这篇博客主要讲解一下Document-level 关系抽取上的最新的两个数据集:DocRED以及SCIREX,paper名称:《DocRED: A Large-Scale Document-Level Relation Extraction Dataset》、《SCIREX: A Challenge Dataset for Document-Level Information Extraction》。
DocRED dataset
Background
DocRED数据集是发表在ACL2019上的《DocRED: A Large-Scale Document-Level Relation Extraction Dataset》。关系抽取是NLP中一个非常基础且重要的任务,主要是:辨别text中实体之间的relation facts。但是在目前的relation extraction中,主要都是集中在sentence-level上,也就是提取句子内的实体,并识别实体之间的关系。但是在实际的问题当中,很多实体之间的关系需要通过多个句子来获得,所以将sentence-level的raltion extraction扩展到document-level 的relation extraction是非常有必要的。而目前已有的document-level的数据集,要么数据量不够大,要么有很多的噪音,要么构造的数据集只适用于某一个领域,这对于构建general domain下的document-level relation extraction model是不利的,在这种情况下,就有了DocRED。
Statistics of DocRED
DocRED是根据wikipedia和wikidata构建而来,最后DocRED的各项数值如下:
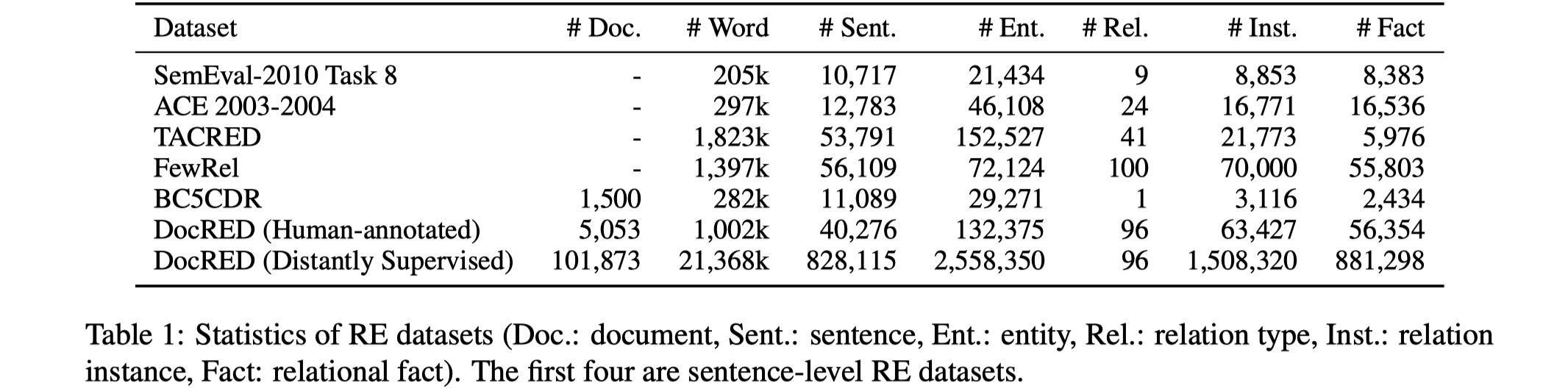
从图中可以看到,在DocRED中,平均每一个document的word大概在198.2~209.7之间,说实话,这个程度其实只能算是paragraph,离document还差的比较远,这一点SCIREX数据集弥补了(平均有5000左右)。
Baseline
paper中实验了当时SOTA的三种模型。大致的过程是:首先对于一篇doucment表示为:$\cal D=\{w_i\}_{i=1}^{n}$,其中$w_i$表示第$i$个word,我们将其输入到CNN/LSTM/BILSTM当中,得到encoder后的$\{h_i\}_{i=1}^{n}$,然后我们可以得到entities的representation,最后预测每一个entity pair的relation type。下面讲解一些details:
