近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要解读一下目前多模态NER上质量比较好的论文:《Adaptive Co-Attention Network for Named Entity Recognition in Tweets》、《Visual Attention Model for Name Tagging in Multimodal Social Media》、《Multimodal Named Entity Recognition for Short Social Media Posts》、《Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer》。
Adaptive Co-Attention Network for Named Entity Recognition in Tweets(AAAI2018)
background
NER是NLP最基础且重要的任务之一,但是传统的NER都是只针对与textual content进行建模。在社交媒体上,很多的推文都是文字+图片的形式,并且社交媒体上的文字往往比较口语化、语法也比较informal、字数比较少、很多文字内容只有结合image才能理解,单纯对text进行建模,往往得不到很好的结果,而image对于NER提供了很好的辅助信息,所以如何利用image信息来进行NER,是一个非常重要的问题。这篇paper正是针对这样一个问题,构建了twitter数据集,并提出了ACN模型。
model
先放图~
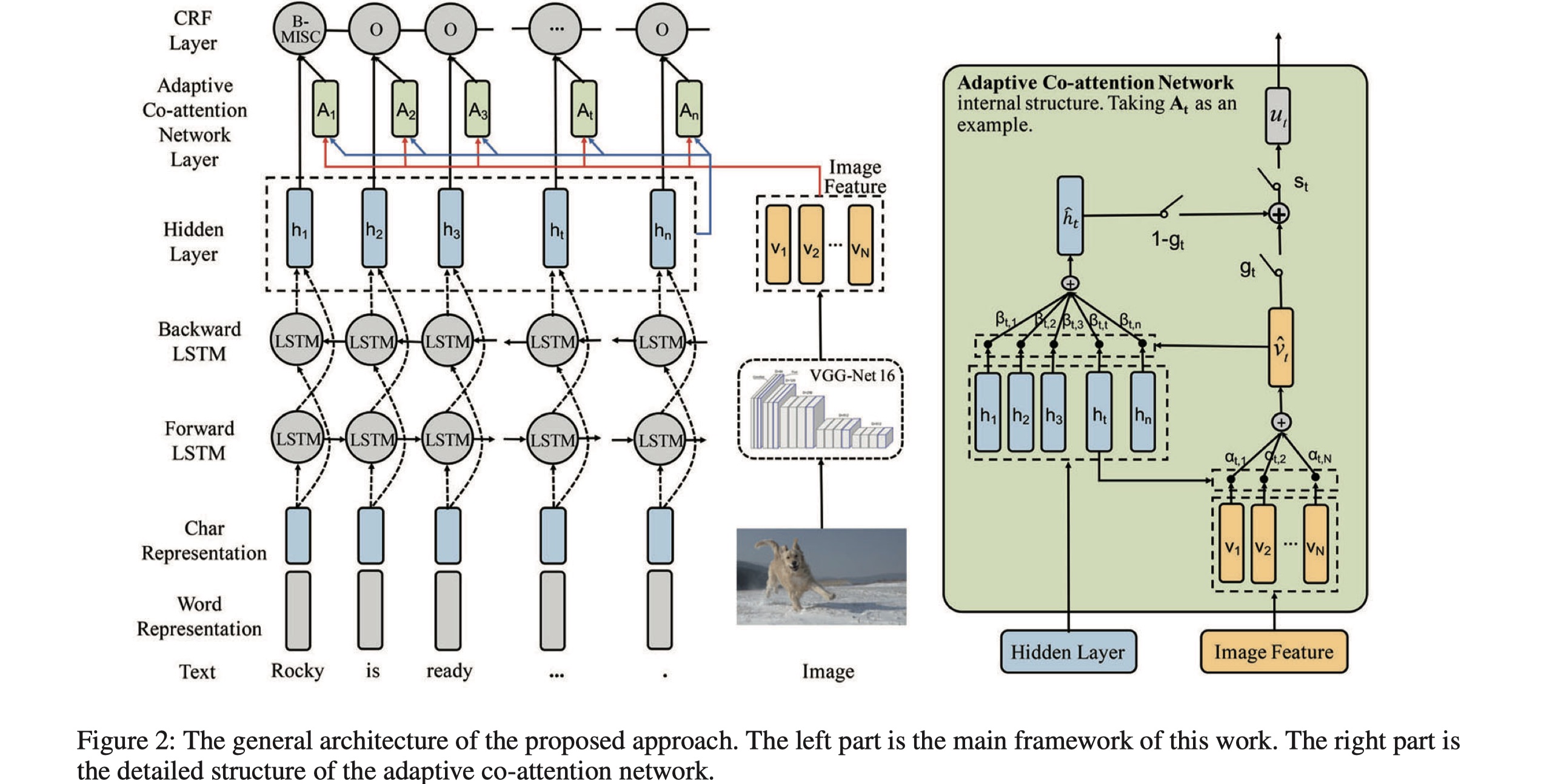
ACN模型主要分为三部分:feature extractor、adaptive co-attention netowrk、CRF tagging。
feature extractor:这一部分分为两个小部分:image feature extraction与text feature extraction。
