这篇博客主要是讲解图神经网络在Document-level关系抽取上的应用,共讲解4篇论文:《Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network》、《Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs》、《Reasoning with Latent Structure Refinement for Document-Level Relation Extraction》、《Double Graph Based Reasoning for Document-level Relation Extraction》。
Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network(ACL2019)
Background
文档级关系抽取的难点在于:我们往往需要抽取的entity pair是span across multi-sentences,所以我们必须对entity的local、non-local、semantic、dependency等信息进行提取和建模。这篇paper提出的GCNN,正是以word为node,words之间的local与non-local dependency作为edge,来构建document-level graph,从而解决文档级关系抽取问题。
Model
先放图~
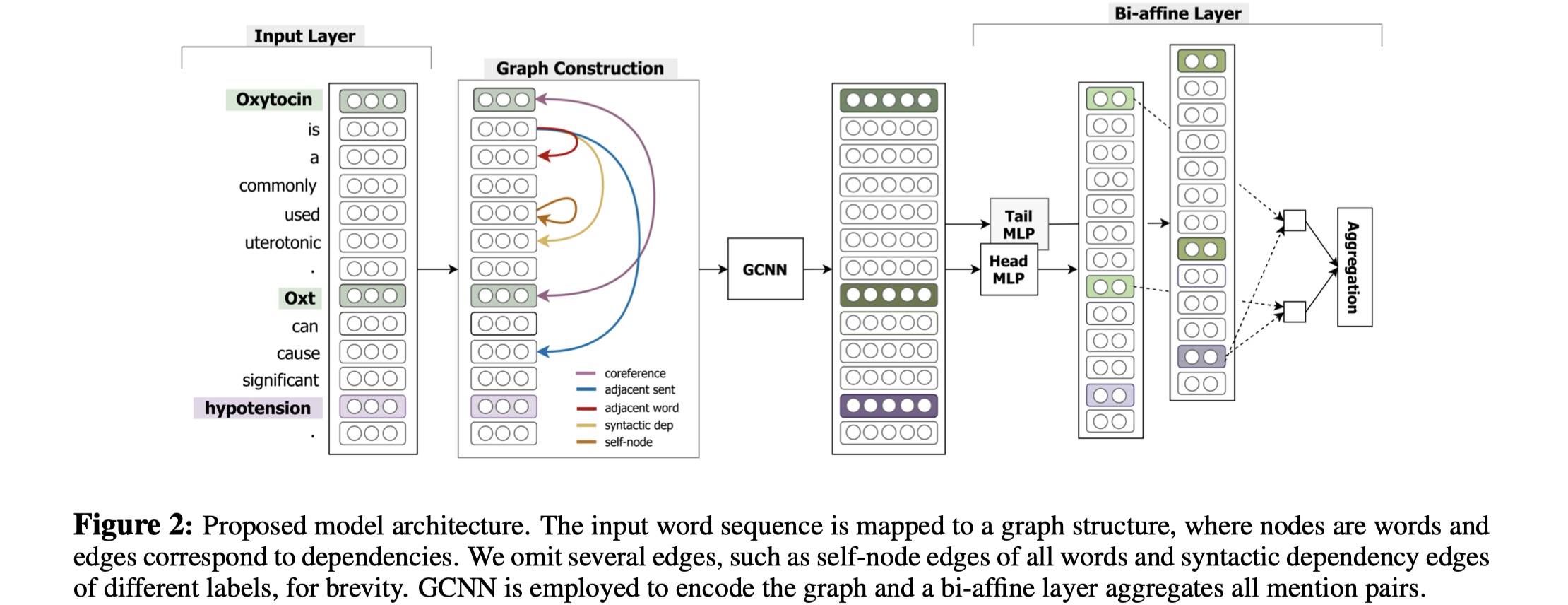
GCNN模型分为4部分:input layer、graph construction、GCNN layer、MIL-based relation classification。
task definition:给定一个document $t$: $[w_1,w_2,…,w_n]$,$e_1,e_2$是$t$中的两个entity,我们的目标是:提取出$e_1$与$e_2$之间的relation。
input layer:对于document中的每一个word $i$,我们将它本身以及它与我们target entity pair的的相对位置分别编码为三个向量:$w_i,d^1_i,d^2_i$,如果一个entity有多个mention的话,那么就选择与当前word最接近的mention来计算相对位置。最后,每一个word的representation为:$x_i=[w_i;d^1_i;d^2_i]$。
graph construction:我们需要根据document来构建graph。在GCNN中,node set就是每一个word,edge set有5种:
- Syntactic dependency edge:句法依赖,也就是使用每一个sentence中的word之间的句法关系建立edge;
- Coreference edge:指代,对于表示同一个含义的phrase,进行连接;
- Adjacent sentence edge:将sentence的根结点鱼上下文sentence的根结点进行连接;