word features:对于sentence中的每一个word,它的feature=[GloVe_word_embedding; entity_type_embedding; coreferance_embedding]。
named entity mention representation:这里需要明确named entity mention与entity的区别。named entity mention指的是与entity相关的word的集合,包括指代、缩写、nickname等等。举个例子:
北京大学是一个entity,它的named entity mention可以有:北大、p大、贵校、你北、隔壁等等。那么在relation extraction中,我们要做的recognize named entity mentions。当我们identity named entity mentions后,我们怎么表示entity呢?entity $e_i$如下:其中,$K$表示entity $e_i$所有的mentions的数量,$m_k$表示第$k$个mention,t与s是第$K$个mention的开头与结尾的index。
prediction:对于relation extraction,我们是将其视为一个多标签分类的问题,所以采用的是sigmoid函数,对于每一个entity pair $(e_i,e_j)$,具体如下:
其中,$d_{ij}$与$d_{ji}$表示的是两个entity在document中第一个mention之间的相对距离,$E$是一个embedding matrix。
experiment
先放结果~
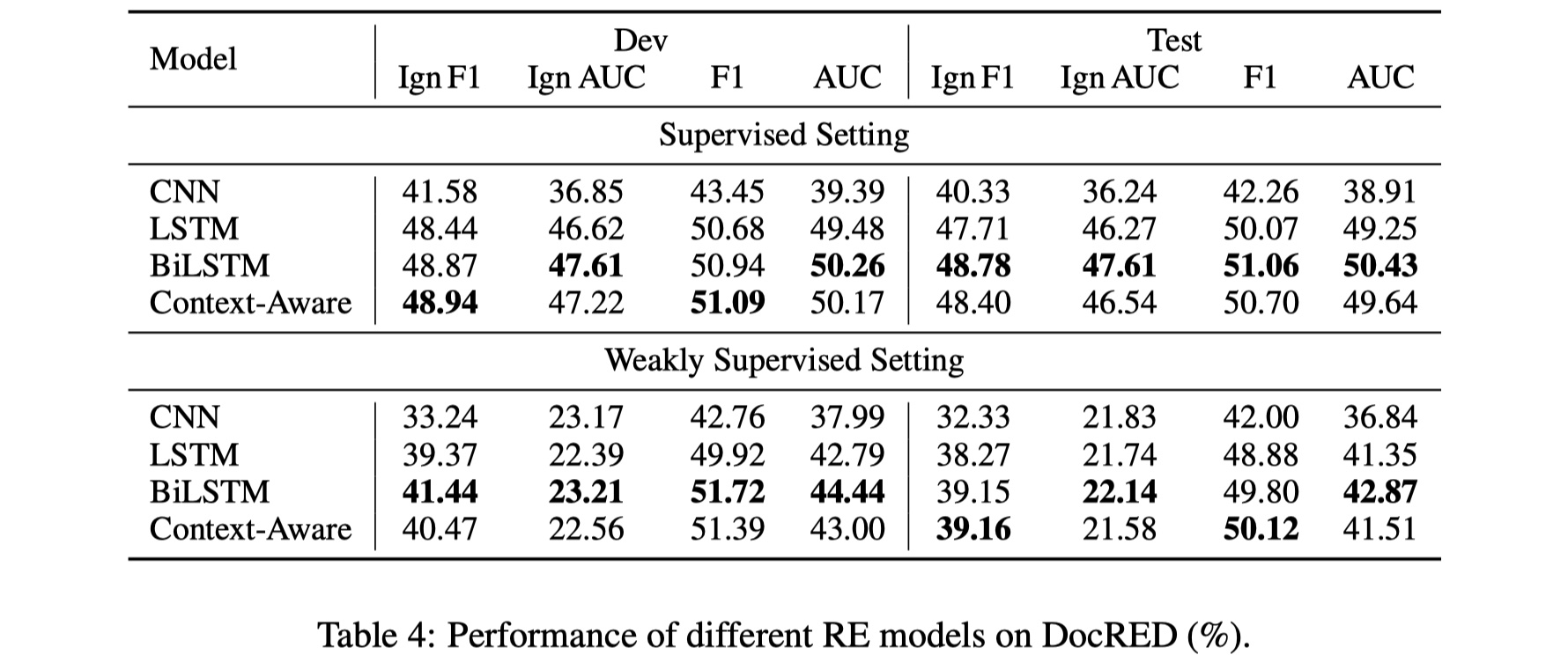
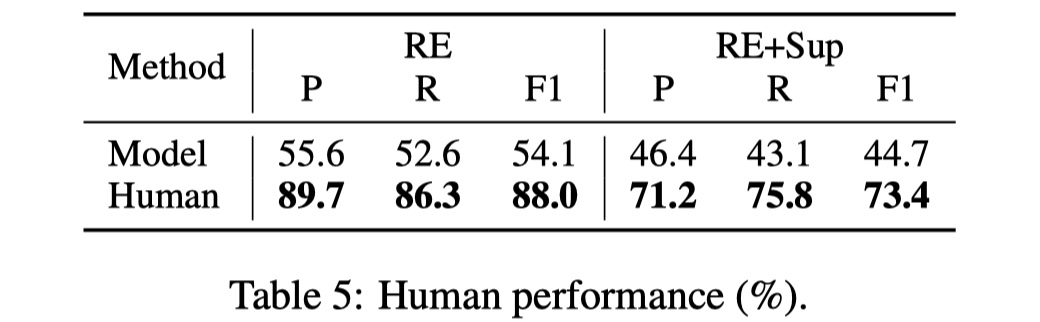
- 对于DocRED,评价指标采用的是F1和AUC,但是为了避免训练集与验证集/测试集上relation facts的overlap,所以又提出了Ign F1和Ign AUC指标,以获得更好的效果。
- 从上面的表中可以看到,目前的baseline的效果与human的performance相去甚远,还有很大的可以提高的空间。
- 在DocRED中,除了关系分类任务,还提出了另一个子任务——identity 关系实例(relation instances)和支持证据(supporting envidences),用于进一步提高性能。