- 对于image,采用VGG16来对iamge进行encoding,我们抽取最后一层的输出作为image的representation,表示为:$\tilde v_I=\{\tilde v_i|\tilde v_i\in R^{d_v},i=1,…,N\}$,其中$d_v$表示每一个region的维度,共有7x7个region,即:$N=49$,所以一张image输出的维度是:$N\times d_v$。为了能够与之后的text进行交互,维度与text相同,对其进行了非线性变换,并使用tanh进行激活,得:$v_I=tanh(W_I\tilde v_I+B+I)$,$v_I$是最终的image的representation。
- 对于text,是character-level word embedding与word embedding的concat。首先是character embedding,使用多个不同的cnn来对其进行编码,并使用tanh进行激活,然后对每一个结果使用max-over-time pooling,最后全部进行concat(常规操作了,没啥新颖的。),得到character-level word embedding:$w^{‘}$;将$w^{‘}$与$w^{‘’}$进行concat,得到$w$,将$w$输入到BILSTM,得到encoding后的句子的token的表示:$x=\{h_j|h_j\in R^d,j\in 1,2,…,n\}$,$n$表示句子的长度。
Adaptive co-attention network:在得到image与text的representation之后,我们希望将两者进行融合。但是对于sentence中的每一个token,不是所有的image region都有用,反过来也是一样的,对于image中的每一个region,不是sentence中的所有token都与其相关,那么一种很好的方式就是使用co-attention,即:image对text进行attention(word-guided visual attention)与text对text进行attention(image-guided textual attention)与。具体如下:
word-guided visual attention:不是所有的image region都与sentence中的token相关,如果将image中所有的信息全部给sentence,那么会引入很多噪音,损害模型性能。所以我们设计了word-guided visual attention,从而让模型自动过滤掉与sentnece无关的image region,只留下最相关的region。公式如下:
注意,$v_I\in E^{N\times d_v}$,$h_t\in R^d$,最终的$\tilde v_t\in R^{d’}$。
image-guided textual attention:除了image中的信息外,我们还希望对text本身进行建模,也就是在text中找到与每一个token相关的words。做法是:在word-guided visual attention的基础上,继续使用相似的co-attention机制,来得到新的结果。具体如下:
但实际上,这种做法并不是很好,有没有更好的?当然有啊,BERT!今年ACL2020的UMT模型就使用BERT来做,取得了很大的提高。
Gated multimodal fusion:得到attention之后的$\tilde v_t$与$\tilde h_t$,$t=1,…,n$,然后我们设计GMF机制,来过滤一些信息。公式如下:
Filtration gate:由于image的信息不是必须的,而text的信息是必须的,所以在最终输入到CRF之前,需要再次调整两者的比重。具体如下:
从公式中可以看出,$s_t$控制着image信息的比例,当我们不需要image信息的时候,我们就让其越接近于0,如果越需要image的信息,我们就让其越接近于1。
CRF tagging:没什么可讲的,就是标准的CRF层。
experiment
数据集:twitter数据集(released by this paper)
结果
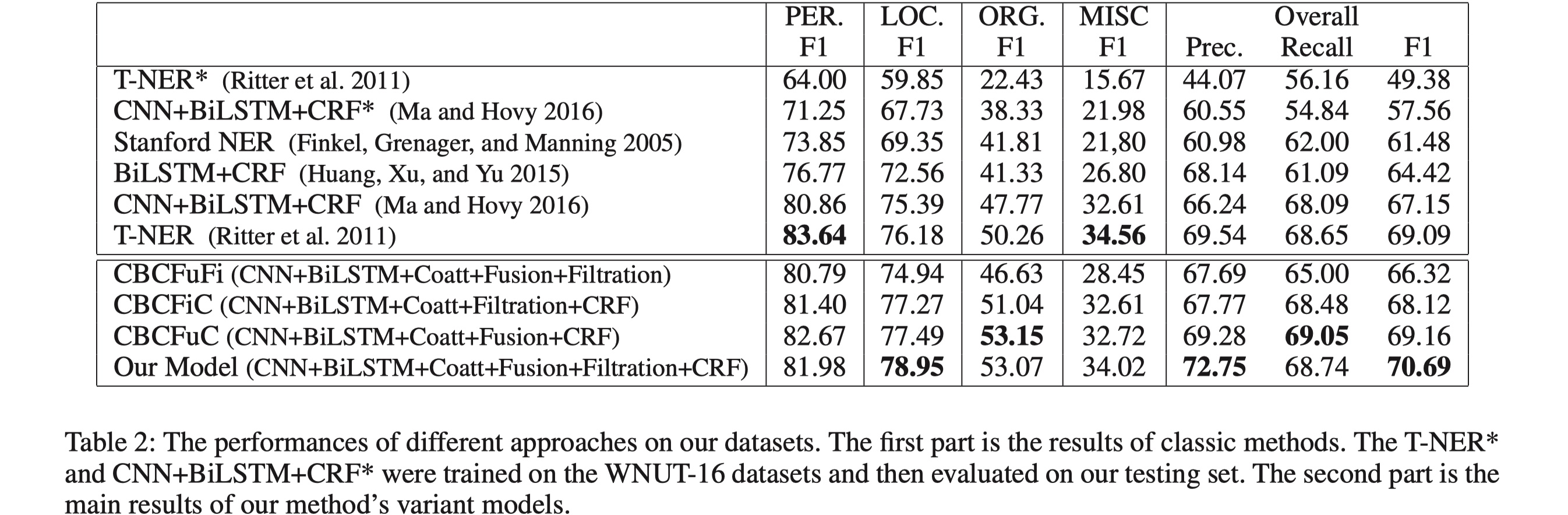
可以看到,这篇paper提出的model效果还是可以的,另外·,从ablation实验中可以看到,各个component设计的还是比较合理的,总之是一片很经典的论文,值得多读一读。
Visual Attention Model for Name Tagging in Multimodal Social Media(ACL2018)
background
这篇paper同样是针对multimodal NER,针对的问题也是一样的:如何更好的利用image信息来复制NER任务?在这篇paper中,设计了一种的新的attention机制和gate机制,从而取得了SOTA的结果。
model
先放图~
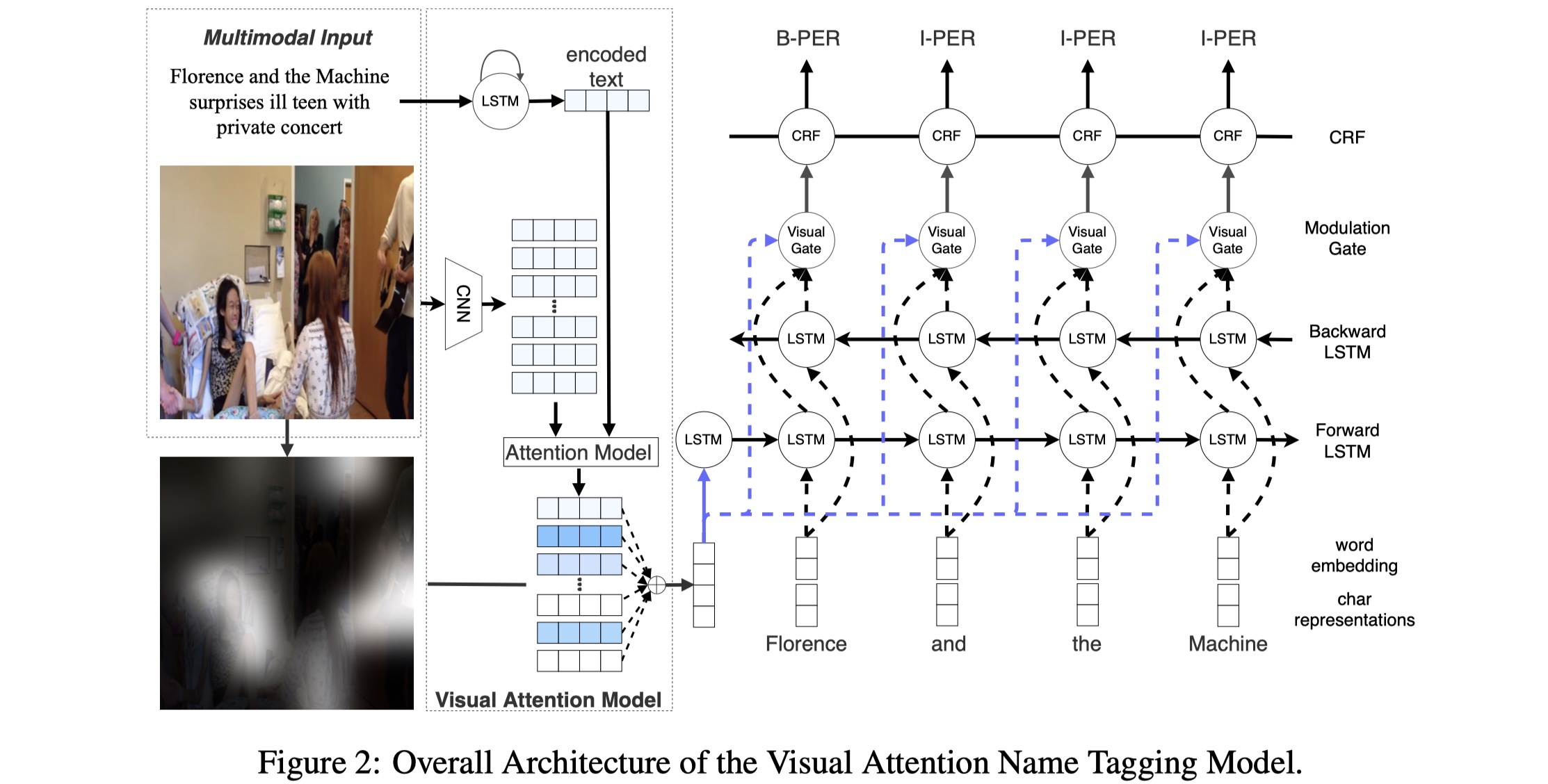
GVAtt的整体结构分为部分:feature representation、Visual attention model、visual modulation module。
