AdaBoost模型是提升方法的代表,对于之后理解XGBoost等集成学习模型很有帮助。但是,在学习AdaBoost模型之前,请务必要先搞懂回归树(CART),因为当AdaBoost的基本分类器是回归树时,需要用到回归树。本篇博客将详细讲解AdaBoost模型的原理,并会讲解梯度提升树模型(GBDT),并采用python与scikit-learn对其进行实现。
AdaBoost模型介绍
AdaBoost模型是典型的提升方法。那么何谓提升(boosting)方法呢?当我们很难一次性找到一个效果很好的模型的时候,我们可以先找到一些效果不那么好的模型,我们称为弱学习算法,然后将这些弱学习算法通过某种组合,将其提升(boost)为强学习算法,这就是提升方法的思想。那么,AdaBoost模型就是典型的应用于分类问题的提升算法。AdaBoost模型的做法是:从弱学习算法中学习一系列弱分类器,然后通过某种组合,从而得到最终的强分类器。那么,问题来了:AdaBoost模型是怎么得到一系列弱分类器的呢?在提升方法中,一般都是通过调整训练数据集的概率分布,通过不同的训练集分布来得到一系列的弱分类器。那么,问题又来了:AdaBoost模型是怎么改变训练集的概率分布的呢?AdaBoost模型又是怎么将一系列弱分类器组合成强分类器的呢?
- 对于第一个问题:AdaBoost模型提高在上一轮被错误分类的实例的权重,降低被正确分类的实例的权重,这样一来,在下一轮的学习中,被错误分类的实例将得到更大的关注,从而有更大概率被正确分类。
- 对于第二个问题:AdaBoost模型采取加权表决的做法。给予那些分类准确率高的弱分类器更大的权重,而对于分类准确率低的弱分类器更小的权重,这也是很合理的。
那么介绍完AdaBoost模型的基本思想之后,下面我将给出AdaBoost模型的具体公式细节:
输入:训练数据集$X=\{(x_1,y_1),(x_2,y_2,…,x_N,y_N)\}$,其中$x_i\in R^n$,$y_i\in \{-1,+1\}$;弱学习算法;
输出:分类器$G(x)$。
(1) 初始化训练数据集的权值分布$D_1$,实际上是均匀分布。即:$D_1=\{w_{11},w_{12},w_{13},…,w_{1N}\}$,其中$w_{1i}=\frac 1N$。
(2) 对于$m=1,2,3,…,M$,执行以下操作:
(a) 根据带有权值分布的训练数据集,学习弱分类器:
(b) 计算训练数据集的分类误差率:
(c) 计算该分类器的权重:
(d) 更新训练数据集的权值分布:
(3) 构建基本分类器的线性组合:
(4) 得到最终的分类器:
AdaBoost模型的另一种表述形式