- 总的来看,DocRED是一个general domain document-level relation extraction datasets,目前已有的方法的效果与human performance相去甚远,有很大的提升空间,是一个可以做的方向。
Data format
1 | { |
SCIREX dataset
Background
SCIREX数据集是发表在ACL2020上的《SCIREX: A Challenge Dataset for Document-Level Information Extraction》。它提出的主要背景与DocRED类似,目前主要的relation extraction主要都是围绕着sentence-level进行的,但是实际问题中,entity之间的relation往往要通过多个sentence 推理得到,而针对sentence-level的model无法处理这种问题,所以有必要将sentence-level扩展到document-level relation extraction/information extraction。而目前已有的document-level information extraction datasets,远远不能满足document-level IE/RE的要求,最接近的是DocRED数据集,但是这个数据集是从wikipiedia paragraph中构建的,所以它的长度远远不能达到document的要求(DocRED大约在200 word/doc),所以就有了SICREX。
Statistics of SCIREX
SCIREX是根据scientific articles构建而来,具体数据如下:
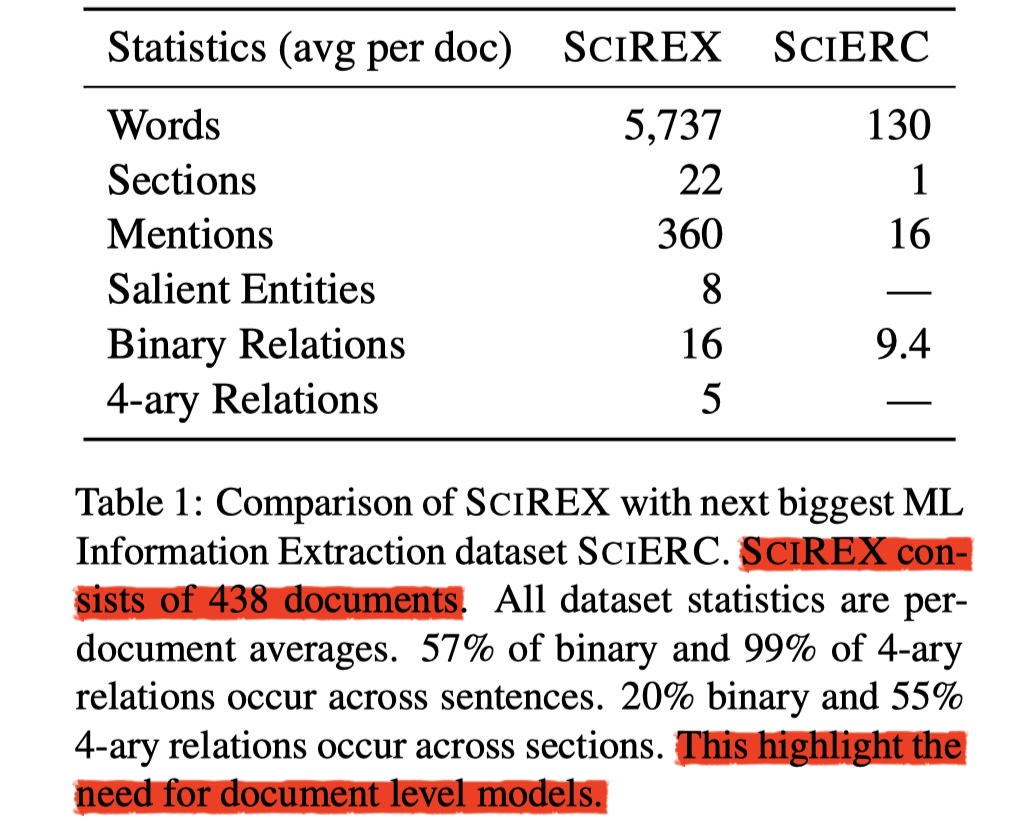
从上图中可以知道,SCIREX数据集每一篇document有5737个word,比DocRED中的document长的多,可以说是真的document了;此外,SCIREX共有438篇document,虽然相对较少,但是从总的word来说,SCIREX的word数目是DocRED的2倍(human-annotated version)。
Tasks in SICREX
在SCIREX数据集中,作者定义了四种任务:entity recognition、salient entity recognition、coreference、relation extraction。