- Adjacent word edge:对于同一个sentence,我们去连接当前word的前后节点;
- self node edge:word与本身进行连接;
GCNN layer:在构建好doucment graph的基础上,使用GCNN来计算得到每一个node的representation。这里使用的GCNN与普通的GCN不同,这里在aggregate node representation的时候,只使用了其邻域的信息,并且对于不同类型的edge,分别使用GCN(毕竟GCN只能用于同质图),最终的结果是所有类型的graph的结果的加和。我认为这里是GCNN模型最出彩的地方了,虽然现在来看并没有什么很新颖的,不过这种GCN的使用方法并不是很好,参见how power GNN这篇论文。公式如下:
其中,$f()$表示某种encoder(e.g. relu)。
MIL-based relation classification:这里使用MIL。因为在一篇document中,每一个entity会有多个mention,我们希望能够去聚合target entity所有的mention,并通过bi-affine pairwise scoring来进行最终的关系分类。具体公式如下:
Experiment
数据集:CDR、CHR(这种两个biochemistry领域的document-level 关系抽取数据集)
结果
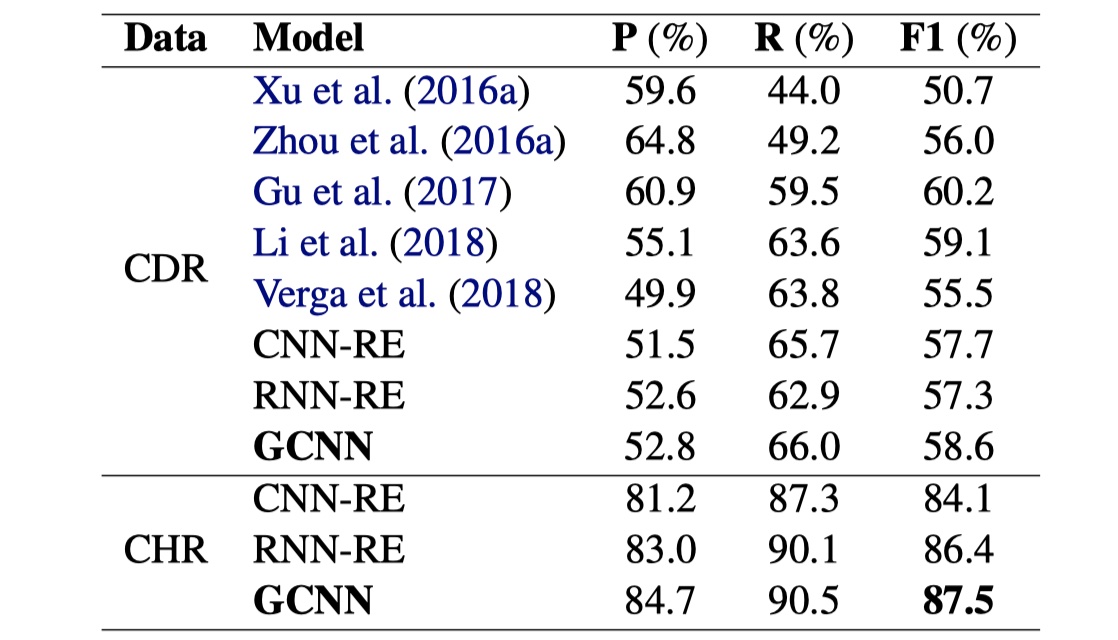
结果就不分析了,没什么好分析的,总的来说,GCNN中规中矩吧,没有太出色的地方,缺点在于:构建了异质图,但是却没有考虑到不同类型的edge的作用;对于mention的处理不够好;logical reasoning几乎没有另外处理,纯靠GCNN;edge的构建需要其他的工具,不一定准确;对于word representation的表示不够。
Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs(EMNLP2019)
Background
这篇paper也是解决document-level relation extraction问题,提出的模型基于以下几个发现:1. 之前很多的graph based model都是基于node的,然而作者发现entity 之间的relation,可以通过节点之间路径来形成唯一的edge representation,从而更好地得到表达;2.每一个target entity的mentions对于entity之间的relation是非常重要的。这篇paper提出的EoG模型很好地解决了这两个问题。
Model
先放图~
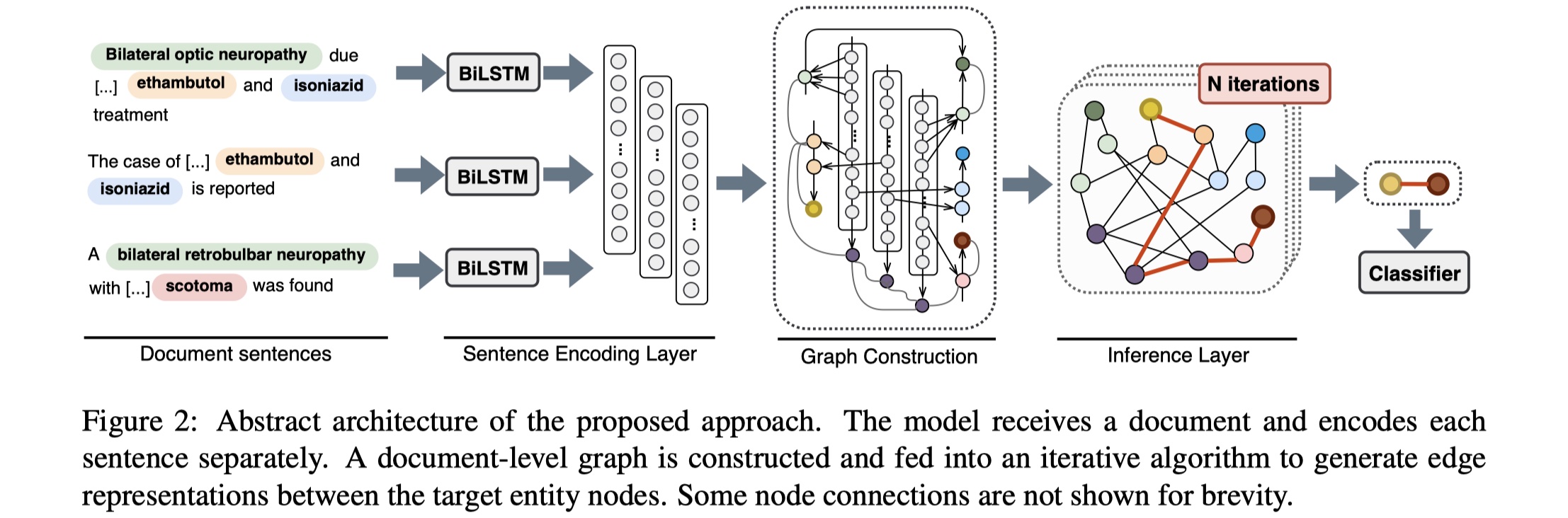
EoG模型分为四部分:sentence encdoing layer、graph construction、inference layer、classification layer。
