这篇博客主要是介绍一下我最近开源的python库——DeepClassifier,用于文本分类,目前已经集成了较多的文本分类模型,欢迎大家去安装、star以及fork~🥳
动机
首先谈谈我为什么要开发这个库。有两个原因吧~第一,我自身是做NLP这块的,相信做NLP的小伙伴们都知道,文本分类是NLP中最基础并且是最广泛的任务。同时这也是我们入门NLP的尝试的第一个任务。虽然目前已有的文本分类模型都相对简单,但是实现起来用有点费时间,尤其是在打比赛的时候,很耗费时间。而目前市面上并没有这样用于文本分类的库,所以我就希望能够将经典的文本分类模型以及一些常用的模型组合进行实现,将其非常成一个库,那么我就只需要调用这些实现好的模型,而不用再次花时间与精力去复现模型;第二,作为一个程序员,总是希望自己的成果能够被别人看到,所以就索性将这些封装好的模型做成了python库,并进行了开源,也是希望能够帮助更多的人,让世界变得更加美好一些吧(这是我作为一个程序员的信仰吧,相信能够改变世界hhh)~🥳
介绍
地址:https://github.com/codewithzichao/DeepClassifier
地址:欢迎进入DeepClassifier
DeepClassifier是一个易用的文本分类库,基于pytorch进行二次开发。对于DeepClasifier,我不希望封装的太过于高级,那样会让人感到不舒服,所以我主要封装了模型部分以及训练/测试/预测 部分的代码。如果你希望自己写训练/测试/预测 部分,也是可以重写的,各个模块之间是低耦合的,所以非常灵活。
欢迎大家安装、star以及fork!🥳
安装
DeepClassifier的安装与其他的python库是一样的,都可以通过pip来进行安装,安装命令如下:1
pip install -U deepclassifier
已支持模型列表
| model | source |
|---|---|
| TextCNN | Convolutional Neural Networks for Sentence Classification ,2014 EMNLP |
| RCNN | Recurrent Convolutional Neural Networks for Text Classification,2015,IJCAI |
| DPCNN | Deep Pyramid Convolutional Neural Networks for Text Categorization ,2017,ACL |
| HAN | Hierarchical Attention Networks for Document Classification, 2016,ACL |
| BERT | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,2018, ACL |
| BertTextCNN | BERT+TextCNN |
| BertRCNN | BERT+RCNN |
| BertDPCNN | BERT+DPCNN |
| BertHAN | BERT+HAN |
| coming soon | …… |
未来将会支持更多的文本分类模型,请持续关注~喜欢的同学可以安装、star以及fork呀~
快速使用
安装之后,怎么使用呢?非常简单!下面我将展示怎么使用DeepClassifier去完成你的项目~🥳
数据集
