接着上一篇博客,这篇博客也是讲解图神经网络在Document-level关系抽取上的应用,共讲解4篇论文:《Global-to-Local Neural Networks for Document-Level Relation Extraction》、《HIN: Hierarchical Inference Network for Document-Level Relation Extraction》、《Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling》、《Entity and Evidence Guided Relation Extraction for DocRED》。
Global-to-Local Neural Networks for Document-Level Relation Extraction(EMNLP2020)
Background
这篇文章的核心思想是:通过从粗粒度、细粒度、context information的角度对entity之间的relation进行建模。具体解决的问题是:第一:怎么对document中的复杂语义进行建模?(使用BERT);第二:怎么学习有效地entity representation?(使用RGCN);第三:其他的relation也对于当前目标entity之间的relation产生影响,如果有效的利用?(context-aware)。将这三个方面聚合起来,就是GLRE模型。
目前在doucment-level RE中,存在着三方面的问题:logical reasoning、coreference reasoning、common-sense reasoning。
Model
先放图~
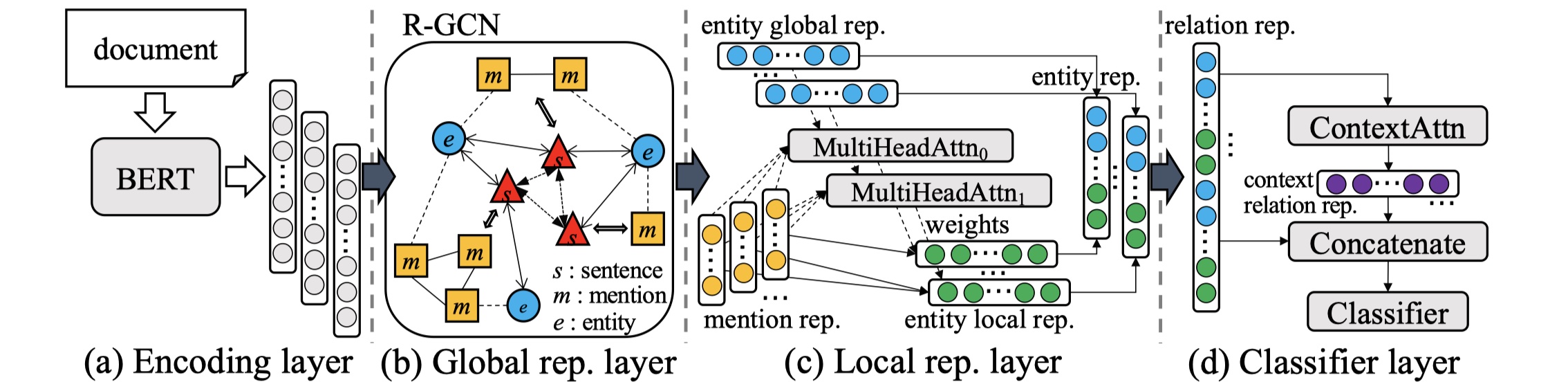
GLRE模型分为四部分:encoding layer、global representation layer、local representation、classifier layer。
encoding layer:假设输入的document表示为:$\cal D=\{w_1,w_2,…,w_k\}$,其中$w_i$表示的是第$i$个word,我们使用BERT来对其进行编码,如下:
$H$是BERT最后一层的输出。