feature representation:分为两部分:text representation与visual representation。对于前者,是word embedding与character-level word embedding的concat。所谓的character-level word embedding是指将character embedding输入到BILSTM当中(常规操作)。对于后者,采用的是ResNet,保留两部分:$V_g$与$V_r$,$V_g$是指最后的全连接层的输出,维度是:$V_g\in R^{1024}$,$V_r$是输入到最后的全连接层之前的输出,其维度是:$V_r\in R^{1024\times 49}$。这里之所以保留了两个,是因为后面做了实验比较,并不是整张image都与sentence相关,不相关的部分反而会引入噪音。
visual attention model:这一部分主要是要解决:对于sentence中的每一个token,如何保留与其最相关的image region,并且去除与其不相关的region?即:提取出与sentence中相关的image region feature,具体公式如下:
其中,$S$表示feature representation中的concat后的text embedding,最后得到的$v_c$最为之后的BISLTM的初始输入。另外再提一句,这里之所以使用的是$V_r$,是因为之后的实验表明了使用$V_r$的效果要比$v_g$更好。
visual modulation module:设置这一层的目的是:将第二步提取出的visual信息与text embedding进行结合。首次将第一步得到的text embedding输出到BILSTM当中,得到$h_i$;然后仿照LSTM的更新方式,设计了gate机制,具体如下:
最终计算得到的$w_m$作为CRF层的输入,CRF就是标准的CRF层,这里不再赘述。
experiment
数据集:twitter、snap captions
结果
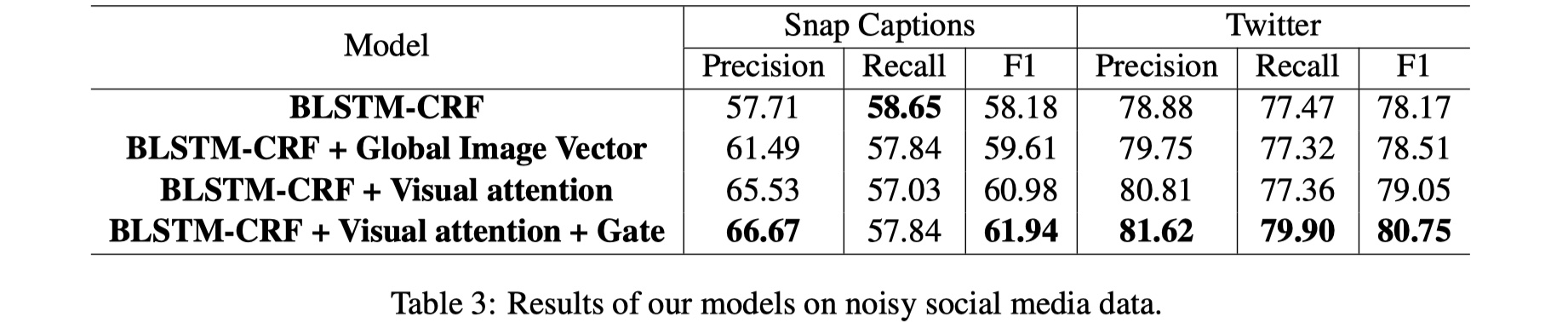
从结果来看,很不错,虽然paper里面没有个ACN模型进行对比,但是从twitter数据集结果来看,F1值高了近10个百分点!nb!
