近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要讲解中文NER的Adaptive Embedding paradigm。所谓的Adaptive Embedding paradigm,指的是只在embedding部分进行改进,从而让我们不需要设计非常的复杂的结构,能够迁移到不同的模型结构上(RNN/CNN/transformer etc),所以这种方法的好处就在于其可迁移性。这篇文章主要讲解三篇论文:《An Encoding Strategy Based Word-Character LSTM for Chinese NER》、《A Neural Multi-digraph Model for Chinese NER with Gazetteers》以及ACL2020的《Simplify the Usage of Lexicon in Chinese NER》。
WC-LSTM模型
提出的背景
WC-LSTM模型是2019年发表在NAACL上的《An Encoding Strategy Based Word-Character LSTM for Chinese NER》论文。提出的背景还是因为LatticeLSTM模型。LatticeLSTM是词汇增强的典型模型,但是其存在一个很严重的问题:由于每一个sentence所被匹配到的word的数量与位置都不一样,所以导致LatticeLSTM模型无法batch训练与inference。在WC-LSTM中,为了实现并行化,需要对每一个character所匹配到的words进行编码,从而得到一个fixed embedding,再与character本身的embedding进行融合,最后输送到网络中进行训练。所以,关键就在于:怎么得到一个fixed embedding?下面具体介绍。
WC-LSTM模型介绍
先放图~
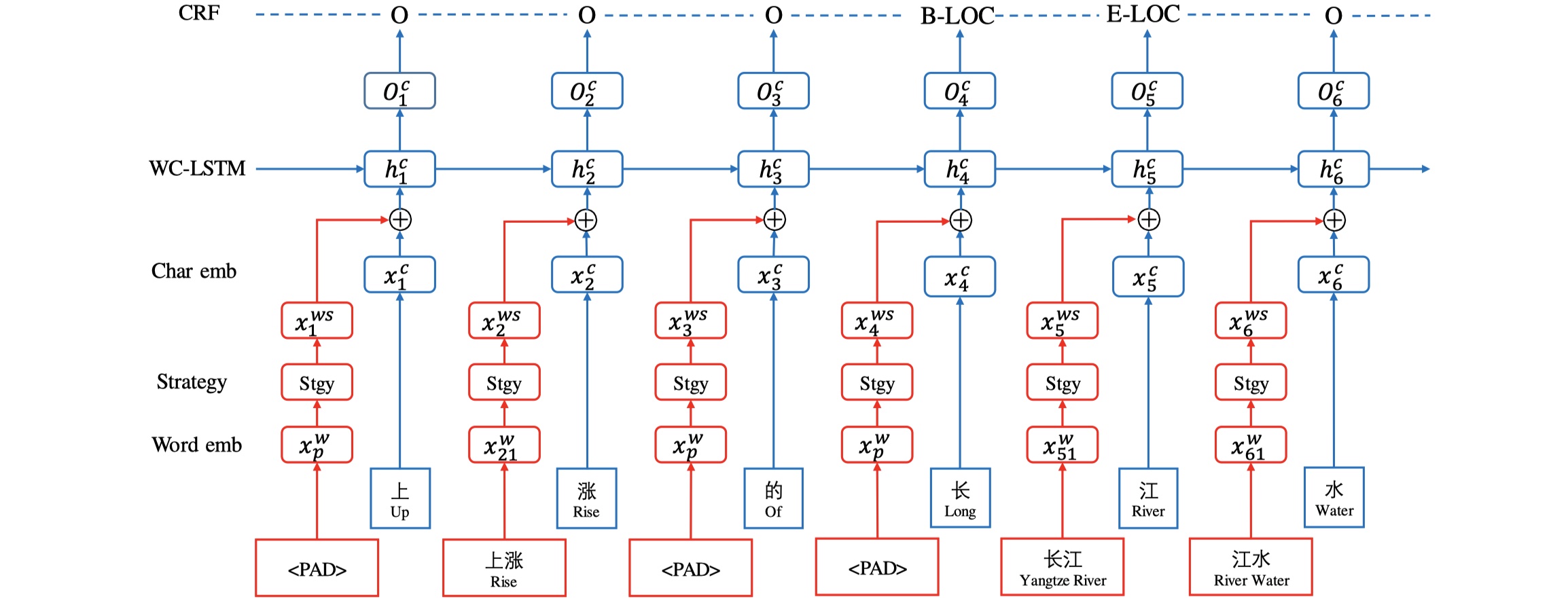
- input:输入有两部分:sentence以及与sentence相匹配的lexicon words,假设输入的sentence表示为:$s=\{c_1,c_2,…,c_n\}$,其中$c_i$表示sentence的第$i$个character;lexicon words表示为:$c_{b,e}$,在前向的wc-lstm中,使用$\overrightarrow{ws_i} $来表示以$c_i$的结尾的matched lexicon words的集合,后向的也是类似的。所以最终的输入是:$\overrightarrow{rs}=\{(c_1,\overrightarrow{ws_1}),(c_2,\overrightarrow{ws_2}),…,(c_n,\overrightarrow{ws_n})\}$,在WC-LSTM中,使用双向的LSTM,所以还有$\overleftarrow{rs}=\{(c_n,\overleftarrow{ws_n}),(c_{n-1},\overleftarrow{ws_{n-1}}),…,(c_1,\overleftarrow{ws_1})\}$。