global representation layer:GLRE模型同样是基于graph的模型。同样是继承EoG模型,其中有三种node:mention node、entity node与sentence node。对于三种node的表示,我们都是将其本身的avg embedding与各自的type embedding进行conat。具体来说,对于mention node:$n_{m_i}=[avg_{w_j\in m_i}(h_j);t_m]$;对于entity node:$n_{e_i}=[avg_{m_j\in e_i}(n_{m_j});t_{e}]$;对于sentence node:$n_{s_i}=[avg_{h_j\in s_i}(h_j);t_s]$。有五种edge:mention-mention edge(同一个sentence中的所有mentions之间加一条边)、mention-entity edge(entity与其mention之间加一条边)、mention-sentence edge(如果mention node与sentence node加一条边)、entity-sentence edge(如果一个entity至少有一个mention出现在sentence中,那么entity node与sentence之间加一条边)、sentence-sentence edge(所有的sentence node之间加一条边)。⚠️和EoG模型一样,同样没有entity-entity edge!构建好graph之后,在GLRE模型中,stack了L层的R-GCN,具体的aggregate的公式如下:
其中,$\cal N_{x}^{i}$表示在$x$这种edge type下,node i的邻接节点的集合,说到底,还是和GCN处理异质图的方式没啥区别。我们将L层之后的每一个node的representation称为entity global representation,记做:$e^{glo}_{i}$。
local representation layer:如果说global rep layer是想在document-level上对不同的entity之间的语义信息进行建模,那么local rep layer是在对同一个entity的不同的mention之间的信息进行建模,从而得到更加好的entity rep,因为在不同的entity pair中,entity的表示肯定是不同的,如果只用global rep layer的结果的话,那么entity的表示就是唯一的了,肯定对最后结果会有影响。怎么做呢?在GLRE中,采用的是multi-head self attention。对于entity pair $(e_a,e_b)$,公式如下:
其中,$\cal S_a$表示的是entity a 的mentions所在的sentence的集合,$\cal M_a$表示的是enity a的mention的集合。
classifier layer:得到$e^{glo}$与$e^{loc}$之后,我们将两者聚合。对于entity pair $(e_a,e_b)$,具体来说:
其中,$\delta_{ab}$表示的是entity a的第一个mention与entity b的相对距离。最后的表示是:$o_r=[\tilde e_a;\tilde e_b]$。为了进一步挖掘信息,paper中说的是document的topic information能够暗含某些relation,所以再一次使用self-attention(与transformer不同,名字叫做context-aware),如下:
然后将$o_c$输入到一个FFN层进行分类,即:$y_r=sigmoid(FFN([o_r,;o_c]))$,最后的loss使用CE。
Experiment
数据集:CDR、DocRED
结果
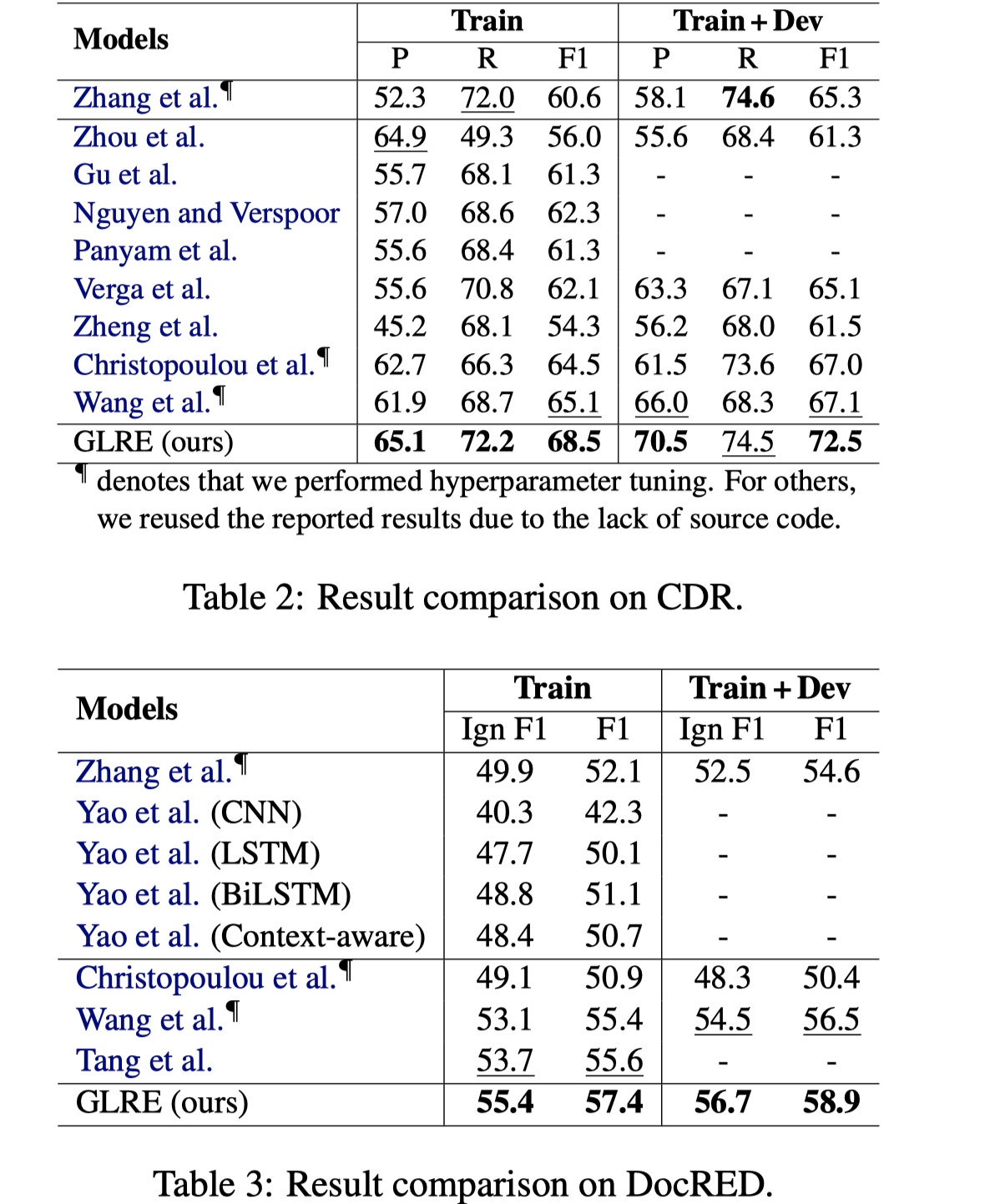
说实话,这个结果一般。但是这篇论文的ablation与error analysis很有意思。GLRE在长距离的entity pair的关系抽取上取得了比较好的结果(>=3),paper中给它归因于global rep layer的构建,同时local rep layer的构建减少了噪音。
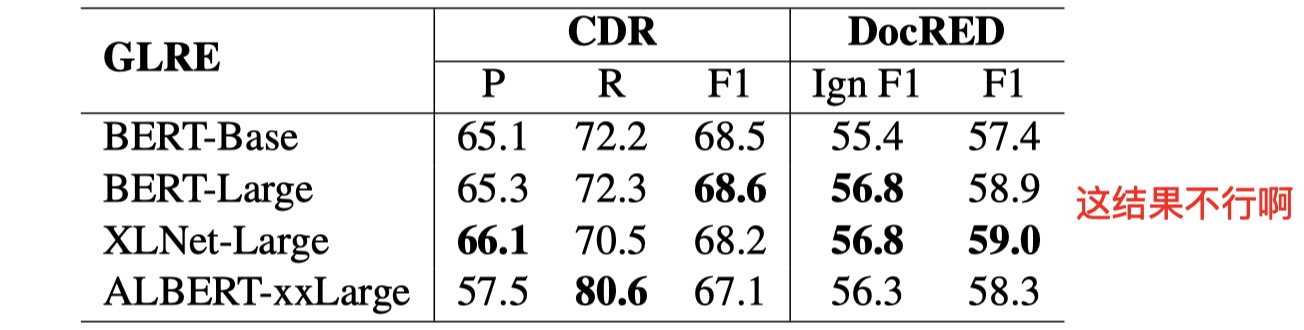
消融实验结论
BERT对于最终的结果影响很大,paper中做了几组实验,如下:
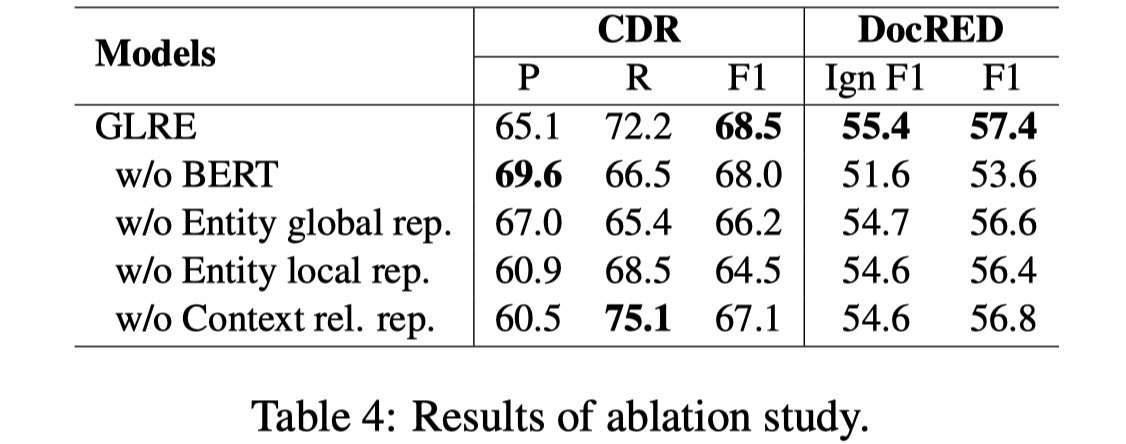
当local rep layer被移除之后,F1值下降很快,这说明multi-head self attention能够有选择性的aggregatemention rep,过滤掉一些噪音,看来不是所有的mention都有entity rep都有用,结果如下:
Case study
- Logical reasoning很重要,GLRE模型中,完全靠RGCN,没有另外再搞一套机制来结局logical reasoning;
- 当一个句子中,很多entity用
and这样的词连接的时候,往往模型无法对她们之间的关系进行建模,paper中说在GLRE模型中是靠context-aware来解决的,但是我觉得效果一般吧; - 怎么引入先验知识很重要,因为很多common sense不会出现在训练集里面,而很多relation的判断都需要用到先验知识,这个时候怎么做?GLRE也没有解决这个问题;