task definition:给定标注好的document(entity与mentions),目标是抽取出所有entity pair的relation。
sentence encoding layer:doucment中的每一个sentence的word都被编码为一个vector,实际上,这样得到的是4维的张量[batch_size,nums_seqs,seq_length,embedding_dim],然后将其输送到BILSTM中进行编码,得到contxtual representation。
graph costruction:graph construction分为两部分:node construction与edge construction。
node construction:在EoG模型中,有三种node:mention node($n_m$)、entity node($n_e$)、sentence node($n_s$)。mention node是所有entity的mentions的集合。每一个mention node的representation是此mention的所有word embedding的平均;entity node是所有entity的集合,每一个entity node的representation是该entity所有的mentions的平均;sentence node是所有sentence的集合,每一个sentence node是该sentence中所有word embedding的平均。除此之外,我们为了区别不同类型的node,还给每一个node的representation上concat对应类型的node embedding。所以最终的表示:
edge construction:有五种edge:mention-mention(MM)、mention-entity(ME)、mention-sentence(MS)、entity-sentence(ES)、sentence-sentence(SS)。MM edge,我们是连接两个在同一个sentence的两个mention,并且其表示我们是concat这两个mention本身的representation+context+两个mention的距离。具体公式:
$x_{MM}$表示的是对于mention pair $(m_i,m_j)$的MM edge,当i=1,j=2时,$x_{MM}=[n_{m_1};n_{m_2};c_{m_1,m_2};d_{m_1,m_2}]$,其中$c_{m_1,m_2}$的计算如下:
其中,$a_i$表示sentence的第$i$个word对此mention pair的重要性程度,也就是attention weight。
ME edge,我们连接所有的mention与其对应的entity,$x_{ME}=[n_m;n_e]$;
MS edge,将mention与此mention所在的sentence node进行连接,$x_{MS}=[n_m,n_s]$ ;