AdaBoost模型还有另外一种解释:AdaBoost模型是模型为加法模型、损失函数为指数函数、学习算法是前向分步算法的二类分类模型。
加法模型。加法模型的形式如下:
其中,$\beta$是系数,$b(x,\gamma_m)$是基本分类器,$\gamma$是其参数。所以我们要学习的参数就是$\beta_m,\gamma_m$。
损失函数。当给定损失函数$L(y,f(x))=exp(-yf(x))$之后,整个求解问题变成如下:
但是,一次性要求解M个基分类器的参数与系数,是非常困难的。所以我们需要采用前向分步算法来进行求解。
前向分步算法。所谓的前向分步算法,就是我们一次只求解一个基分类器的参数与系数,从而能够大大简化运算。如下:
所以,整个AdaBoost模型如下:
输入:给定训练集与损失函数以及基本分类器集合。
输出:最终的模型$f(x)$。
(1) 初始化$f_0(x)=0$。
(2) 对$m=1,2,…,M$,有
(a) 极小化损失函数
得到参数$\beta_m, \gamma_m$。
(b) 更新模型
(3) 得到最终的模型
GBDT
提升树模型是以分类树或者回归树为基本分类器的提升方法。它也是使用加法模型以及前向分步算法来进行求解模型的。当对于二类分类问题的时候,其等价于AdaBoost模型,这里就不说了。这里,着重讲一下关于应用于回归问题的提升树模型。
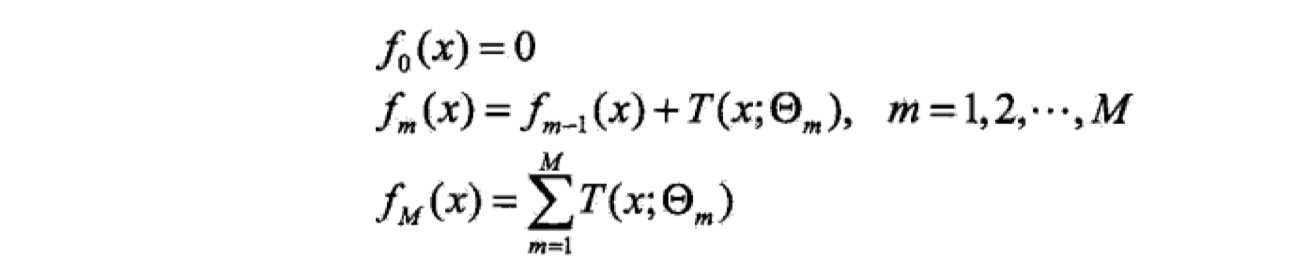
在回归问题中,损失函数常使用均方误差MSE。如下:
再化简一下:
我们记$y-f_{m-1}(x)$为残差$r$,也就是说,我们要使损失函数最小,只要让当前模型去拟合数据的残差即可。

最后,我们可以得到回归树:$f_M(x)=\sum_{m=1}^{M}T(x,\theta_m)$。计算的例子可以参考这里:GBDT的计算示例
对于损失函数为指数函数或者是MSE,其实学习回归树是很容易的。但是当损失函数是一般的损失函数的时候,计算往往就会变得很复杂。在这里,我们给出一个大致的框架,而之后要讲的XGBoost/Light GBM/catBoost等树模型就是对GBDT的很好地工程化的实现。

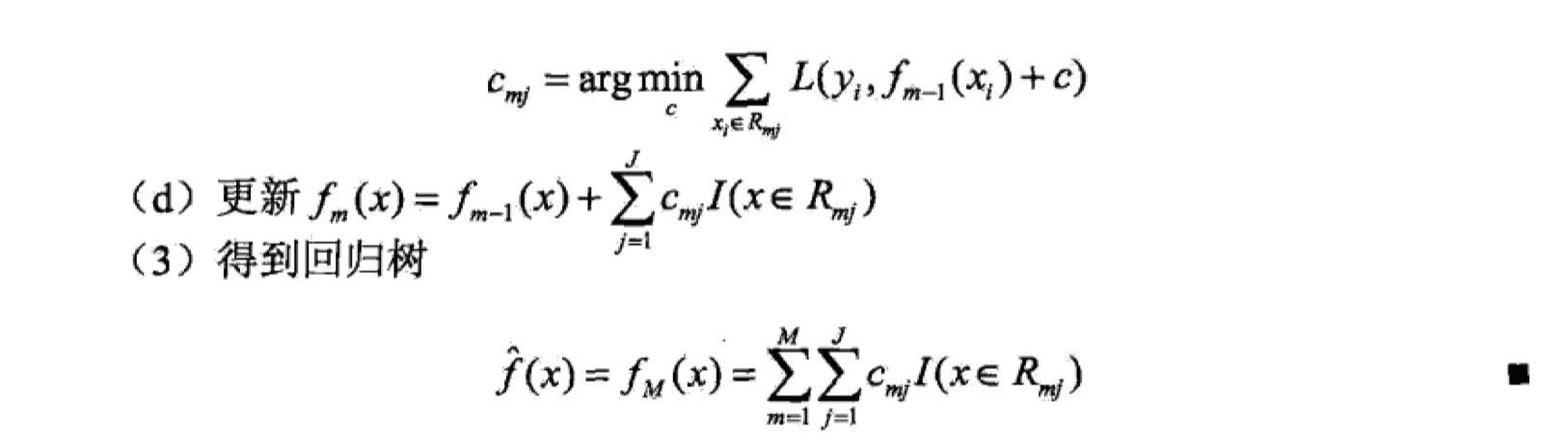
理论部分就讲到这里🎉
AdaBoost模型的实现
把模型实现一遍才算是真正的吃透了这个模型呀。在这里,我采取了两种方式来实现AdaBoost模型:python实现以及调用scikit-learn库来实现。我的github里面可以下载到所有的代码,欢迎访问我的github,也欢迎大家star和fork。附上GitHub地址: 《统计学习方法》及常规机器学习模型实现。具体代码如下:
python实现
scikit-learn实现
参考资料
1 《统计学习方法》