- 当一个句子的主语等部分缺失时,怎么处理?在GLRE中,是通过建立global rep layer来解决的,但是效果不是很好;
- 当代词有歧义的时候,怎么解决?
- paper统计了一下,logical reasoning(40.9%)、component missing error(28.8%)、prior knowledge missing error(13.6%)、coreference reasoning error?(12.9%)。
总的来说,GLRE模型一般,但是其case study与消融实验做的还是蛮好的,很有启发性。
HIN: Hierarchical Inference Network for Document-Level Relation Extraction(PAKDD2020)
Background
HIN模型还是蛮好懂的,它并不是从基于graph的方式上来解决document-level RE的,而是通过从entity-level、sentence-level、document-level这样层级的方式来做,有点类似于文本分类模型HAN。
Model
先放图~
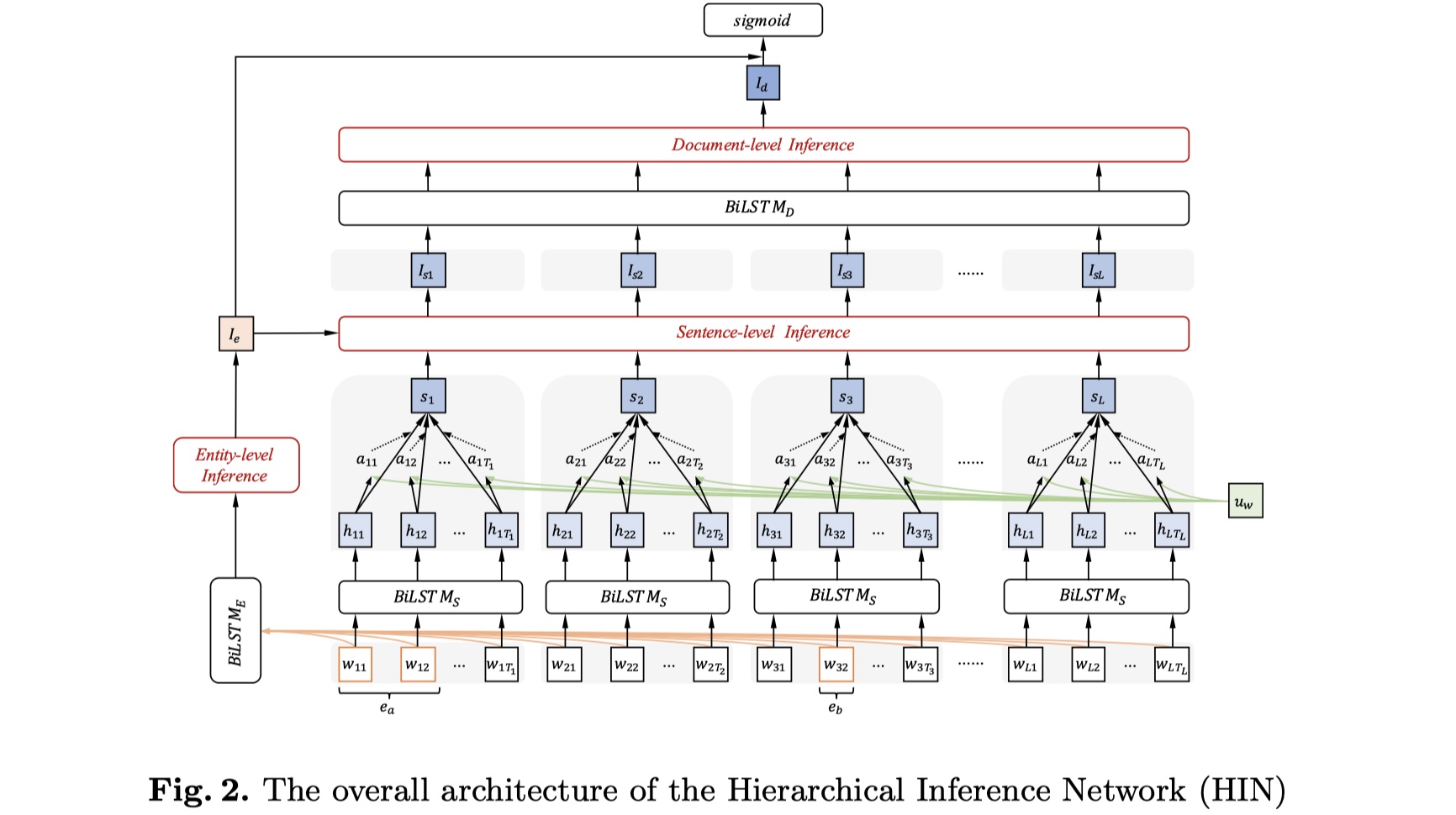
HIN模型分为四部分:input layer、entity-level inference module、hierarchical document-level inference module、prediction layer。
input layer:原始的输入有三部分:word embedding、entity type embedding、coreference embedding。其中,word embedding就是每一个token的word embedding,其维度:$d_w$;entity type embedding指的是将entity 的type信息转换为一个dense vector,其维度是:$d_t$;coreference embedding指的是同一个entity的不同的mention被分配同一个entity id,其维度:$d_c$。这一层的输出是这三者的concat。
