示的是模型对于训练集的拟合程度,$\sum_k \Omega(f_k)$表示正则项,也叫做惩罚项,XGBoost中对每一个回归树进行惩罚,让模型的复杂度不过高,从而不会轻易过拟合。而衡量树的复杂度的指标有很多,譬如:树的深度、叶子结点的数目、内部节点数目等等。在XGBoost中,采用了叶子结点的数目来衡量树的复杂度。其中,$T$表示的是叶子结点的数目,$w$表示的是叶子结点的分数,也就是回归树预测的值。实际上,这个正则化项也相当于剪枝了。
cost function的推导
接下来,重点来了,我们需要对损失函数这一块进行泰勒展开!怎么做呢?始终要记住一句话:XGBoost模型是对GBDT模型很好地工程化的实现。所以,XGBoost模型仍然是前向分步算法。我们需要对损失函数进行二阶泰勒展开。如下:

所以,通过泰勒展开和化简,我们得到最优的cost function如下:
所以,从上式可以看出,只要我们确定了回归树的结构,那么我们就能得到最小的损失。那么,怎么去确定回归树的结构呢?
确定回归树的结构
关于回归树的学习,一个很直接的想法,就是遍历所有特征的所有切分点,找到最佳切分变量与切分点,从而确定回归树的结构。那么,关键是:我们使用什么样的评价准则来评判切分的质量好坏?在XGBoost中,我们使用如下式子来评判分裂的好坏:
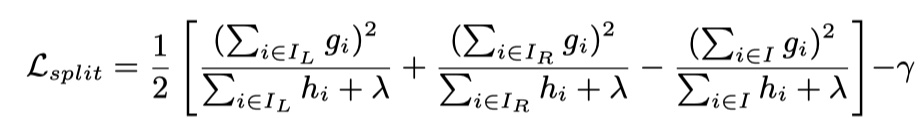
当$\cal L_{split}$越大,那么说明叶子结点分裂的质量越好,最终的损失函数的值也会越小。所以,我们就可以依次所有特征的所有切分点,从中找到最大的$\cal L_{split}$的切分点和所对应的值。这种方法叫做:精确贪心算法。

但是,这种分裂算法,在特征数目以及其对应的取值太多的时候,效率会非常的慢,所以,在XGBoost中,还提出的近似贪心算法。核心思想是:我们不需要依次遍历所有特征值的所有切分点,我们只需要找到并遍历有可能的切分点,从中找到$\cal L_{split}$的值最大的切分变量与切分点就可以了。

不过,在近似算法中,需要注意的是,我们并不是根据样本数目来进行分位,而是以每一个样本的二阶导数作为权重,以此排序,来进行分位。那么,为什么可以采用二阶导数来做权重呢?推导如下(参看链接:xgboost):

稀疏值的处理
稀疏值有三种:大量的0值、大量的类别one-hot编码、缺失值。XGBoost可以自动学习出稀疏值的节点分裂方向。如下:

- 首先需要注意到输入的两个集合:一个是$I$,其包含所有的样本(包括含空缺值的样本);另一个是$I_k$,是不包含空缺值样本的集合。在计算总的$G$和$H$的时候,用的是$I$。
- 此外,可以看到内层循环里面有两个for。第一个for是从把特征取值从小到大排序。这个时候,在计算$G_R$的时候,是用总的$G$减去$G_L$,计算$H_R$也是使用$H$减去$H_L$。这就相当于将稀疏值归到了右节点。
- 第二个for是从把特征取值从大到小排序。这个时候,在计算$G_L$ 的时候,是用总的$G$减去$G_R$,计算$H_L$也是使用$H$减去$H_R$。这就相当于将稀疏值归到了左节点。
- 我们只要比较最大的增益出现在第一个for,还是第二个for,我们就能知道稀疏值的分裂方向是在左还是右。这就是XGBoost模型处理稀疏值的方法。
two tricks
在XGBoost模型中,除了通过添加正则化项来防止过拟合之外,还用了另外两个用来防止过拟合的trick:shrinkage(缩减)、column subsampling(列抽样)。我们一一介绍。shrinkage。所谓的shrinkage,就是将学习速率减小,增加迭代次数,从而起到正则化的作用。column subsampling。这个和RF中是一样的,没什么可说的。除此之外,XGBoost模型还有一些工程化的东西,像cache的设计等等。这些感兴趣的筒子们,可以去看原始paper🎉~
XGBoost模型实战
当然了,我们并不会从头去去实现一个XGBoost模型,那样十分复杂,而且个人觉得意义不是很大哈。感兴趣的通知可以去直接去阅读源码细节,这样反而更好些🎉在这里,我将使用xgb库来对XGBoost模型进行实践。(夜深了,明天写吧🥱)
附上代码👇不过说实话,XGBoost的参数真的多😣。
1 | # coding:utf-8 |
参考文献
1 《XGBoost: A Scalable Tree Boosting System》