ES edge,如果一个sentence中至少存在一个entity的mention,那么我们将setence node与entity node进行连接,$x_{ES}=[n_e;n_s]$;
SS edge:将所有的sentence node进行连接,以获得non-local information,$x_{SS}=[n_{s_i};n_{s_j};d_{s_i,s_j}]$,其中$d_{s_i,s_j}$表示两个sentence的距离vector。
当然了,我们最终的目的是提取出entity pair的relation,所以我们对所有的edge representation都做一个线性变换,从而让其唯独一致。即:$e^{(1)}_z=W_zx_z,z\in[MM,ME,MS,ES,SS]$。
inference layer:由于我们没有直接的EEedge,所以我们需要得到entity之间的唯一路径的表示,来产生EE edge的representation。这里使用了two-step inference mechanism来实现这一点。
the first step:利用中间节点$k$在两个节点$i$和$j$之间产生一条路径,如下:
The second step:将原始的edge(如果有的话)与所有新产生的edge进行聚合,如下:
重复上述两步N次,我们就可以得到比较充分混合的EE edge。实际上,这一步就是为了解决logical reasoning。
classification layer:这里使用softmax进行分类,因为实验所使用的两个数据集其实都是每一个entity pair都只有一个relation。具体公式:
Experiment
数据集:CDR、GDA
实验结果:
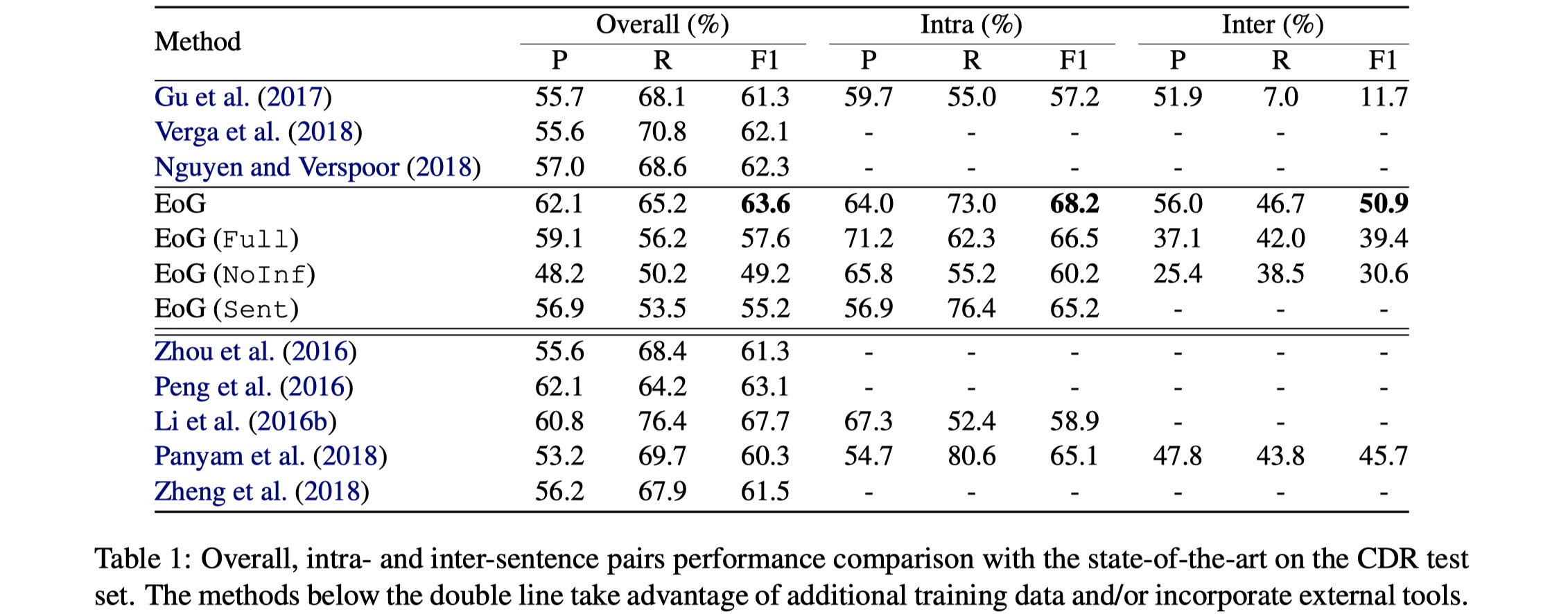
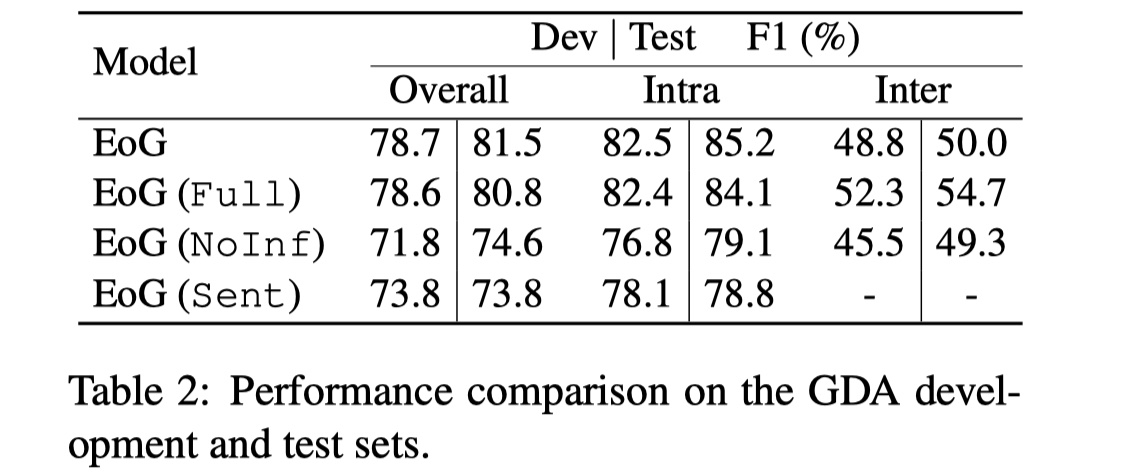
结果没什么好看的,主要来看一下ablation。
ablation
EoG模型做了一些消融实验。首先是对EoG(full)、EoG(NoInf)、EoG(Sent)在不同长度的entity pair进行实验:
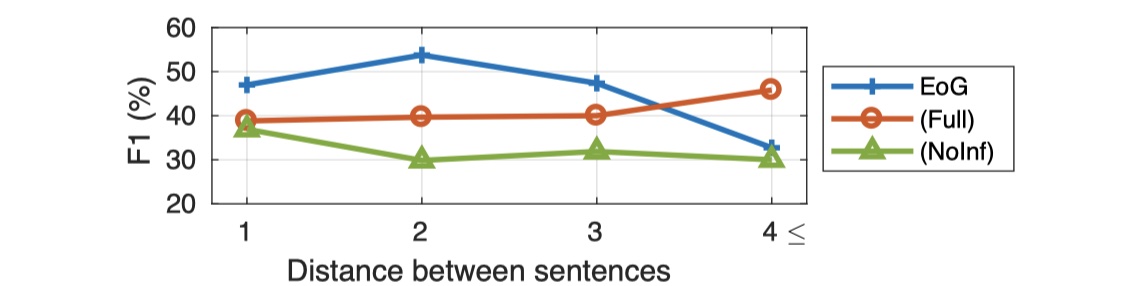
可以看到,当entity pair之间相差4句以上时,结果明显要好,这说明原始的EoG忽略了一些重要节点之间的交互信息,那么能不能让模型自动选择哪些节点要交互,哪些节点不要交互呢?(在LSR就是这么做的)除此之外,作者还对不同的compnent进行了消融实验。如下:
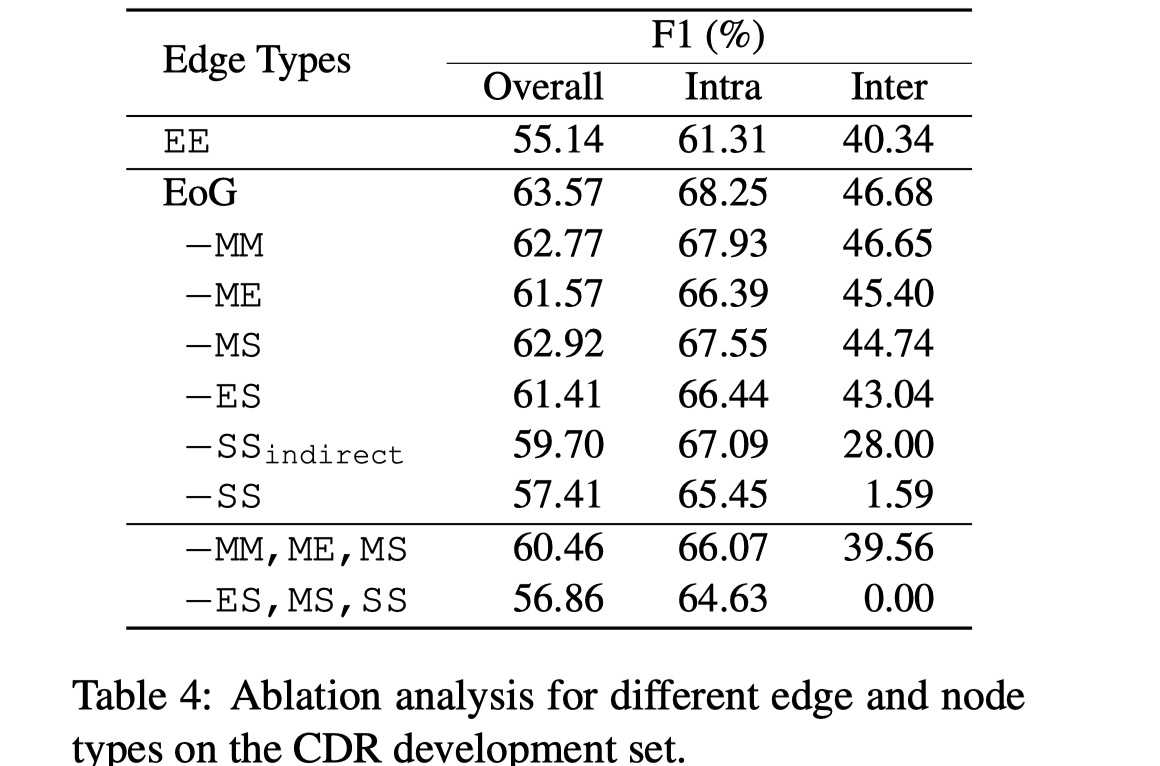
从结果可以看到,去掉SS对结果影响巨大,这说明对于document-level RE,提取inter-sentence之间的交互信息是非常重要的,另外,MM似乎对结果影响最小,但是我认为MM对于entity pair的relation identification是非常重要的,只是EoG里面构造的方式不对,在之后的GAIN模型里面,可以看到MM对结果提升巨大,当然构建方式不一样。