Multimodal Named Entity Recognition for Short Social Media Posts(NAACL2018)
background
这篇paper也是针对multimodal NER,解决的问题也是两个:1.social media上的tweets是非常不规范的、informal并且字数较少,所以一方面因为没有足够的信息会引起一词多义性问题,此外,由于不规范的使用,使得会产生很多未知的token,这个怎么解决?(其实现在来看就很好解决,上BERT啊);2.怎么让image与text更好进行交互?为了解决这些问题,就有了MNER模型。
model
先放图~
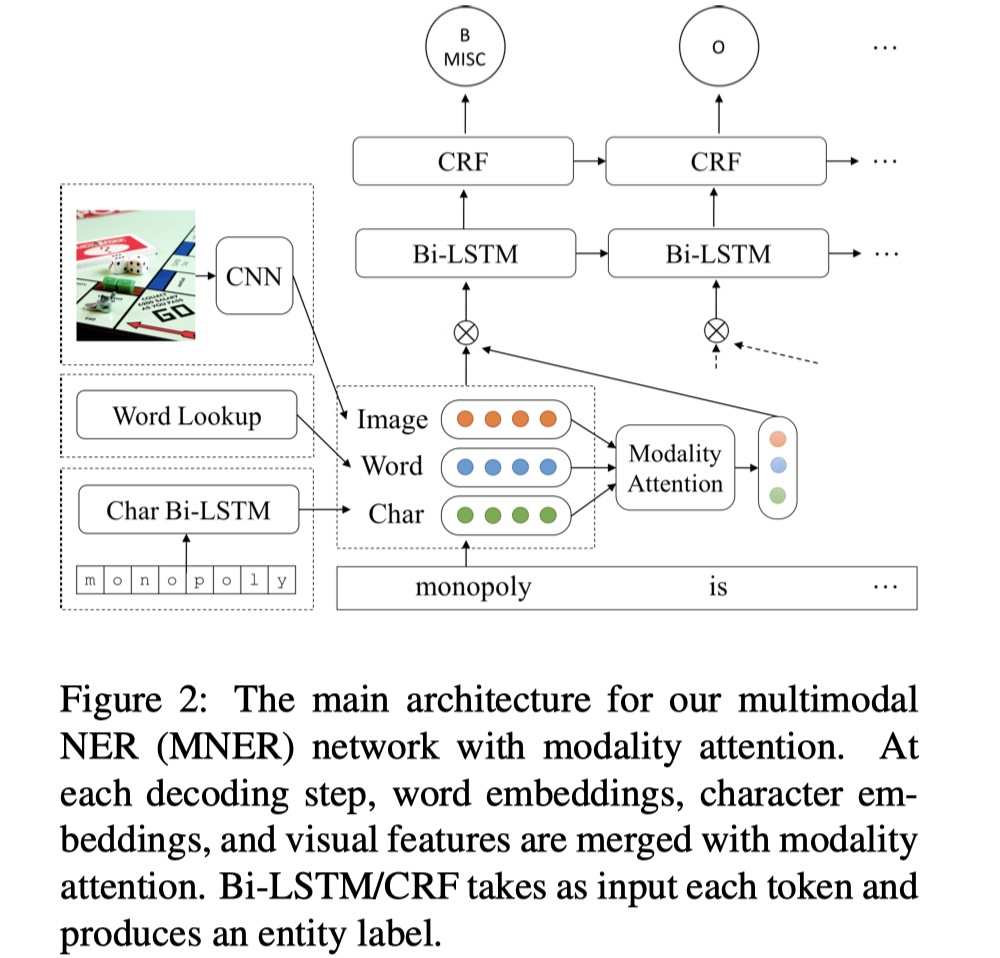
整体模型分为三部分:features、modality attention module、BILSTM+CRF。
task definition:输入的sentence表示为:$x=\{x_t\}_{t=1}^{T}$,其对应的标签是:$y=\{y_t\}_{t=1}^{T}$,每一个token由三种modality组成:$x_t=\{x_t^{(w)},x_t^{(c)},x_t^{(v)}\}$,分别表示word embedding、character embedding、visual embedding。
features:共分为三种:word embedding、character embedding、visual embedding。word embedding由GloVe初始化,并在training过程进行更新;character embedding是将character embedding送入BILSTM当中,得出的输出;visual embedding是使用GoogleNet的最后一层的输出。
modality attention module:在之前的paper中,大部分都是concat text与image的信息,然后再输入到CRF当中,但是concat的方式会损失信息,造成效果下降。为了解决这个问题,这篇paper分别对三个modality进行编码,再进行加权求和。具体公式如下:
$\overline x_t$是最终到BILSTM+CRF的输入。
BILSTM+CRF:这就是标准的BILSTM+CRF,不再赘述。
experiment
数据集:snap caption
结果
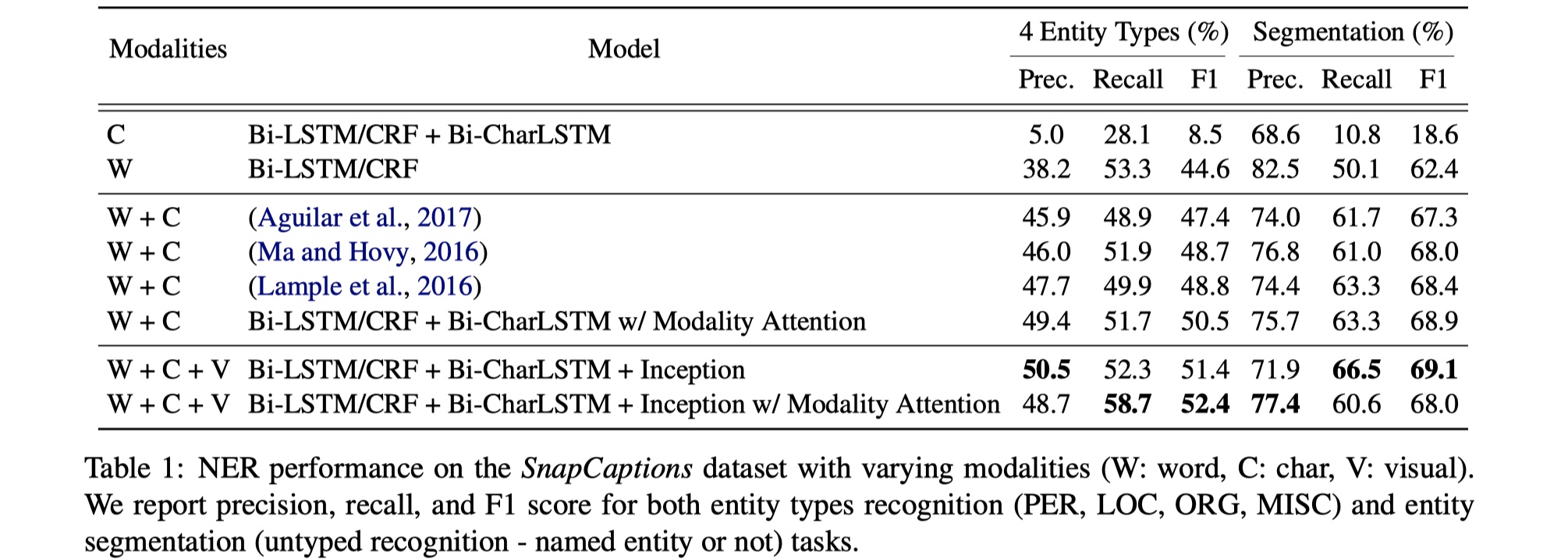