entity-level inference module:首先使用BILSTM来对document进行编码,即:$h_i=BILSTM(w_i),i\in[1,n]$,$n$表示一个document中所有的token数目;每一个mention的rep是其每一个word的avg,每一个entity是其所有的mention rep的avg,即:$e_l=avg_{w_i\in e_l}(h_i), E_a=avg_{e_l\in E_a}(e_l)$,其中,$e_l$表示某一个mention的rep,$E_a$表示某一个entity的rep。由于收到multi-head attention的影响:将vector映射到不同的latent space会enrich 模型的信息,所以在HIN模型中,也是同样的做法,将得到的entity rep映射到不同的$K$个latent space,即:
之后,由于又收到TransE算法的影响,知:$e_h+e\approx e_t$,所以作者认为$E_b-E_a$能够在某种程度上反应entity pair $(e_a,e_b)$的relation。所以第k个latent space的结果是:
最终我们将k个latent space的结果进行concat,当然了,我们也加入相对距离进一步丰富信息,如下:
其中,$G_e$是FFN,$d_{ab}$是相对距离。
hierarchical document-level inference module:这一部分又分为两部分:sentence-level inference与document-level inference。在sentence-level inference中,假设一个document有$L$个句子,$w_{jt}$表示第$j$个sentence的第$t$个word,我们使用BILSTM对每一个sentence进行编码,如下:
然后借鉴HAN模型,对$h_{jt}$使用attention,然后得到sentence vector,如下:
其中,$S_j$就是第j个sentence的sentence vector。我们进一步将其与$I_e$进行融合,如下:
$S_{sj}$就是最终的第j个sentence的sentence vector。
在document-level inference中,我们还是借鉴HAN模型,使用BISLTM+attention的方式,得到最终document vector,如下:
$I_d$就是最终的document vector。
prediction layer:我们首先对entity-level inference rep与document-level inference rep进行concat,再输入到FFN中进行最终得分类。如下:
最终的loss采用CE。