当然了,最后还做了一些bad case的分析,有三种:使用and相连接的entity,model无法找到她们之间的relation;缺少coreference;3.不完全的实体链接。个人觉得EoG模型是一个非常好的开端,提供了很多思路,值得细细品读。
Reasoning with Latent Structure Refinement for Document-Level Relation Extraction(ACL2020)
Background
这篇我个人感觉是EoG模型的改良,针对的问题就是:在EoG模型的消融实验中,发现full version在长度大于4时的效果要比原始的EoG模型要好,那么在full的情况下,是否可以让模型自动选择哪些边重要,那些不重要呢?这就是LSR模型。
个人觉得这篇相对较难,主要是其使用矩阵树原理,对数学要求较高,如果觉得看不懂,只看个大概也是OK的,这篇个人觉得没有follow的价值。
Model
LSR模型分为三部分:node constructor、dynamic reasoner、classifer。
node constructor:这一部分分为两小部分:context encoding与node extraction,主要就是对document中的所有word进行编码,并得到graph所有类型的node的representation。先放图·
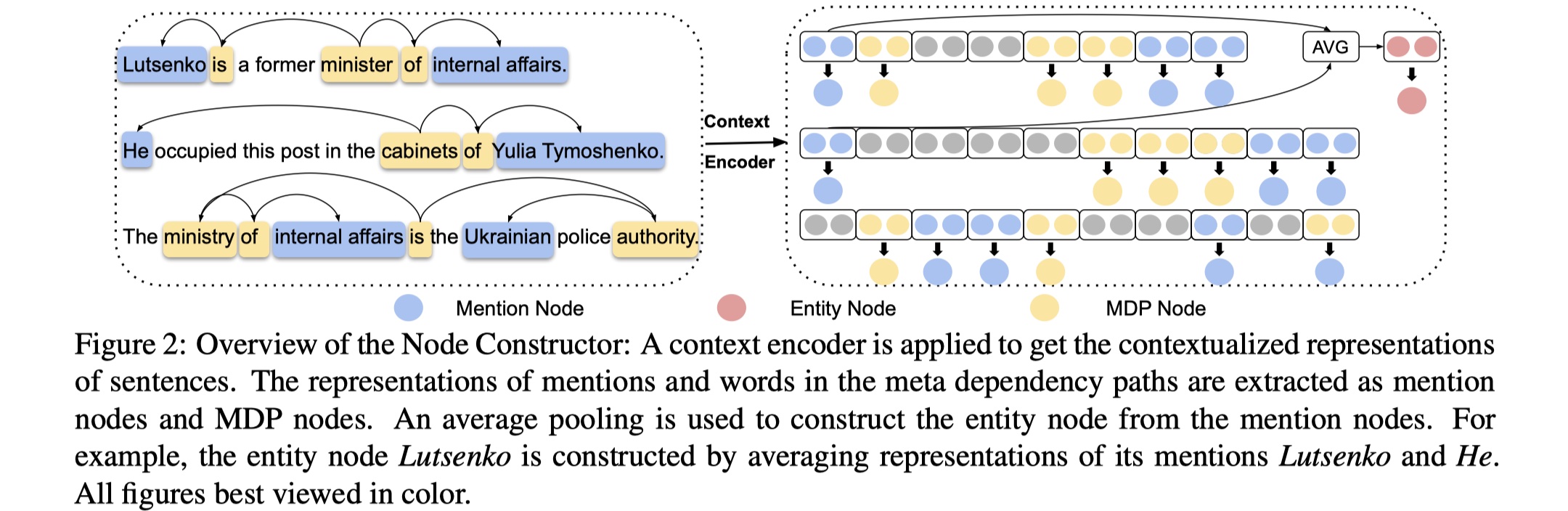
Context encoding:对于给定的document $d$,我们将其输入到一个encoder中(BILSTM/BERT etc),得到contextual representation。
node extraction:在LSR中,有三种node:mention node、entity node以及meta dependancy path node。mention node表示的是一个sentence中entity的所有的mention,其表示是该mention中的所有word的representation的平均;entity node指的是entity node,其表示是所有mention node的representation的平均;MDP表示一个句子中所有mention的最短依赖路径集,在MDP元依赖路径中,mention和单词的表示分别被提取为提及节点和MDP节点。(说实话,不是很懂MDP。🧐)
⚠️LSR与EoG模型不同的地方之一在于:mention node与entity node一样的,但是LSR没有sentence node,并且使用了MDP node来代替,本质上差不多吧,不过相比于sentence node,MDP node能够过滤掉无关信息(paper原话🧐),但是说实话,在context encoding中,已经引入了无关信息吧,而且在之后的实验中,确实也证明MDP没啥用。
dynamic reasoner:这一部分就是inference,因为在EoG里面,已经证明了没有inference对最终结果影响还是蛮大的。主要分为两部分:structure induction与multi-hop reasioning。先放图~