Kaggle dataset: sentiment-analysis-on-movie-reviews
Pretrained embedding: GloVe download
BERT pretrained weights: download
数据探索
这是一个5分类的文本分类问题,我们首先可以来看看训练集、验证集、测试集的样本长度以及训练集、验证集的标签分布情况~如下:
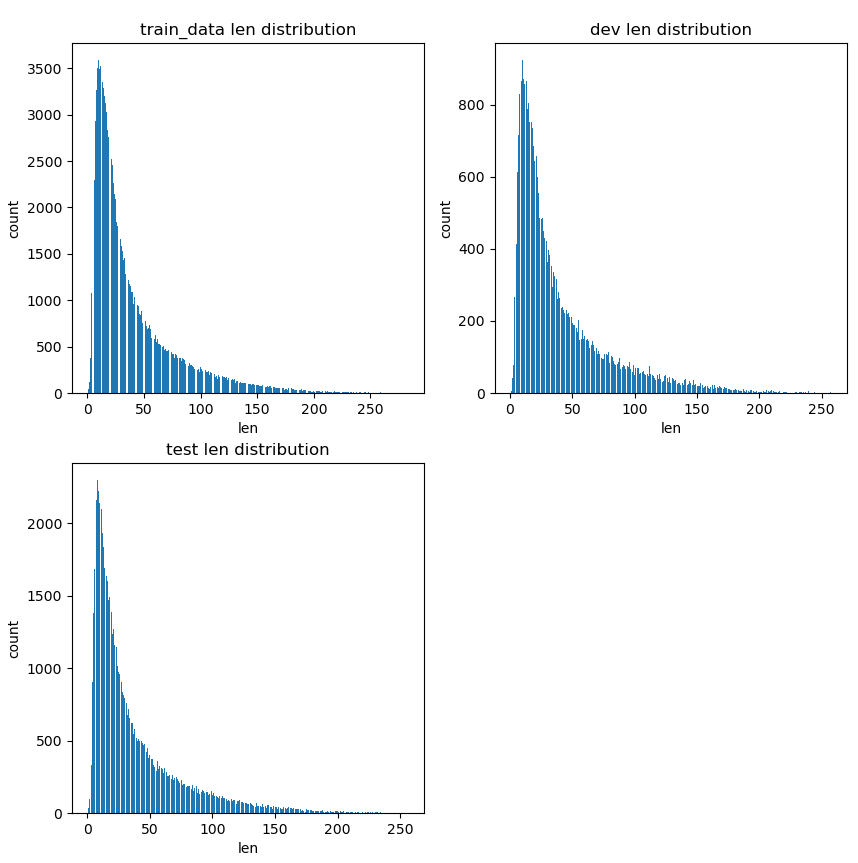
这是训练集/验证集/测试集的样本长度分布情况,可以看到三者的样本长度分布情况大体一致,并且多数集中在0~150之间。下面来看一下训练集/验证集的标签分布情况:
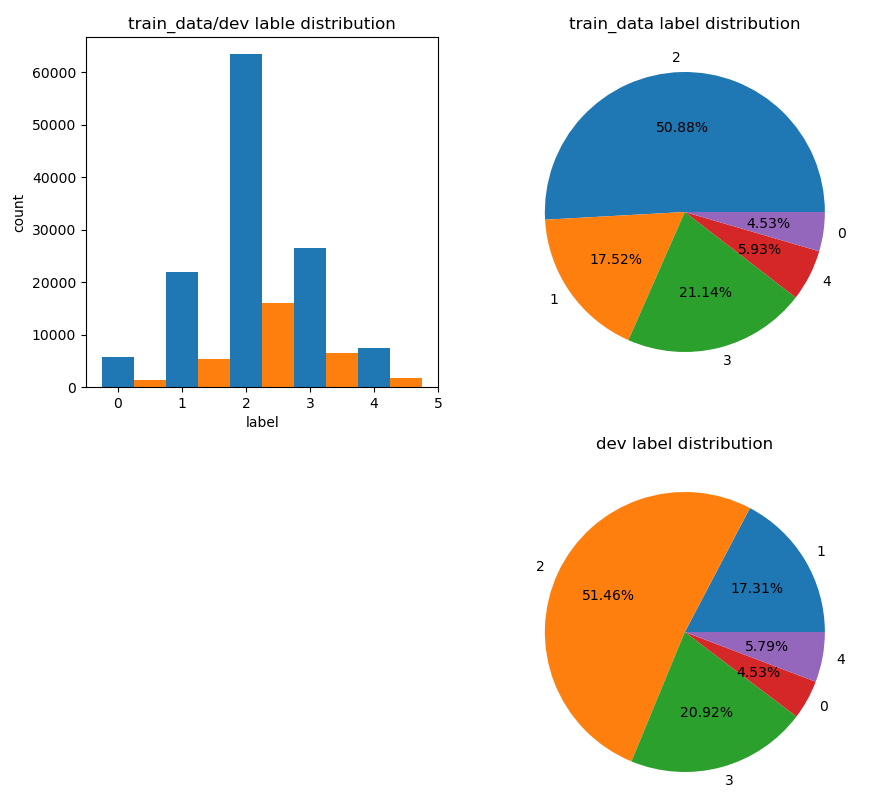
我们可以看到label为2的标签是最多的,并且最多的标签与最少的标签差距很大,所以可能存在类别不均衡的问题,在进行模型训练的时候,就需要做一些处理。在这里,为了方便,我就不处理了~
数据处理
NLP中的数据处理主要是:1.对样本进行分词;2.根据词汇表来使样本向量化;3.对 data进行padding,以便能够batch 运行,最终输入到模型中的输入的维度是:[batch_size,seq_length]。除此之外,由于我们使用了预训练好的词向量,所以我们需要加载词向量,具体的代码请见
DeepClassifier/examples/preprocessing.py,核心代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def load_pretrained_embedding(pretrained_embedding_file_path):
'''
# 加载预训练的词向量,这里使用GloVe
:param pretrained_embedding_file_path: 预训练词向量文件存放的路径
:return:
'''
embedding_matrix = []
word2idx = dict()
word2idx["__PAD__"] = 0
word2idx["__UNK__"] = 1
index = 2
with codecs.open(pretrained_embedding_file_path, "r", encoding="utf-8") as f:
temp = f.readline().strip().split(" ")
embedding_dim = len(temp) - 1
embedding_matrix.append(np.zeros(shape=(embedding_dim,)))
embedding_matrix.append(np.random.randn(embedding_dim))
f.seek(0)
for line in f:
line = line.strip().split(" ")
word, emd = line[0], line[1:]
emd = [float(x) for x in emd]
word2idx[word] = index
index += 1
embedding_matrix.append(np.array(emd))
assert word2idx.__len__() == embedding_matrix.__len__()
embedding_matrix = torch.from_numpy(np.array(embedding_matrix)).float()