从结果来看,还行吧,没啥亮点。
Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer(ACL2020)
background
这是最新的multimodal NER的paper,主要解决的问题有:1.text与image的交互不够,即便能够得到简单交互后的结果,但是text对image context并不敏感;2.之前的研究并没有考虑image带来的bias。针对于第一个问题,这篇paper提出了MMI module,针对于第二个问题,这篇paper设计了ESD辅助任务来解决。具体的下面小节将详细的介绍。
model
先放图~
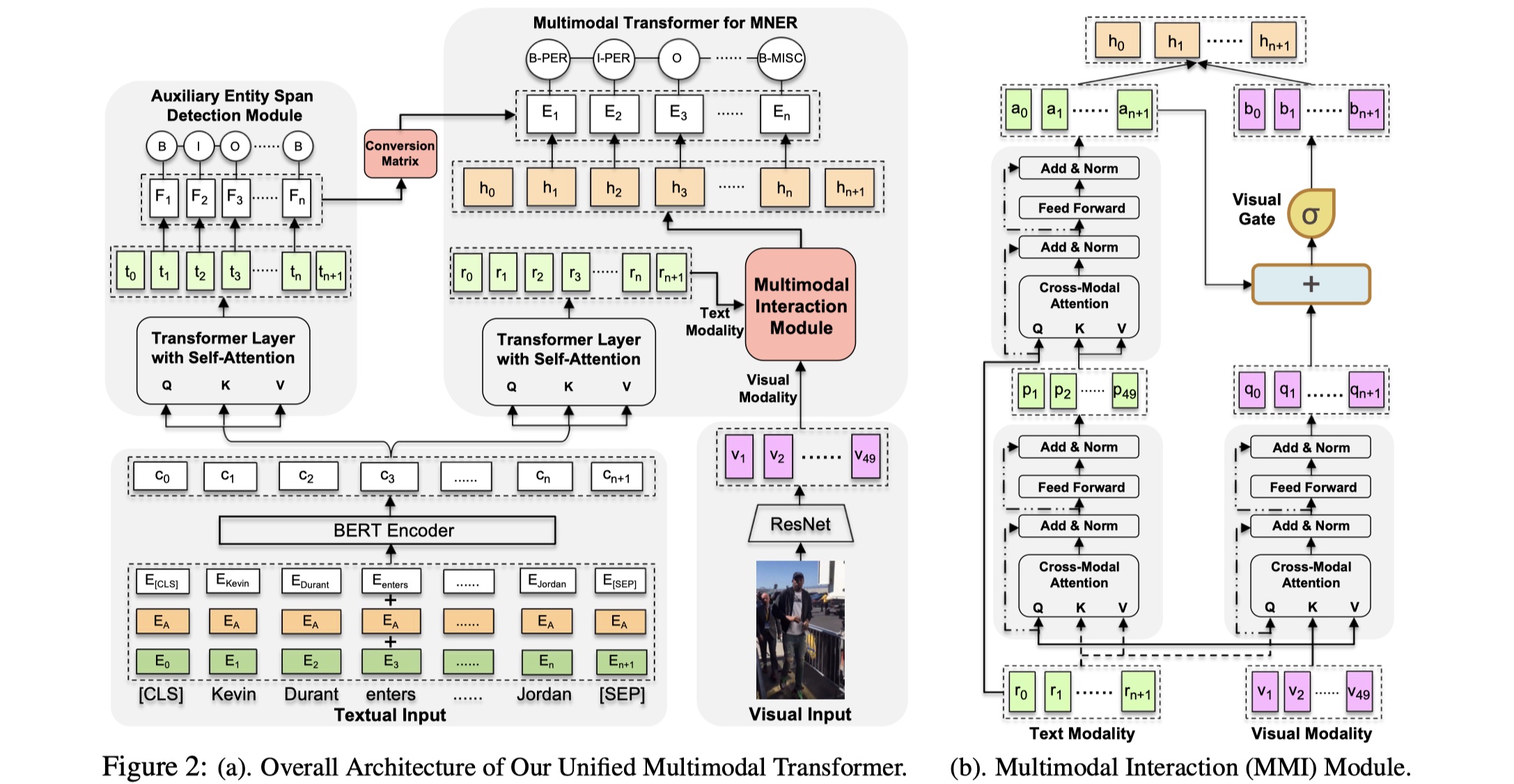
整体模型分为三部分:unimodal input representation、multimodal transformer、unified multimodal transformer。
unimodal input representation:主要分为两部分:word representation与visual representation。对于前者,paper中使用了BERT,一方面是能够得到更加强大的representation,另一方面也能够解决一词多义性问题。假设输入的句子为:$S^{‘}=(s_0,s_1,…,s_{n+1})$,其中$s_0、s_{n+1}$分别表示[CLS]与[SEP] token,通过三种embedding相加,得到的句子表示为:$X=(x_0,x_1,…,x_{n+1})$,通过BERT之后,为:$C=(c_0,c_1,…,c_{n+1})$,其中$c_i\in R^d$;对于后者,采用ResNet来对image进行编码,我们保留ResNet的最后一个卷积层的输出作为该image的representation,为:$U=(u_1,u_2,…,u_49)$,$u_i$表示一个region,且其维度是:$R^{2048}$,然后我们通过一个线性变换,让其维度与word representation的维度一样,为:$V=(v_1,…,v_{49}),v_i\in R^d$。