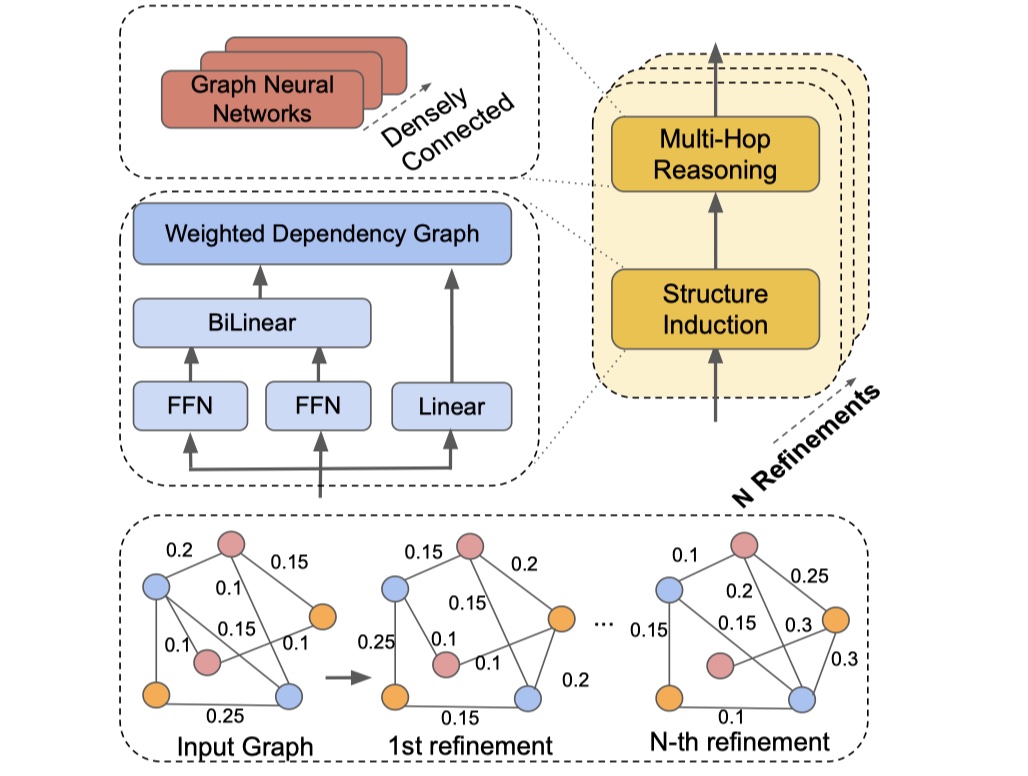
structure induction:这一部分主要是用来学习文档图的结构,从而得到文档图的邻接矩阵,从而以便使用GCN来进行aggregate。公式如下:
其中,$s_{ij}$表示的是node i与node j之间的关联度,$s_i^r$表示的是node i被当作structure root node的非规范化概率,$P_{ij}$表示的是node i与node j之间的edge的权重,$L$是laplace矩阵,$\tilde L$是变体,为了进一步计算用的,$A$表示的是文档图的邻接矩阵。
这里使用了structure attention network以及矩阵树原理的思想,这里不具体展开,想要深究的可以百度或者Google。
multi-hot reasoning:在得到邻接矩阵之后,LSR便使用GCN来对graph进行aggregate。公式如下:
当然了,我们可以重复多次dynamic reasoner模块,从而得到更加丰富的node representation。
classifier:这一步就是直接对entity pair进行关系分类,使用sigmoid函数。如下:
Experiment
数据集:CDR、GDA、DocRED
结果
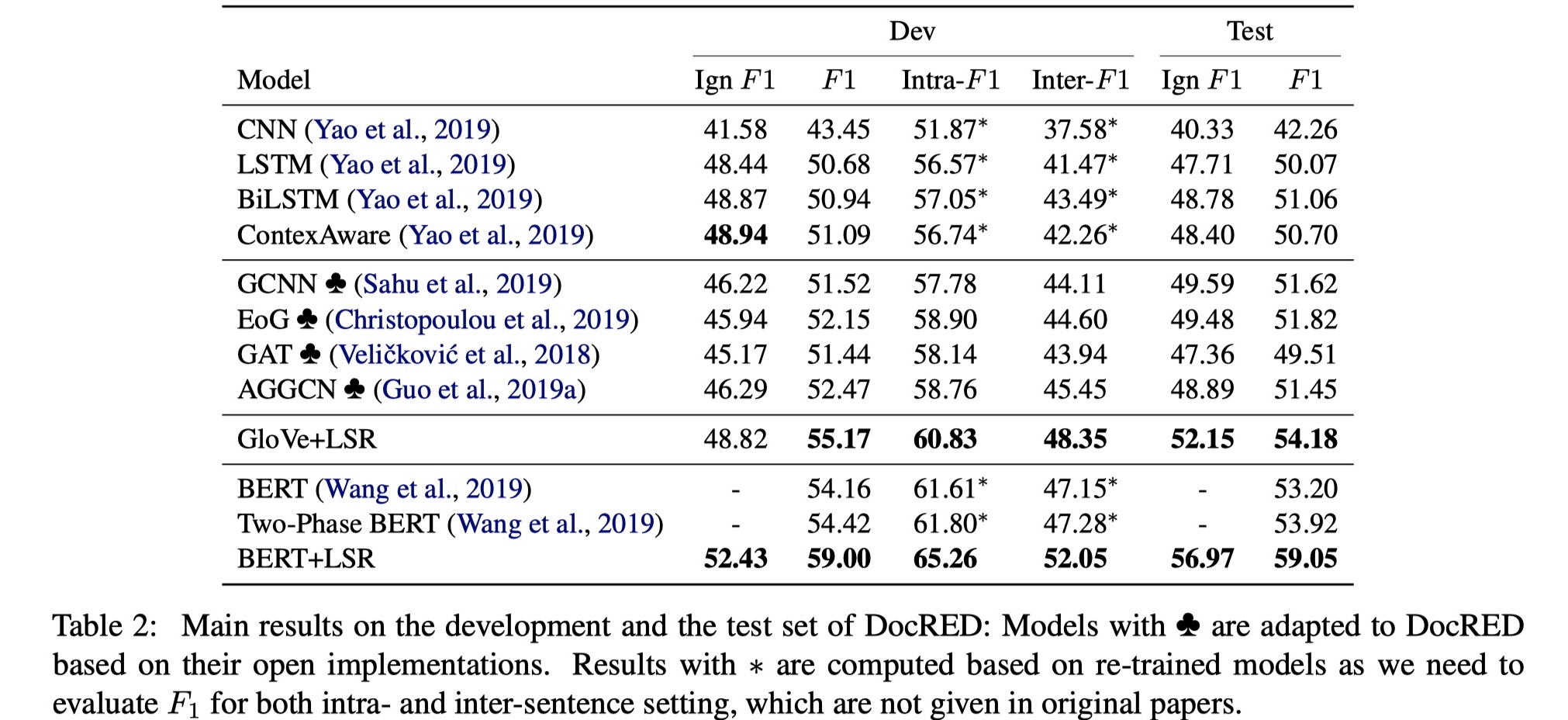
从在DocRED上的结果来看,可以说是非常好。我们在来看一下其在CDR与GDA数据集上的结果。
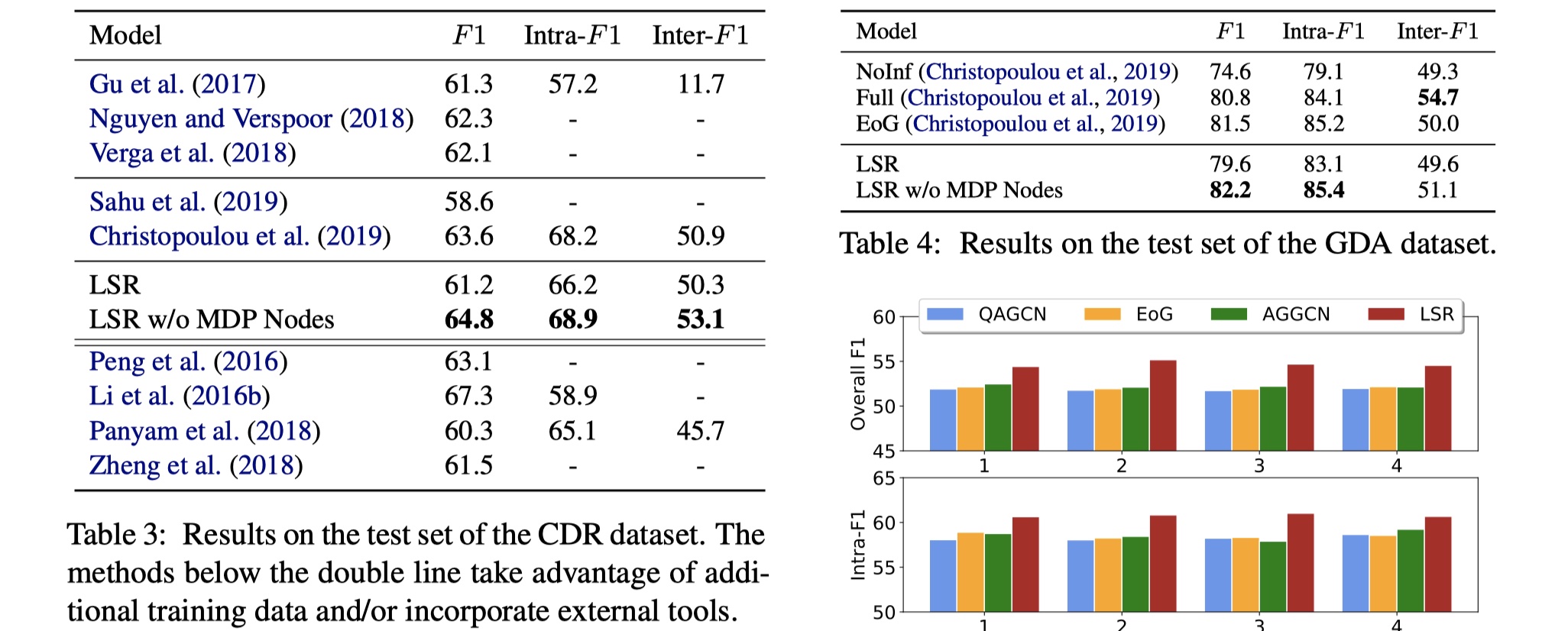
在没有MDP节点的情况下,取得了SOTA,说明MDP的作用一般。总的来说,LSR模型确实很新颖,但是follow的价值一般。
Double Graph Based Reasoning for Document-level Relation Extraction(EMNLP2020)
Background
这篇paper也是继承了EoG模型,主要解决三个问题:1.一个relation的subject与object可能位于不同的sentence,不能仅仅利用一个句子来得到relation;2.同一个entity可能会出现在不同的sentence当中,因此需要利用cross-sentence context information,从而更好的表示entity;3.很多relation需要logical reasoning(main issue)。为此提出了GAIN模型。个人认为这篇paper的模型比较优雅,挺好的。
Model
先放图~
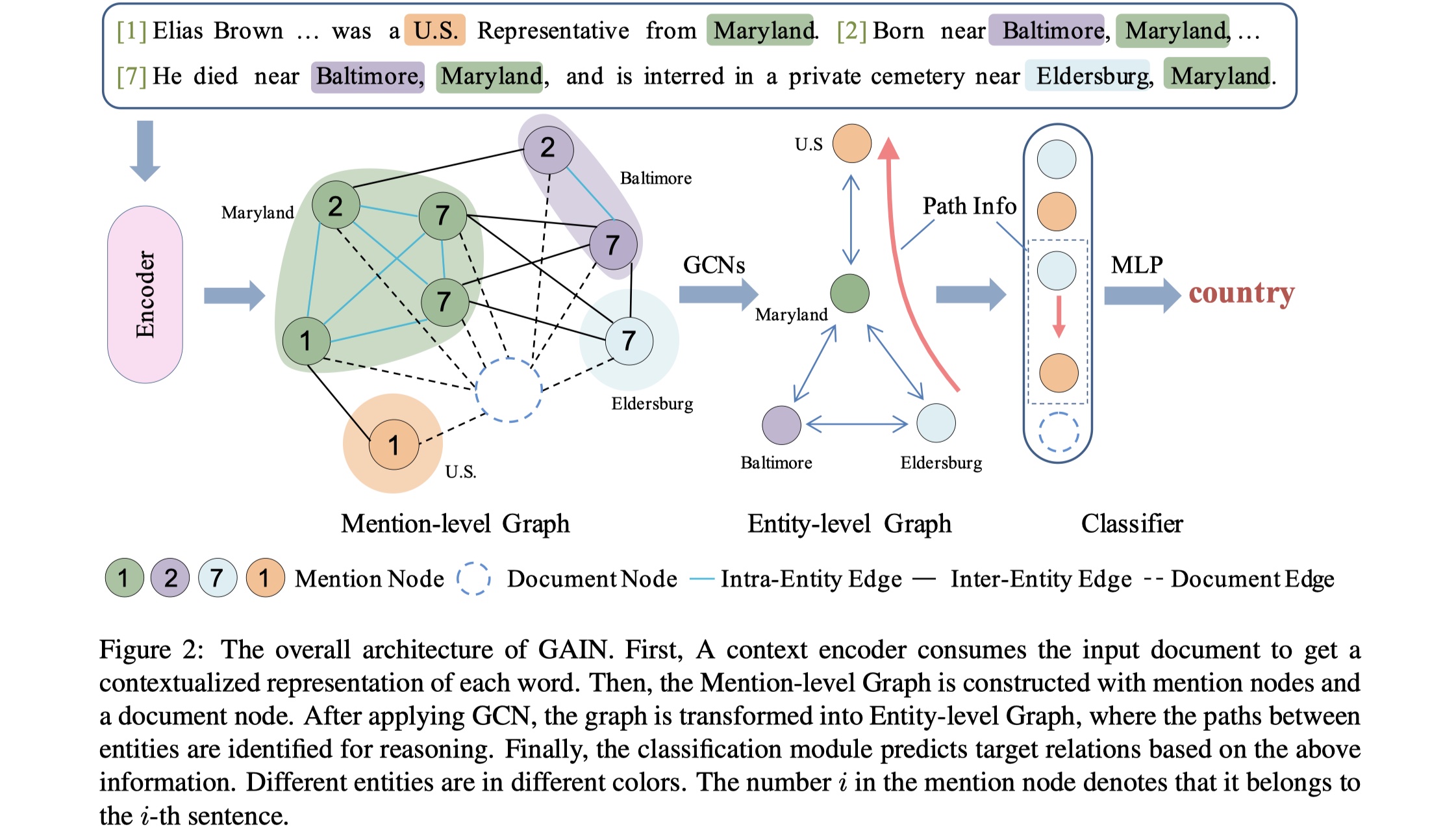
GAIN模型分为四部分:encoding module、mention-level graph aggregation module、entity-level graph aggregation module、classification module。