- word-character embedding layer:在$\overrightarrow {rs}$中,对于每一个character $c_i$,对应一个lexicon words集合$\overrightarrow{ws_i}=\{\overrightarrow{w_{i1}},…,\overrightarrow{w_{s^p_i}}\}$,$\overrightarrow{ws_i}$中的word数目记为:$s^t_i$,对于一个batch来说,我门通过padding的方式让每一个sentence的相同位置有同样的$s^p_i$。每一个character的embedding,可以通过查pretrained char embedding table得到,记做:$x^c_i=e^c(c_i)$,每一个lexicon word的embedding也可以查表,记做:$x^{\overrightarrow{w}}_{il}=e(\overrightarrow{w_{il}})$。
- word encoding strategy:在WC-LSTM中,探索了四种encoding策略:最短词汇信息、最长词汇信息、avg、self-attention。最短词汇信息指的是:使用$c_i$中的词汇集合中长度最短的词作为$c_i$的词汇信息;最长词汇信息指的是:使用当前character的词汇集合中的最长的词作为$c_i$的词汇信息;avg是对所有的词汇信息进行简单的算术平均;self-attention就是自己对自己进行attention,比较简单。得到$c_i$的词汇信息后,将其与$c_i$的embeding进行concat,作为后续的输入。
- wc-lstm:这就是前向的LSTM的结果与后向的LSTM的结果进行concat,作为CRF的输入。
- decoding:使用标准的CRF层。
实验结果
- 数据集:OntoNotes、MSRA、Weibo、resume
- 实验结果就不放了,比Lattice只稍微好一点点,这也是预料之中的,毕竟wc-lstm的主要目的是并行化。
- 实验还探究了不同的encoding策略,最后得出的结论是:如果训练数据比较充足的话,建议使用self-attention和avg,因为这两个参数较多,如果训练数据比较少的话,容易过拟合,从而在测试集上表现不好;如果训练数据比较少的话,最短词汇信息和最长词汇信息分别适用于对嵌套实体与flat实体有要求的情况。(吐槽一下,这结论有啥用?我不做实验我也知道啊🐶)
Multi-digraph模型
提出的背景
Multi-digraph模型是2019年发表在ACL上的《A Neural Multi-digraph Model for Chinese NER with Gazetteers》论文。这个模型所关注的问题word conflicts,具体来说就是:在融合词汇信息的时候,如果有多个词汇表的话,不同的词汇表对于某些话有不同的匹配,这样的话对于句子中的character的标注就会有干扰,那么怎么很好地建模character与词典之间的关系以及怎么很好地融合不同词典的词汇信息?这就是multi-digraph模型提出的背景。