Experiment
数据集:DocRED
结果
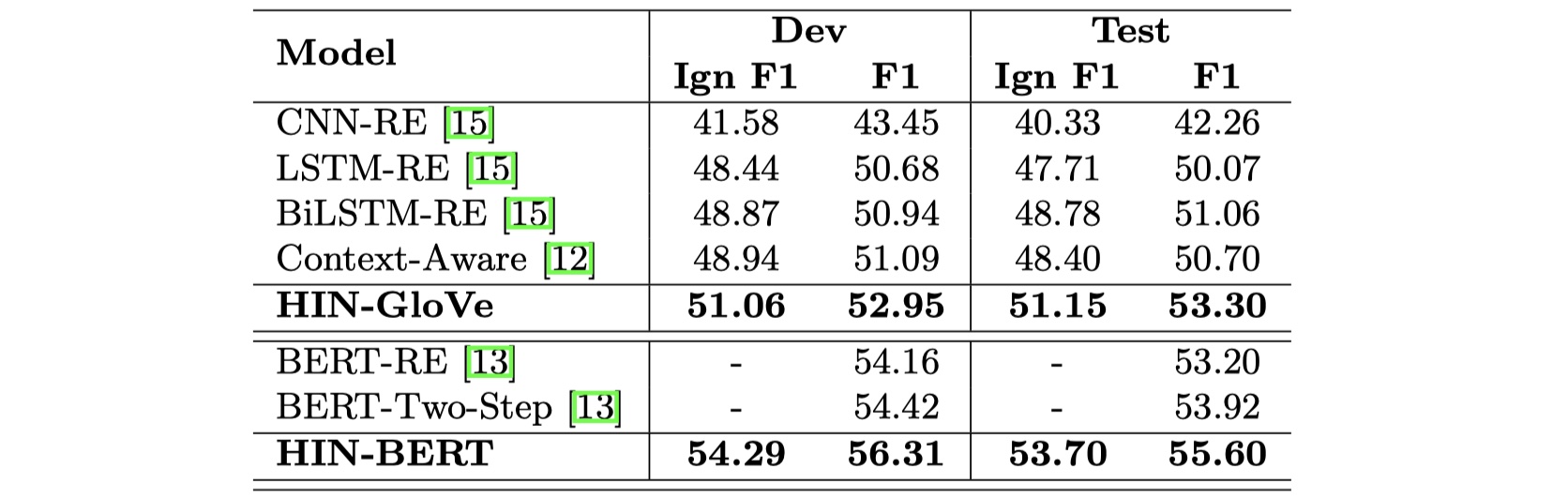
从结果看,更加一般了,而后在case study中所说明的logical reasoning、coreference reasoning、combine common-sense information问题也没有解决。
Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling(arxiv2020)
Background
这篇文章是JD放在arxiv上的文章,从结果来看是目前的top1,值得一读。它也是解决document-level RE。它的核心思想是:目前主流的做法是采用基于graph的方法来做,但是很多基于BERT的工作(譬如corefBERT)也能够得到很好的结果,并且在基于graph的模型的实验部分,也都证明了BERT以及BERT-like预训练模型的巨大提升,以至于让人怀疑是否有必要引入GNN?作者发现如果只用BERT的话,那么对于不同的entity pair,entity的rep都是一样的,这是一个很大的问题,那是否能够不引入graph的方式来解决这个问题呢?这就有了ATLOP模型。
说实话,这篇paper更多的是解决多标签分类问题,因为即便不是document-level RE,另外随便来个多标签分类,应该也可以得到很好的效果。
Model
ATLOP模型整体是基于BERT而不是graph来做的。所以我分两部分阐述:主体部分+改良部分。
backbone
task definition:给定document $d$以及一系列entity $\{e_i\}_{i=1}^{n}$,目标是得到entity pair $(e_s,e_o)$的relation $r$,$r\in {\cal R}\cup \{NA\}$。
encoder:给定document $d=[x_t]_{t=1}^l$,对于每一个可能的mention的开头与结尾,加入
*来进行标注,然后将sentence输入到BERT当中,得到contextual的rep。即:$[h_1,…,h_l]=BERT([x_1,…,x_l])$。mention embedding由mention首部的*rep来表示,entity rep是对其所有的mention的rep进行logexpsum得到的,即:$h_{e_i}=log\sum_{j=1}^{N_{e_i}}exp(h_{m_j^i})$,其中$m_j^i$表示entity $e_i$的第$j$个mention。binary classification:对于entity pair $(h_{e_s},h_{e_o})$,我们对其分别进行编码,并使用bilinear得到最终的结果,如下:
在ATLOP里,为了减少$W_r$的参数量,使用了group bilinear的技术,其实就是multi-head attention的思想,就是将$h_{e_s}与h_{e_o}$的维度分为k份,分别进行bilinear操作,最后对结果进行concat,再使用sigmoid得到结果。
improvement
adaptive thresholding
backbone中描述的就是不基于graph的基本操作,但是存在一个问题:我们使用sigmoid函数的时候,需要确定一个阈值(一般是0.5),当结果大于这个阈值的时候,我们给它positive label,当它小于这个阈值的时候,我们给它negative label。但是作者发现,对于DRE这样的多实体多标签问题,不同的entity pair的不同的realtion判断,应该是有不同的阈值才能够得到更好的结果。一般我们会手动去试不同的阈值在dev上的效果,选取F1值最好的阈值。但是人工选择仍然无法达到最优解(近似最优解),是否可以让模型自己来选择阈值呢?在ATLOP模型中,设计了adaptive thresholding机制来解决这个问题。
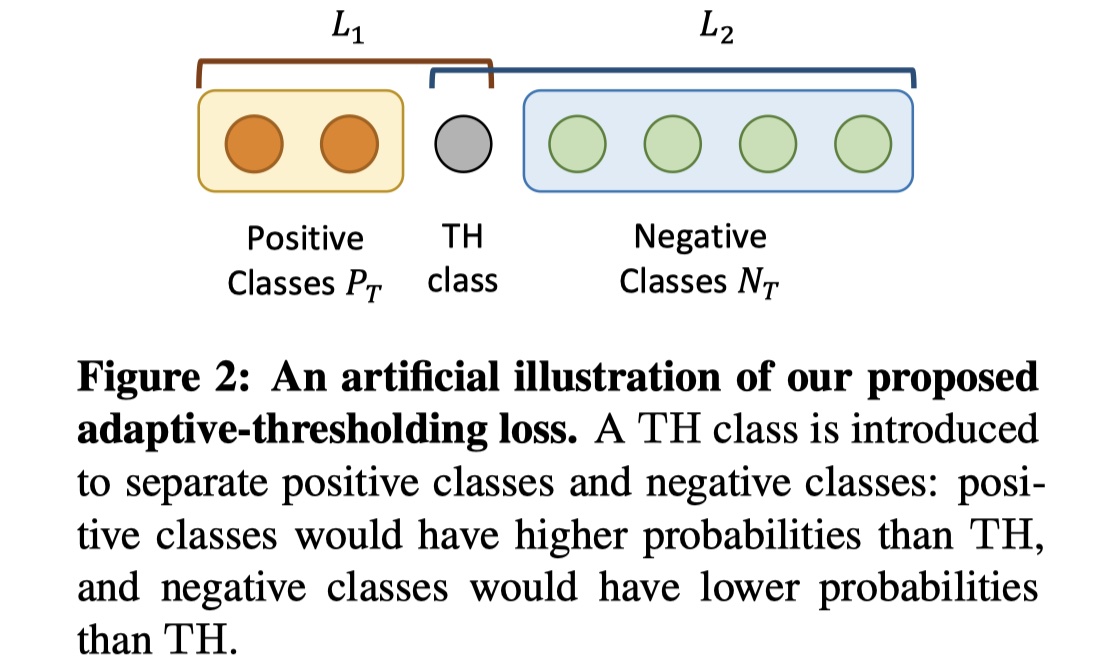
具体来说,对于给定的entity pair $T=(e_s,e_o)$,我们定义它的positive label set($\cal P_T$)与negative label set($\cal P_N$):前者是$T$有的relation,后者是$T$没有的realtion。我们追求的是:positive label的logits比negative label的要高,并且两者差距越大越好。因此,在ATLOP模型中,引入了TH这个class(THclass的概率计算仍然和计算普通的relation是一样的),在测试的时候,对于给定的entity pair,我们返回的relation class是比THclass的logits要高的class。具体的公式如下:
这里有个疑问,为什么不计算negative label的loss?🧐
localized context pooling
