这篇博客主要讲解图神经网络在sentence-level的关系抽取任务中的应用,共讲解三篇paper:《Graph Neural Networks with Generated Parameters for Relation Extraction》、《GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction》、《A General Framework for Information Extraction using Dynamic Span Graphs》。
Graph Neural Networks with Generated Parameters for Relation Extraction(ACL2019)
background
图神经网络在图关系推理中的效果非常强大,但是目前以后的GNN只能在预定义好的图上进行,无法直接在非结构化的文本中直接应用。所以在这篇paper中,就是采用 spectral GCN来进行aggegate。但是要使用GCN的话,有这么几个条件:1.最好是无向图,如果是有向图的话,则需要再根据问题进行调整,很麻烦,一般是要求无向图;2.边的类型必须一样,也就是同质图。所以问题就在于:怎么去构建一个无向图?怎么得到邻接矩阵?这就是GPGNN所要解决的问题。
model
先放图~
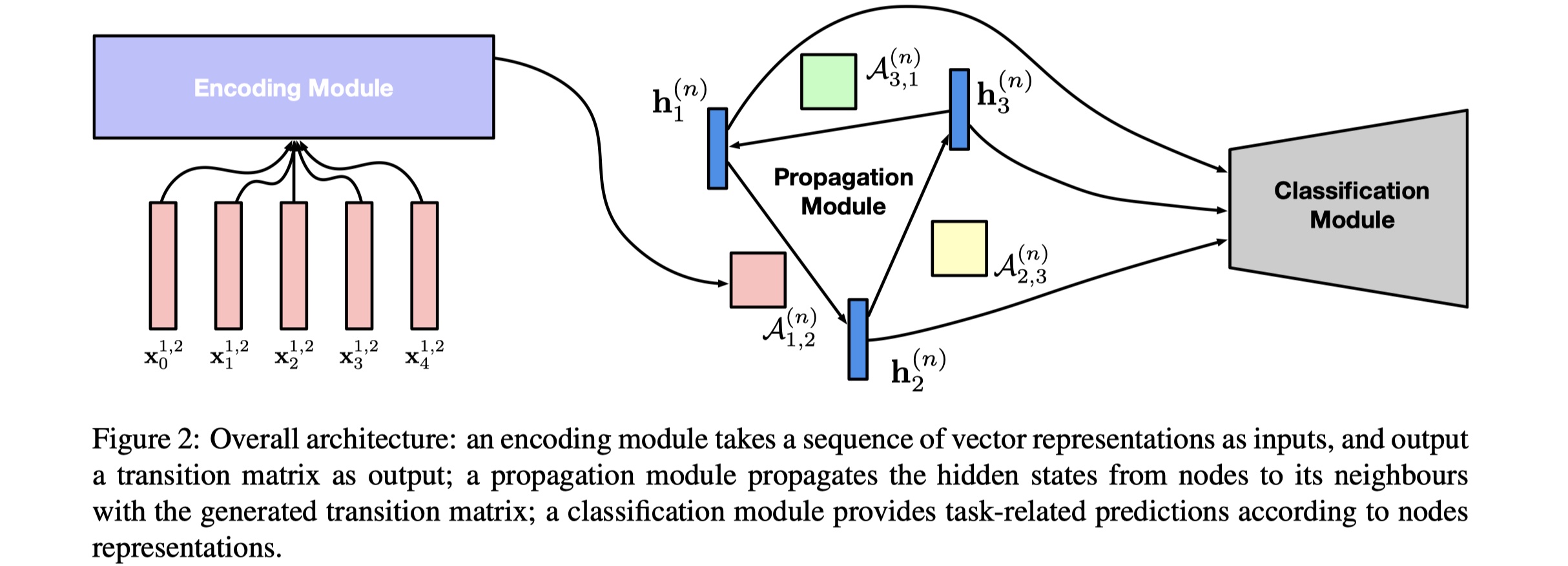
整体模型架构分为三部分:encoding module、propagation module、classification module。
task definition:给定一个sentence:$s=(x_0,x_1,…,x_{l-1})$,relation的集合:$\cal R$,以及sentence中的entites:${\cal V}=\{v_1,v_2,…,v_{|\cal V|}\}$,其中$v_i$由单个或者多个token构成。我们要做的是:对每一个entity pair $(v_i,v_j)$,我们去得出它的rleation $r_{v_i,v_j}$。
encoding module:首先根据text来构建全连接的GNN:$\cal G=(V,E)$,所有的entity就是node。然后我们对entity pair进行encoding,得到邻接矩阵。具体如下:
其中,$x_t$表示word $x_t$的word embedding(采用GloVe),$p_t^{i,j}$表示word $x_t$相对于entity pair $(v_i,v_j)$的position embedding(sentnece中的每一个token要么属于entity $v_i$,要么属于entity $v_j$,要么都不属于),我们这两者进行concat,得出的$E(x_t^{i,j})$表示相对于entity pair $(v_i,v_j)$的word $x_t$的embedding;$A_{i,j}^{(n)}$表示的是第$n$层的entity pair $v_i,v_j$的边的参数,从本质上来说,就是邻接矩阵。
propagation module:这一部分就是传统的aggregate。从第$n$层更新到第$n+1$层的公式如下:
其中,$\sigma$表示某一种激活函数。但是这里有一个疑问:$h^{(0)}_i$怎么得到的?论文里的没看懂。。。
classification module:concat所有layer的$v_i$与$v_j$的表示,然后使用softmax,如下:
最终的loss使用CE loss,如下:
GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction(ACL2019)
background
model
experiment
A General Framework for Information Extraction using Dynamic Span Graphs(NAACL2019)
background
model
experiment
references
《Graph Neural Networks with Generated Parameters for Relation Extraction》
《GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction》
《A General Framework for Information Extraction using Dynamic Span Graphs》