Multi-digraph模型介绍
先放图~
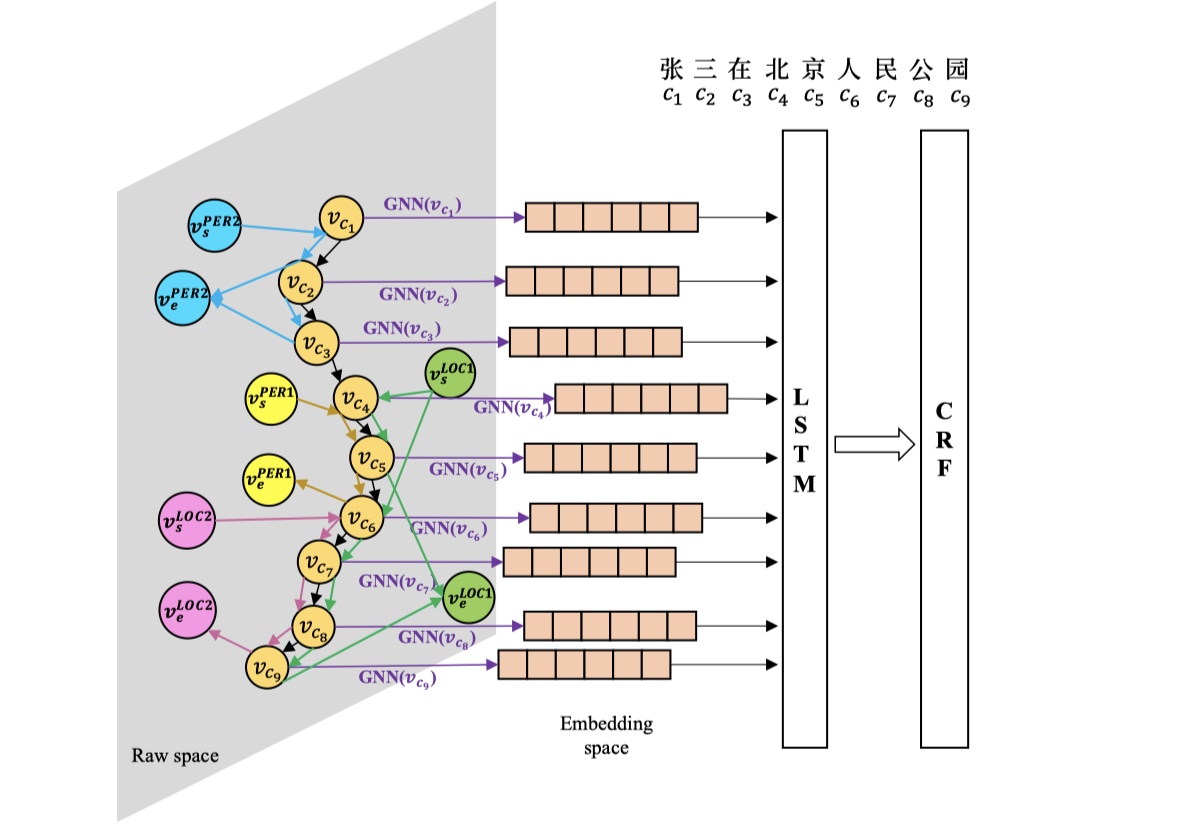
整体模型主要分为两大块:embedding部分+(LSTM+CRF)部分,第二部分没什么可讲的,主要介绍一下embedding部分。
embeding 部分主要是根据GGNN来进行构建。怎么构建图呢?首先明确模型的输入:sentence以及实体词典(gazetteer),那么node set就是:sentence中每一个chatacter作为node+每一种词典的每一类对应一对节点(起始与结束),上方有四种词典,因此有四对节点。在模型图中,raw space中五颜六色的箭头就是edge。构建好图后,就可以使用GGNN来进行aggregate,从而产生更好的node representation。下面介绍一下什么是GGNN,以及为什么要选择GGNN而不是其他的GNN。
GGNN:全称是Gated graph sequence neural networks,是一种spatial GNN,其aggregate的方式优点类似于GRU,如下:

其中,$h_v^{(1)}$表示的是初始的embedding,具体的可见link。从aggregate更新的方式来看,就是知道GGNN相比于GCN等GNN来说,最大的优势是比较适用于序列,能够更好地提取文本信息。不过说实话,这里使用GNN有点强行上的意思,没看出来为什么一定要用GGNN。🧐