- entity recognition:这个其实和DocRED中的named entity mention recognition是一样的,不过又有点不太一样。在SCIREX中,共有四种entity:Method、Task、Metric、Dataset,各自的mentions是这四种entity的各种mention(好像和没说一样🤣,这个在DocRED的介绍里有的,这里不再赘述)。总之这个任务是:识别各种entity mentions并分类到各自的entity type中。
- salient entity recognition:由于出现在document中的每一个entity mentions的重要性程度是不一样的。就比如relation work中提到的task相比于文章主体的task,重要性要小的多,所以就有必要进行salient entity recognition。
- coreference:这个任务是identity在单篇document中指向同一个entity的mentions的集合(cluster)。
- relation extraction:RE是指在单篇document中提取entities之间N元关系的任务。在SCIREX中,有2元关系、三元关系以及四元关系。但是需要注意的是,在SCIREX中,N-元关系不能被切分为多个二元关系,因为一个Datasets可能会有多个Task,一个任务可能会有多种Metric,所以metric不能仅仅根据Dataset或者Task来决定。
Baseline
SCIREX中给出了一个非常强的Baseline,但是我个人觉得比较遗憾的是,这篇paper没有给出human performance,不知道up bound是怎么样的。baseline具体如下:
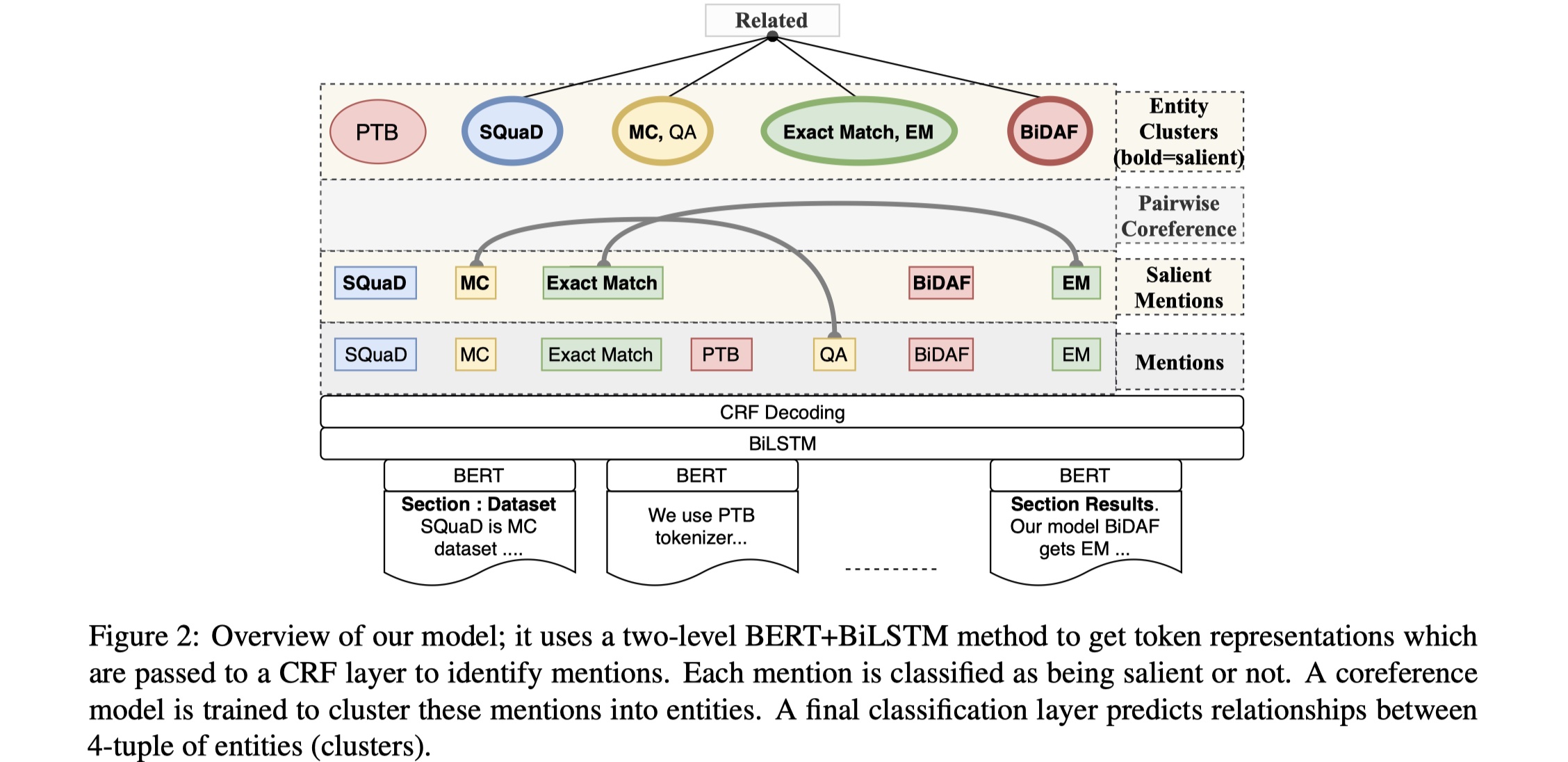
Document representation:我们假设一个输入的文档$\cal D$表示为:$[s_1,…,s_{|S|}]$,其中$s_i$表示第i个section(section可以理解为paragraph),共有$|S|$个section。document encoding分为两步:section-level and document-level。每一个section的tokens embedding通过SCIBERT来得到,每一个section-level token embedding的维度是:[tokens_nums,embedding_dim],得到之后,我们对所有的section-level token embedding进行concat,维度是:[|S|*tokens_nums,embedding_dim],然后输入到一个BILSTM当中,得到结果$e_i,i\in\{1,..,|S|\}$。注意如果是batch输入的话,经过BILSTM的得到的维度是:[batch_size,|S|*token_nums,embedding_dim]。