task definition:给定一篇含有$N$个sentence的documnt:$\cal D=\{s_i\}_{i=1}^{N},s_i=\{w_j\}_{j=1}^{M}$,以及$P$个entity:$\cal E=\{e_i\}_{i=1}^{P},e_i=\{m_j\}_{j=1}^{Q}$,其中$e_i$表示第$i$个entity,$m_j$表示第$i$个entity的第$j$个mention。我们的目标是entity之间的relation。
encoding module:这一部分主要是将document中的word经过编码,得到contextual representation。给定有n个word的document:$\cal D=\{w_i\}_{i=1}^{n}$,然后将word embedding与type embedding以及coreference embedding进行concat,得到final word embedding,即:
其中,$t_i$与$c_i$是$w_i$对应的named entity type id与entity id,对于那些不属于任何entity的word,我们引入
Nonetype。得到final word embedding之后,我们将其输入到一个encoder当中(BISLTM/BERT etc),得到这一层的输出:mention-level graph aggregation module:这个graph的构建主要是对mention之间的关系进行建模。在mention-level graph当中,node set:mention node与document node。mention node就是表示每一个mention,document node是一个虚拟节点,主要是为了对document information进行建模,同时也是视其为一个中继节点,让不同mention之间的交互变得更加容易。edge set:intra-entity edge、inter-entity edge、document edge。intra-entity edge是让同一个entity的mention彼此连接;inter-entity edge是让一个句子内的不同entity的mention之间进行连接;document edge是让所有的mention与document node进行连接。
构建好graph之后,GAIN模型使用与GCNN中同样的GCN,如下:
但是这种虽然很接近WL-test,但是会存在范数不收敛的情况,这个真的不需要考虑一下吗?🧐在stack N层GCN之后,对于每一个node,我们去concat所有layer的representation,来作为每一个node的final representation,即:$m_u=[h^{(0)}_u;h^{(1)}_u;…,h^{(N)}_u]$。