实验结果
数据集:OntoNotes、MSRA、Weibo、E-commerce(released by this paper)
结果如下:
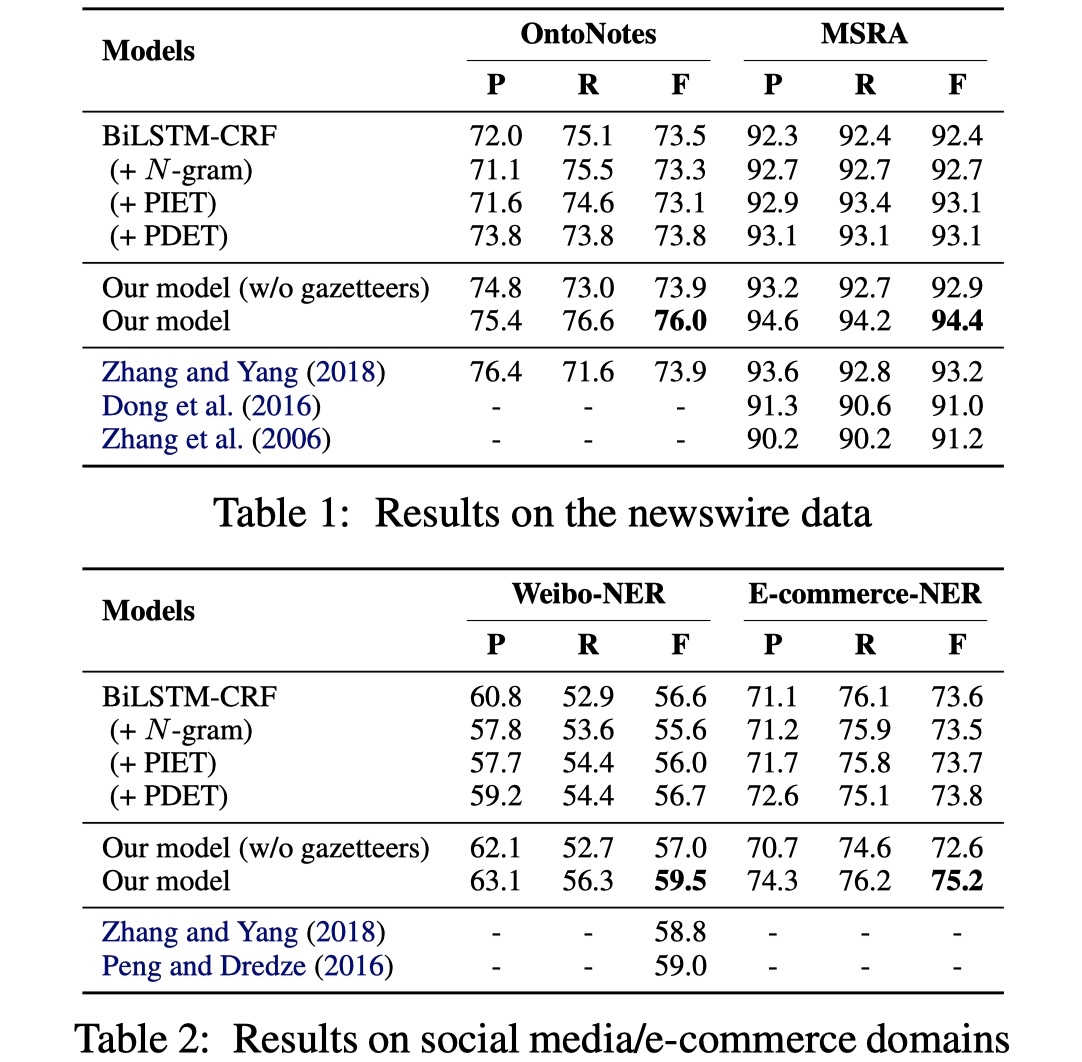
在OntoNotes和MSRA上的结果比大部分模型要好,在Weibo数据集上的结果要差一些,所以多加词汇表果然还是王道啊,不过相对的,估计也无法并行了吧。
SoftLexicon模型
提出的背景
像LatticeLSTM模型,它的缺点就是:1.模型结构过于复杂,无法迁移到其他架构上,而且无法并行化;2.并没有完全融入lexicon的所有信息,也就是有信息损失。针对第一点,softlexicon和wclstm模型一样,通过将character所匹配到的lexicon words编码为一个fixed vector,并与character embedding进行concat,作为后续模型的输入;针对第二点,softlexicon通过categorizing 所匹配到的lexicon words,从而避免信息损失。具体的在下面小节介绍~
SoftLexicon模型介绍
先放图~
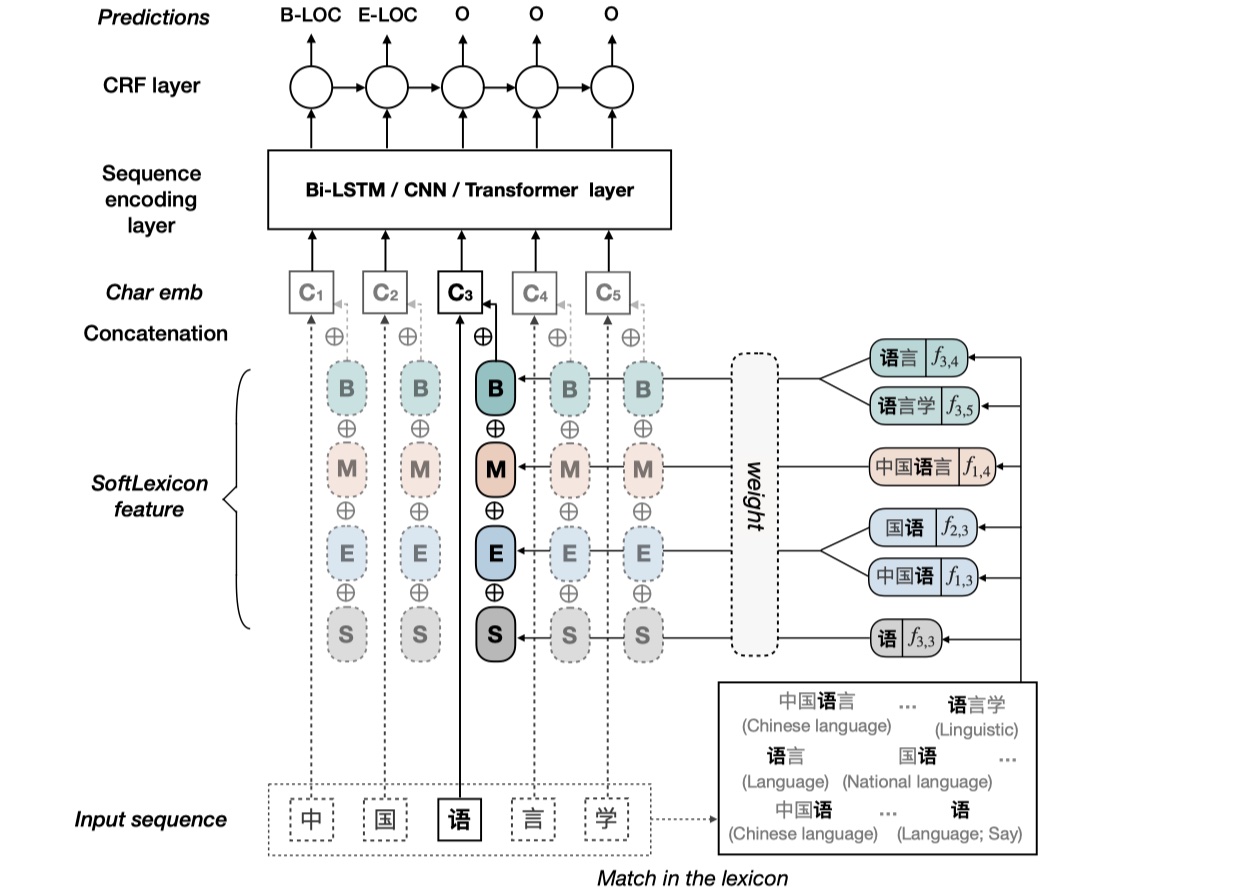