Mention identification and classification:在得到token embedding之后,经过BILSTM+CRF,去对mentions进行identification与classification。
Mention representation:得到mentions之后,我们就要执行之后的salient mention classification与relation extraction任务,但是要执行这两个任务,需要先得到mention embedding。那么对于一个mention $m_j$,它的representation是怎么样的呢?具体如下:
对于一个mention $m_j$,他所包含的words表示为:$\{w_{j_1},w_{j_2},…,w_{j_N}\}$,$m_j$的mention embedding是:
$e_{j_1}$与$e_{j_n}$分别表示该mention的first word与last word的token embedding。除此之外,还会将span在文档中的相对位置信息加入到其中,以获得更多的信息。
Salient mention classification:这个任务就是去看每一个mention是不是salient,是一个二分类的任务。
Pairwise coreference resolution:这个任务就是计算每一对mention pair$(m_i,m_j)$的coreference score $c_{ij}$。
Mention clustering:给定mention pair的集合,以及他们对应的coreference score,我们需要对它进行层次聚类,每一个cluster都表示一个entity。
Salient entity cluster classification:这一步在上一步的mention clustering的基础上,过滤掉那些不够salient的cluster,只留下salient的cluster,从而用于最后的relation extraction task。具体怎么做呢?paper里面采用了一个比较简单的方法,就是只要这个cluster里面出现了一个salient mention,我们就认为这个cluster是salient,就保留该cluster。这一步最终的输出cluster的集合:$C=\{C_1,..,C_L\}$,其中$C_i$是同一个type的mention的集合。