entity-level graph inference module:这一步就是进行inference,得到entity-entity的表示,用于最终的分类,所以path reasoning mechanism很重要。在entity-level graph中,我们将同一个entity的所有mention的表示的平均作为此entity的表示,即:$e_i=\frac{1}{N}\sum_n m_n$。entity node之间的边表示:$e_{ij}=\sigma(W_q[e_i;e_j]+b_q),\sigma \text{是激活函数}$。对于entity pair之间不同的路径,其表示是:$p^i_{h,t}=[e_{ho};e_{ot};e_{to};e_{oh}]$,当然了,entity pair之间的path会有多个,我们使用attention机制,如下:
其中,$\sigma$是某一个激活函数。这里只使用了2-hop,如果使用multi-hop,效果会不会更好?🧐
classification module:这里就是最终的分类。但是这里借用了ESIM中表示,对于enitty pair $(e_h,e_t)$,其综合的inferential path information是:
其中,$m_{doc}$就是document node,然后我们将其看作一个多标签分类问题,使用sigmoid函数,来完成分类,如下:
最终的loss使用CE。
Experiment
数据集:DocRED
实验结果
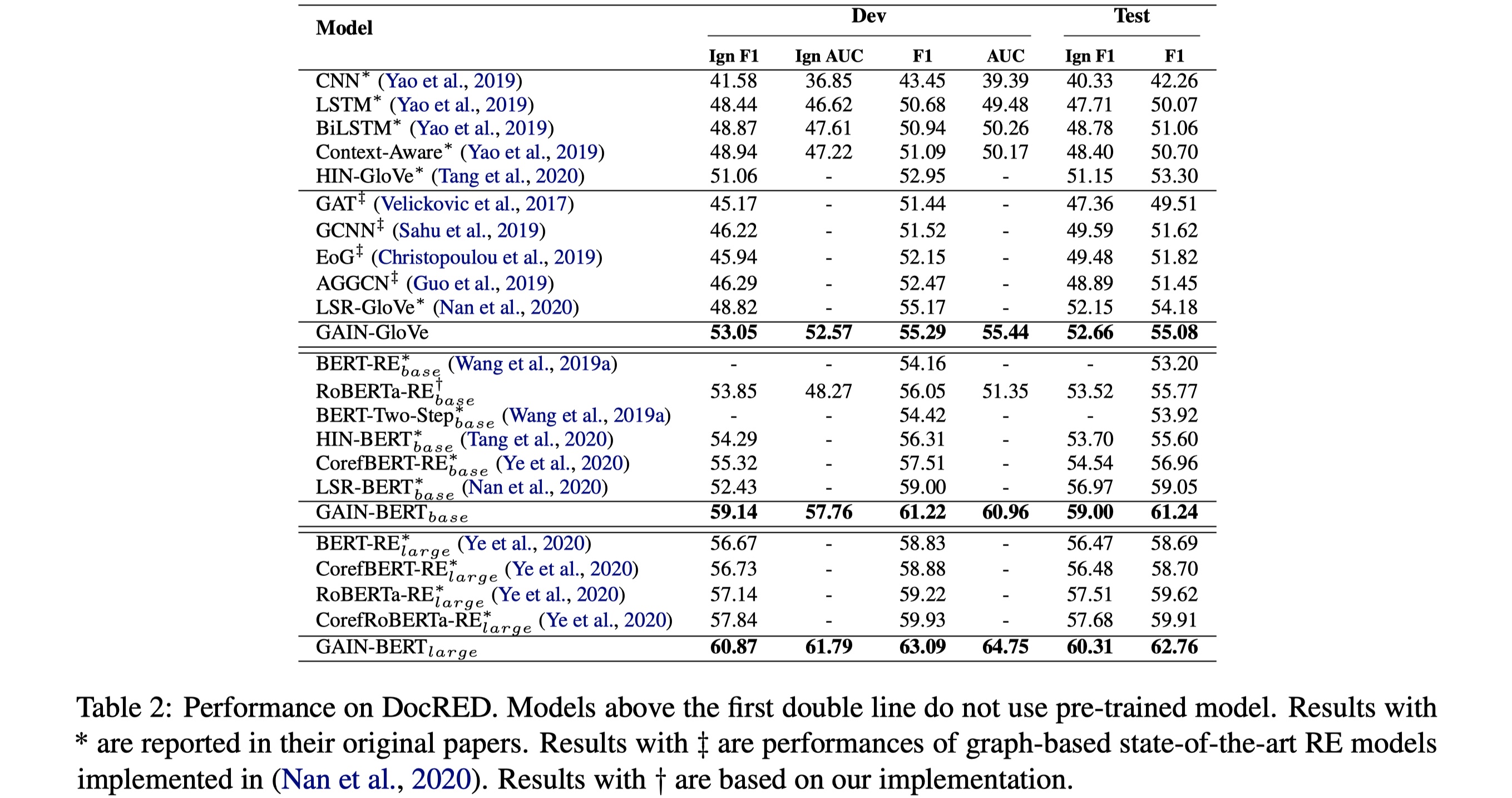
从结果上看,GAIN的效果是令人惊艳的。我们再来看看ablation,如下:
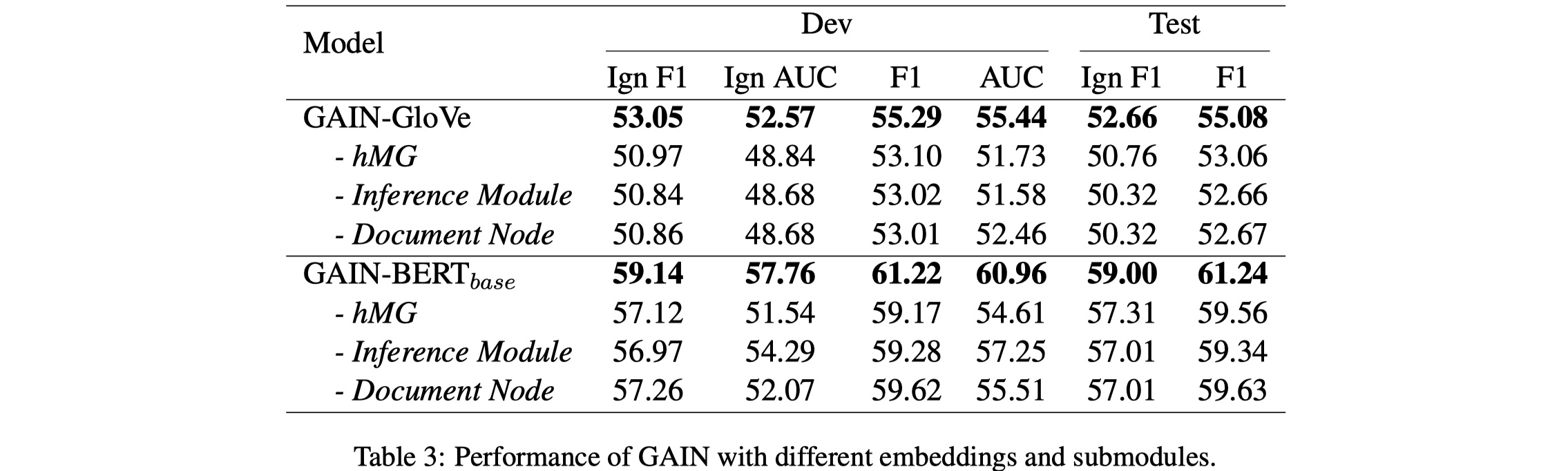
从消融实验来看,可以发现各个模块对于结果的话影响都是非常巨大的,很优雅,没有多余的设计。
目前来看,主要的处理:encoding?怎么构建图,才能够利用好mention、entity、sentence、document的信息(edge-oriented or node-oriented)?heterogeneous graph的处理?logical reasoning的处理?长期建模很重要,怎么更好地处理?
References
《Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network》
code:见EoG的code,差不多
《Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs》
code:https://github.com/fenchri/edge-oriented-graph
《Reasoning with Latent Structure Refinement for Document-Level Relation Extraction》
code:https://github.com/nanguoshun/LSR
《Double Graph Based Reasoning for Document-level Relation Extraction》