对于不同entity pair中的entity,其实最终用于分类的rep是一样的,而实际上,对于不同的entity pair,它所表达的信息却有可能完全不一样,并且在document中与之相关的信息的位置也是不一样的。为了解决这个问题,在ATLOP模型中,提出了LOP技术。
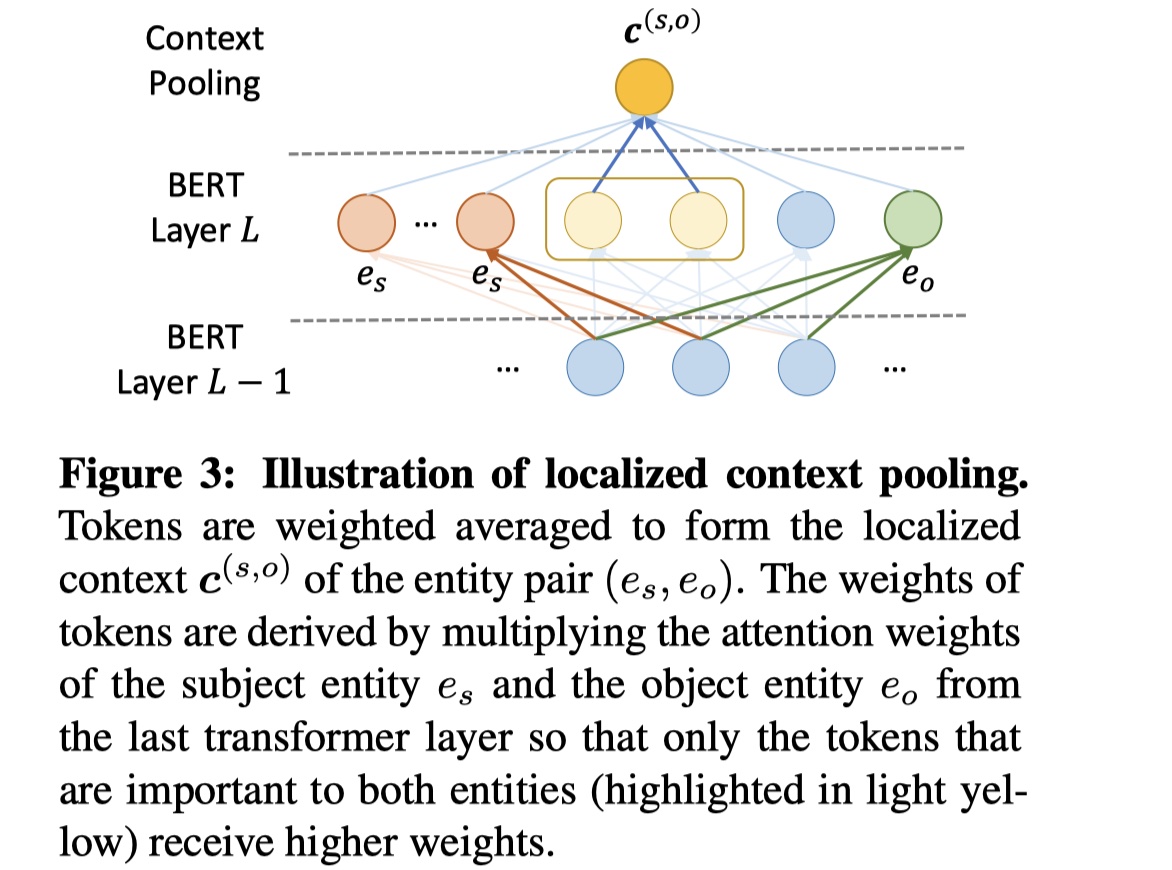
具体来说,LOP技术,就是使用BERT中最后一个transformer layer中的multi-head self attention,将其融入到最终每一个entity的rep中,从而在不同的entity pair中,每一个entity的rep能够聚合其最相关的信息,个人认为这是这篇paper中最出彩的地方。具体公式如下:
其中$A^E_s、A^E_o$是entity-level attention,然后我们将$c^{(s,o)}$与$h_{e_s}、h_{e_o}$相结合,如下:
接下来操作就是一样的了,直接送入sigmoid就行。
Experiment
数据集:CDR、GDA、DocRED
结果
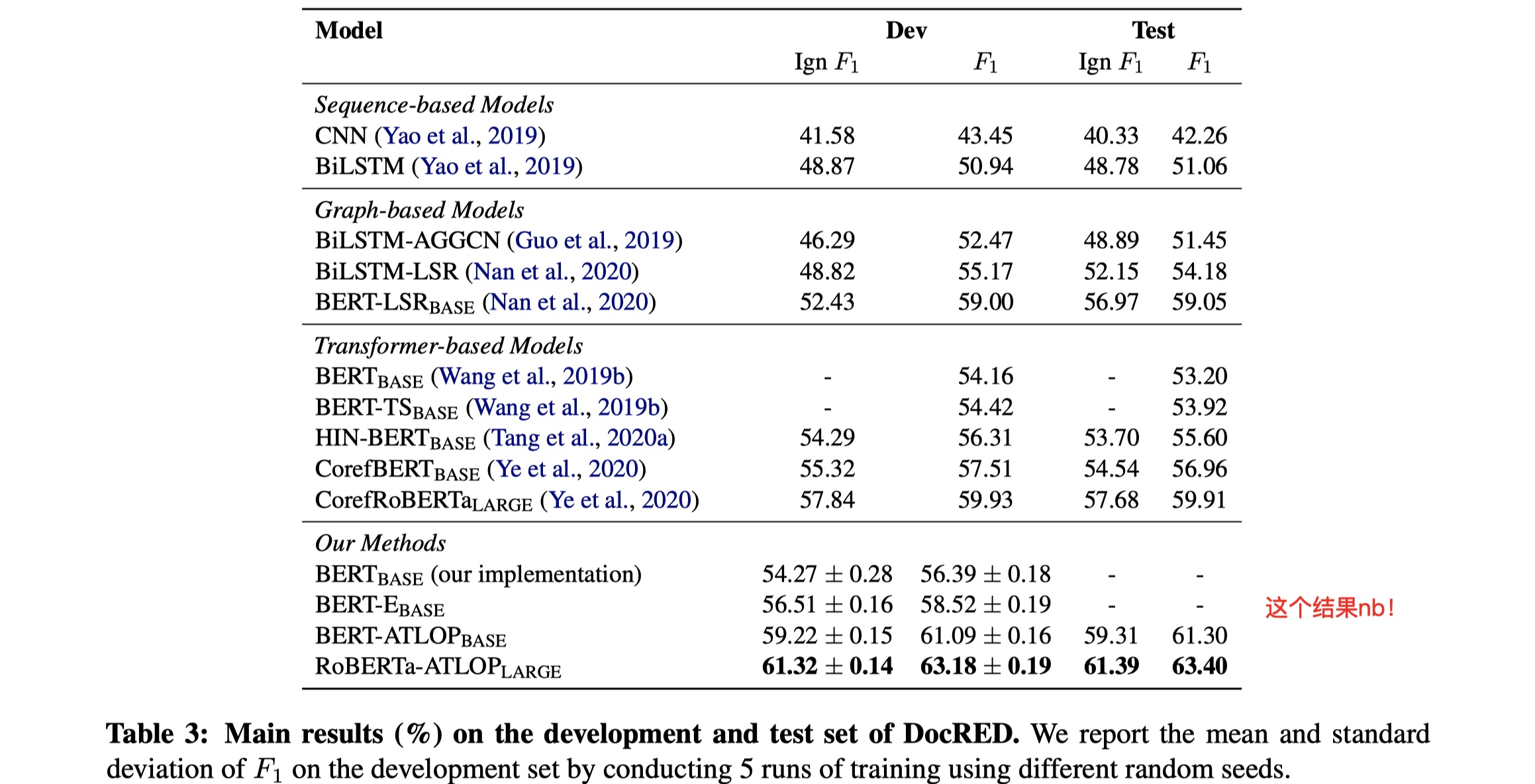
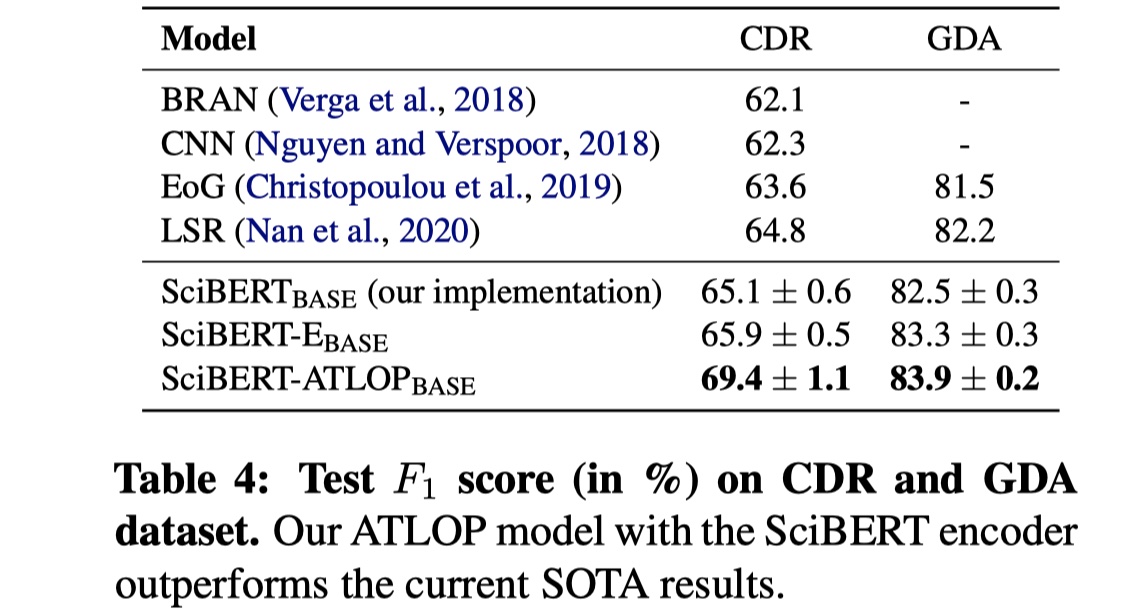
从结果上看,非常可以。
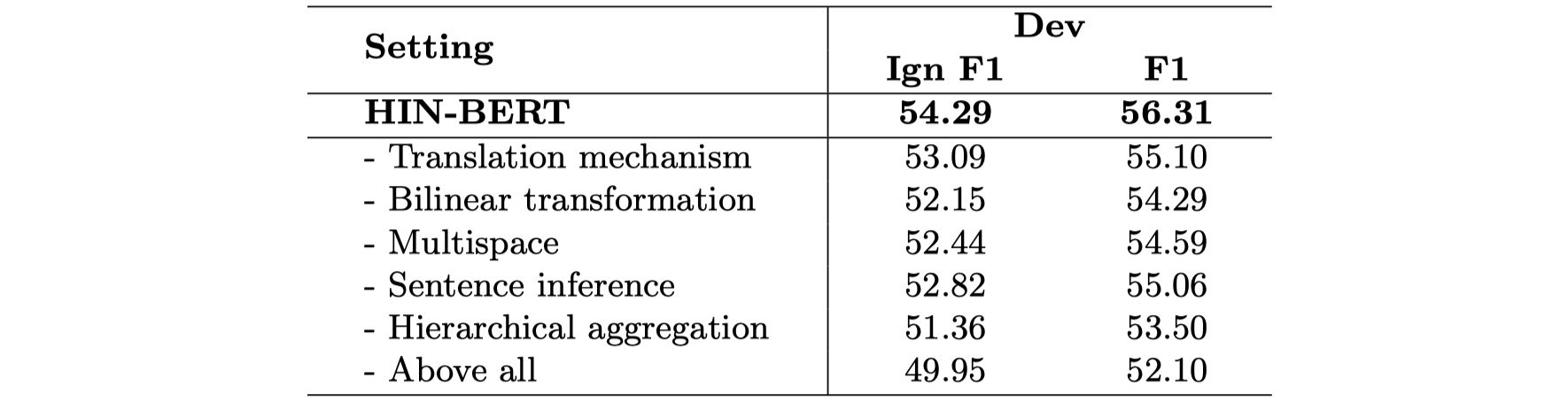
消融实验
作者对各个component中进行了消融实验(dev),如下
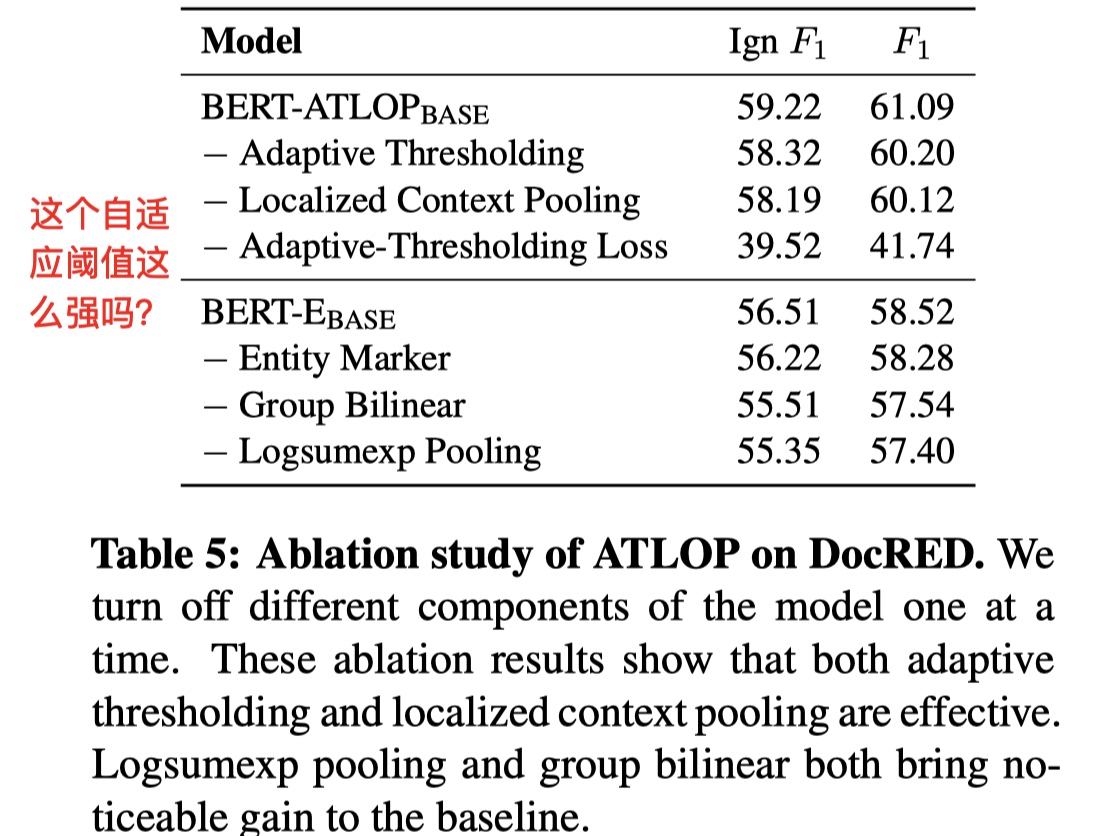
说实话,这个adaptive thresholding loss的效果真是出乎我的意料,我感觉掉到41.74%有点太不正常了,即便不用BERT,用BILSTM也能达到50%,不是很懂这个结果。🧐
Entity and Evidence Guided Relation Extraction for DocRED(arxiv2020)
Background
Model
Experiment
References
《Global-to-Local Neural Networks for Document-Level Relation Extraction》
《HIN: Hierarchical Inference Network for Document-Level Relation Extraction》
《Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling》
《Entity and Evidence Guided Relation Extraction for DocRED》