Relation extraction:这是最终的任务,我们需要通过上述的salient cluster,构建所有cluster的二元组和四元组,然后我们要判断这些二元组与四元组是否在document中expressed or not expressed。怎么做呢?这里以四元组为例:
假设对于一个四元组:$R=(C_1,C_2,C_3,C_4)$,其中$C_i$表示一个cluster,我们通过一个two-step的precedure来获得 R的vector:首先构建一个section embedding,然后aggregate 所有的section embedding,从而得到document embedding。对于$\forall C_i \in R$,我们可以通过max-pooling 出现在section $s$ 中的$C_i$中的mentions的span embedding,从而得到$C_i$在section $s$的section embedding $E^s_i$。relation $R$在section $s$的section embedding是:$E^s_R=FFN([E^s_1,E^s_2,E^s_3,E^s_4])$;然后relation $R$的document embedding是:$E_R=\frac{1}{|S|}\sum_{s=1}^{|S|}E^s_R$。最终的分类是将$E_R$输入到另一个FFN层,然后进行分类。loss为binary CE。
experiment
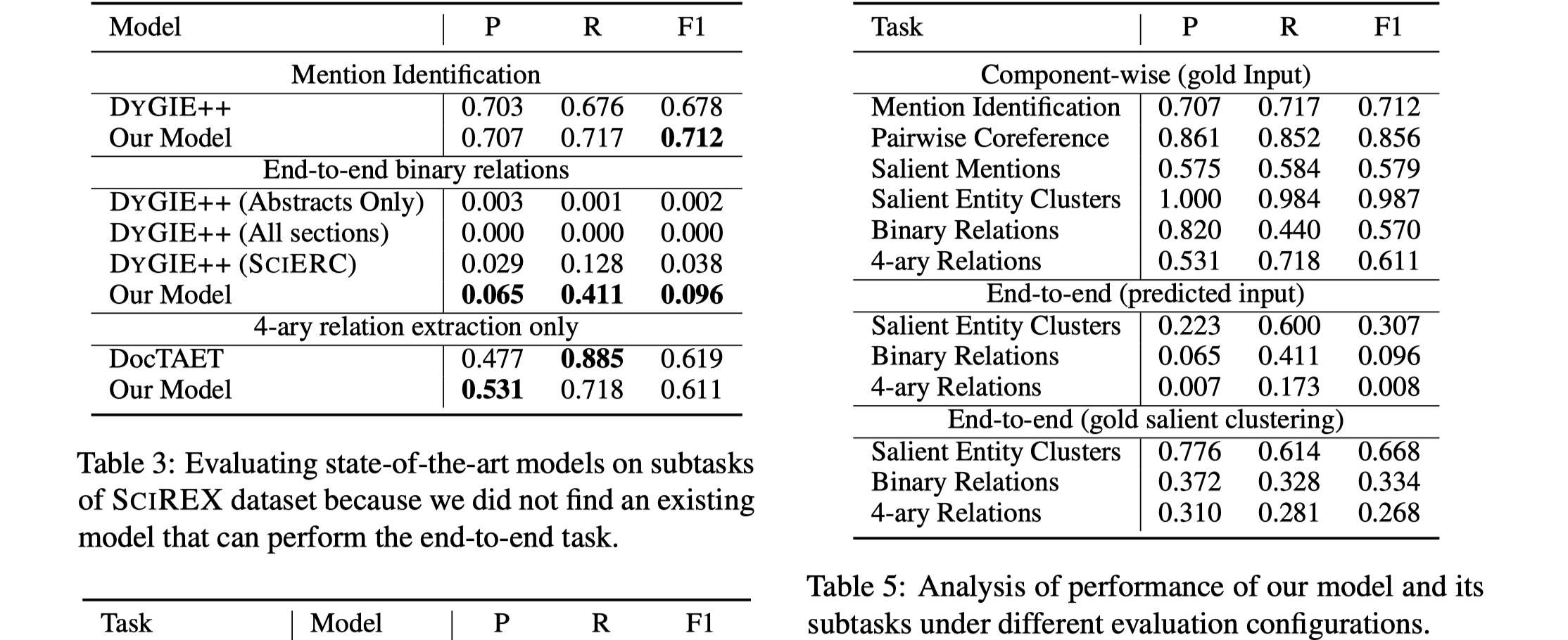
左图是本文提出的模型与DYGIE++模型在各个子任务上进行对比,右图是本文提出的模型的各个子任务上的结果,可以看到,采用端到端的烦事,最终的relation extraction的结果非常低,而采用glod input的结果,要高得多,所以可以看到salient entity cluster classification是整个端到端系统的影响最大的一步。感觉还是有很大提升空间的。
Data format
1 | { |
References
《DocRED: A Large-Scale Document-Level Relation Extraction Dataset》
code:https://github.com/thunlp/DocRED
《SCIREX: A Challenge Dataset for Document-Level Information Extraction》