multimodal transformer:在正式对word与visual进行交互之前,我们首先对word representation再使用一层标准的transformer layer,我个人理解是增加非线性,不加其实也说的通,得到$R=(r_0,r_1,…,r_{n+1})$。接下来,设计了MMI module,让word与visual进行交互。具体分为两部分:image-aware word representation与word-aware visual representation。
image-aware word representation:这一步是image对word进行attention,得到更好的word representation。那么,就是$V$作为query,$R$作为key和value,使用m-head cross-modal attention,公式如下:
其中,$P=(p_1,…,p_{49})$。但是这个与我们最终想要得到更好的word representation的目标不一致,所以我们将$R$作为query,$P$作为key和value,再输入到一个与上述一样的transformer layer,得到$A=(a_0,a_1,…,a_{n+1})$。
word-aware visual representation:这里是word对visual进行attention,所以将word $R$作为query,$V$作为key和value,应用和上述一样的transformer layer,得到$Q=(q_0,q_1,…,q_{n+1})$。然后我们希望能够控制visual information的输入,所以有设计了visual gate,具体公式如下:
$B$就是最终的visual representation。
CRF:我们将$A$与$B$进行concat,并且输送到标准的CRF kayer当中。
unified multimodal transformer:在上一步的multimodal transformer当中,都是在关注如何对text和image之间的关系进行建模,但是这样很容易导致模型过分去关注image中有的entity,对于在sentence中但是不在image中的实体关注不够,因此为了解决这个问题,设计了ESD辅助任务,用来预测entity的type。假设一个句子的标注为:$z=(z_0,…,z_{n+1})$,其中$z_i\in \cal Z$,$\cal Z=\{B,I,O\}$,我们将其输送到一个transformer layer+CRF layer。然后我们想要将其辅助与最终的预测,所以设计了一个conversion matrix:$W^c\in R^{|\cal Z|\times |\cal Y|}$,其中$\cal Z=\{B,I,O\}$,${\cal Y}=\{B-PEC,I-PEC,…\}$,如果$\cal Z_j$不是$\cal Y_k$的相关label,那么$W^c_{j,k}=0$,否则为$W^c_{j,k}=\frac{1}{|C_j|}$。