return word2idx, embedding_matrix
训练
在这里,我将展示使用TextCNN以及BertTextCNN两种模型,代码如下:
TextCNN
详细的代码请见DeepClassifier/examples/example_textcnn.py,核心代码部分如下:
1 | # 训练集 |
BertTextCNN
详细的代码请见DeepClassifier/examples/example_berttextcnn.py,核心代码部分如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# 训练集
batch_size = 20
my_train_data = my_dataset(train_data, train_label, 200, tokenizer)
train_loader = DataLoader(my_train_data, batch_size=batch_size, shuffle=True, drop_last=True)
# 验证集
my_dev_data = my_dataset(dev_data, dev_label, 200, tokenizer)
dev_loader = DataLoader(my_dev_data, batch_size=batch_size, shuffle=True, drop_last=True)
# 测试集
pred_data = my_dataset1(test_data, 200, tokenizer)
pred_data = DataLoader(pred_data, batch_size=1)
# 定义模型
my_model = BertTextCNN(embedding_dim=768, dropout_rate=0.2, num_class=5,
bert_path="/Users/codewithzichao/Desktop/开源的库/bert-base-uncased/")
optimizer = optim.Adam(my_model.parameters())
loss_fn = nn.CrossEntropyLoss()
save_path = "best.ckpt"
writer = SummaryWriter("logfie/1")
my_trainer = Trainer(model_name="berttextcnn", model=my_model,
train_loader=train_loader, dev_loader=dev_loader,
test_loader=None, optimizer=optimizer,
loss_fn=loss_fn, save_path=save_path,
epochs=100,writer=writer, max_norm=0.25,
eval_step_interval=10, device='cpu')
# 训练
my_trainer.train()
# 打印在验证集上最好的f1值
print(my_trainer.best_f1)
# 测试
p, r, f1 = my_trainer.test()
print(p, r, f1)
# 预测
pred_label = my_trainer.predict(pred_data)
print(pred_label.shape)
到此为止,你就完成了你的文本分类任务啦~