experiment
数据集:twitter2015、twitter2017
details:训练过程中,resnet参数不更新,bert参数更新,seq_length为128,batch_size为16。
结果
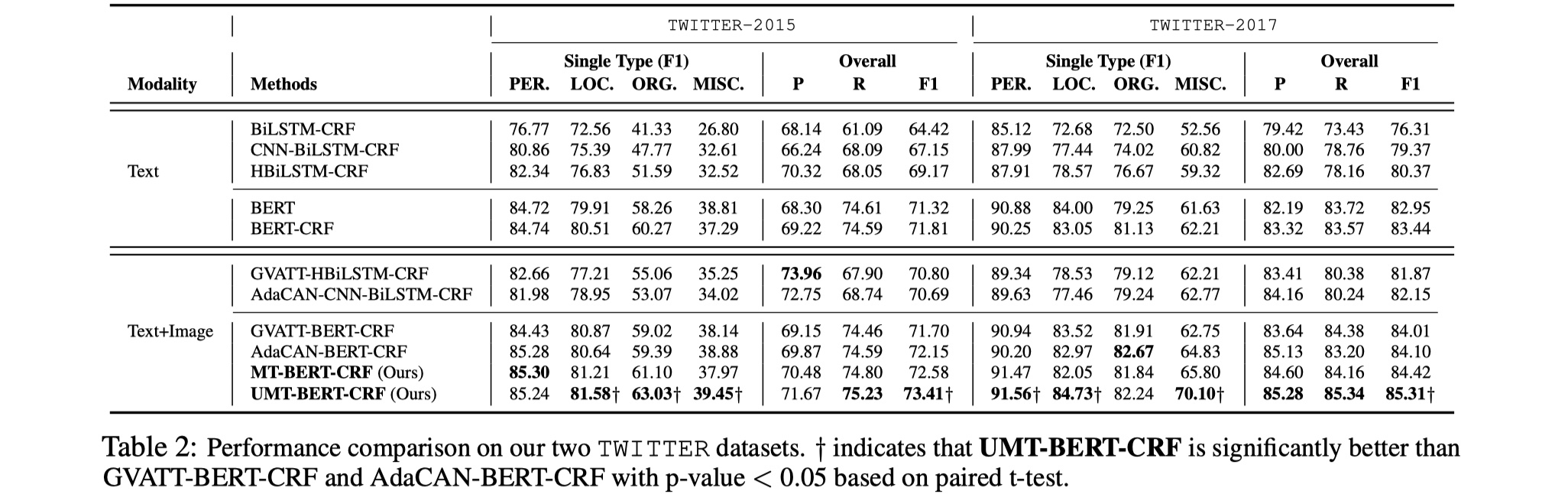
从结果来看,提升还是挺大的,个人觉得是得益于BERT的使用以及设计的ESD辅助任务,还是不错的。
消融实验
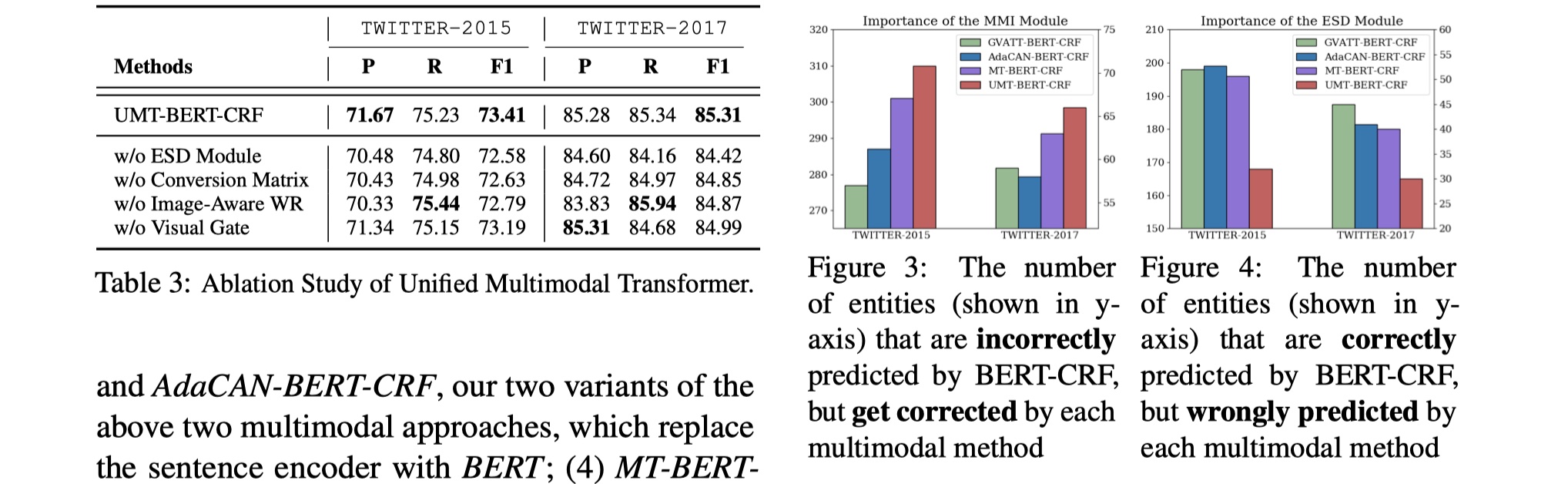
这是paper当中消融实验的结果,可以看到,在UMT模型中,各个component都比较重要,去掉都会有影响,但是相比来说,ESD辅助任务发挥了更大的作用,之后可以搞一波。
base case分析:在paper的base case分析中,主要的错误在于:当image与text完全不相关的时候,BERT-CRF预测会正确,而UMT预测错误,实际上就相当于image是噪音,在整个数据集中,大概有5%的比例。
小小的总结一下吧:对与Multimodal NER任务,目前主要的难点是:1.如何设计更好的机制,从而让token在image找到与其最相关的region?2.在1的基础上,怎么对text和image region更好地进行融合?3.image当中其实只有很少的实体,对于sentence中的其他实体,image其实并不能提供有效的信息,怎么去解决这种情况?4.当image与text完全不相关时,怎么解决?
references
《Adaptive Co-Attention Network for Named Entity Recognition in Tweets》
《Visual Attention Model for Name Tagging in Multimodal Social Media》
《Multimodal Named Entity Recognition for Short Social Media Posts》
《Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer》