假设输入的sentence表示为:$s=\{c_1,c_2,…,c_n\}$,$w_{i,j}$表示sentence中与lexicon中相匹配的word。为了不损失任何信息,我们首先对所有的与character $c_i$相匹配的lexicon words都采用BMES来进行编码,从而每一个character都有4个word sets。其公式如下:
其中,$L$是lexicon,当然如果word set为空的话,那么会添加一个NONE进去。具体的例子如下:
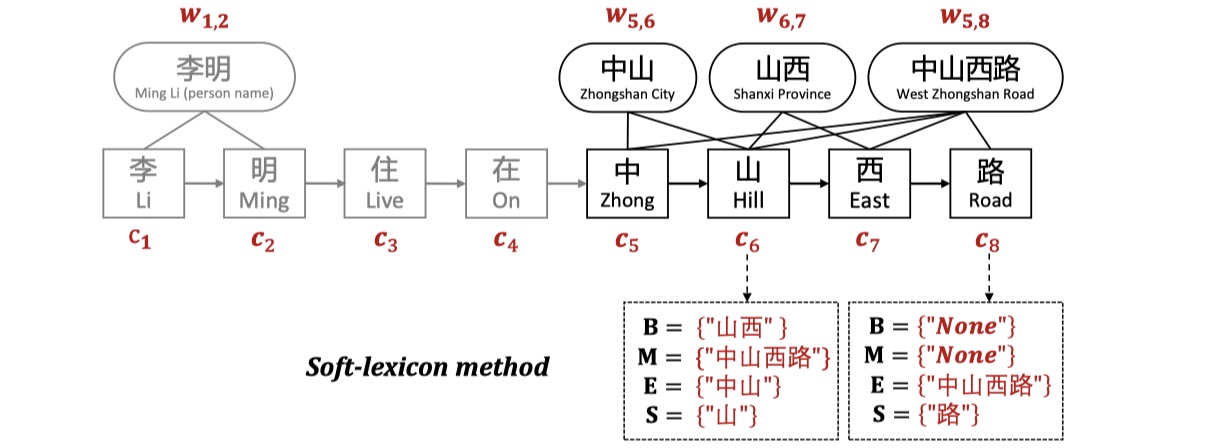
对于每一个character $c_i$,我们都能得到word sets。得到word sets之后,我们需要对word sets进行压缩。论文里实验了两种方法:mean-pooling与weighting method,实验表明后者要更好一些。具体来说,假设我们要计算character $c_i$的$B(c_i)$的representation vector,我们使用每一个word的frequency作为该词的权重,之所以这样做而没有使用像attention这样的方法,是因为想要提高速度。具体公式如下:
其中,$S\in \{B,M,E,S\}$,$z(w)$表示word $w$的词频。
分别得到BMES的representation vector之后,我们需要将其与character进行concat,具体如下:
然后将$x^c$输入到BILSTM+CRF中,得到最终的结果。
实验结果
数据集:OntoNotes、MSRA、Weibo、resume
实验结果

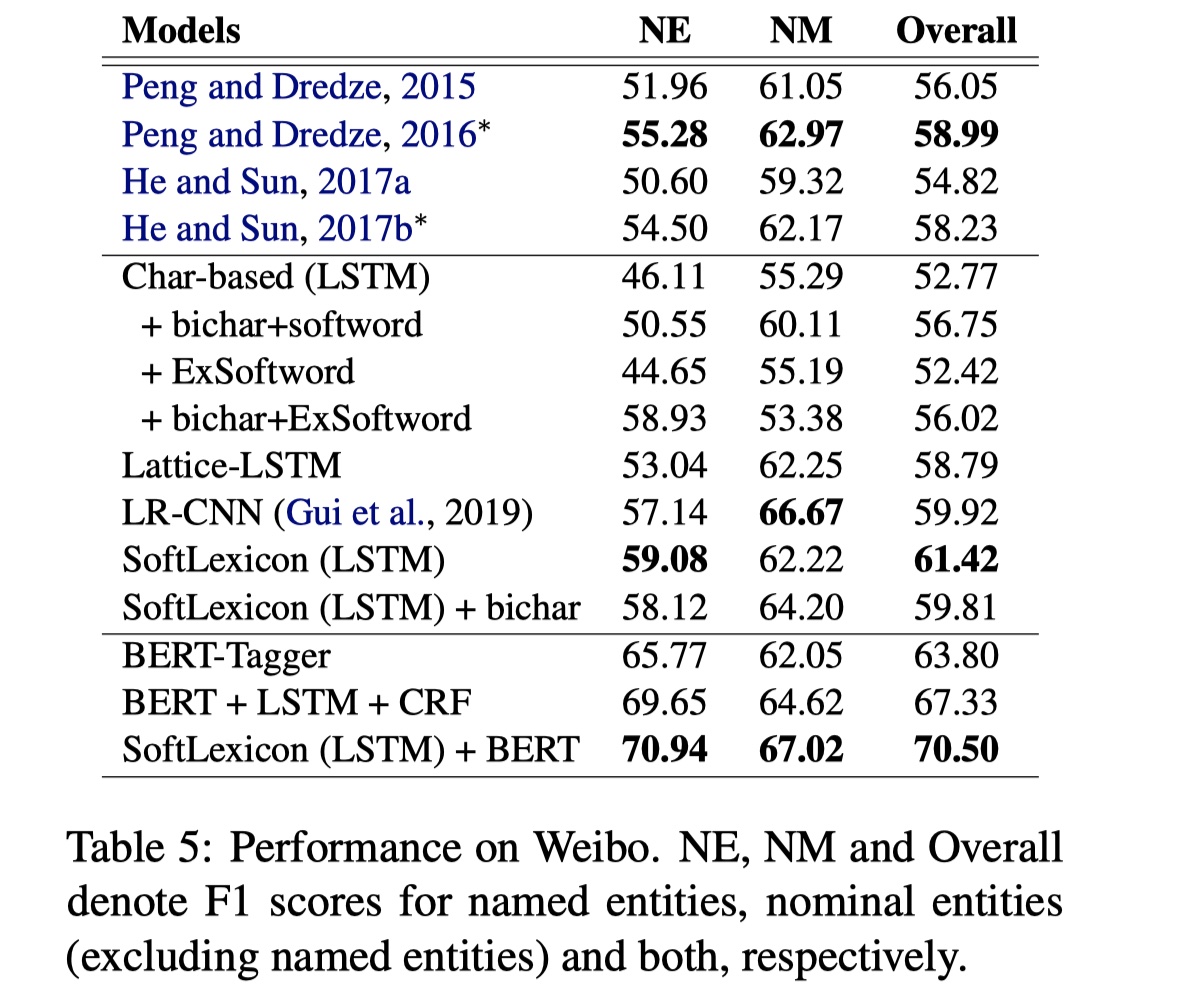
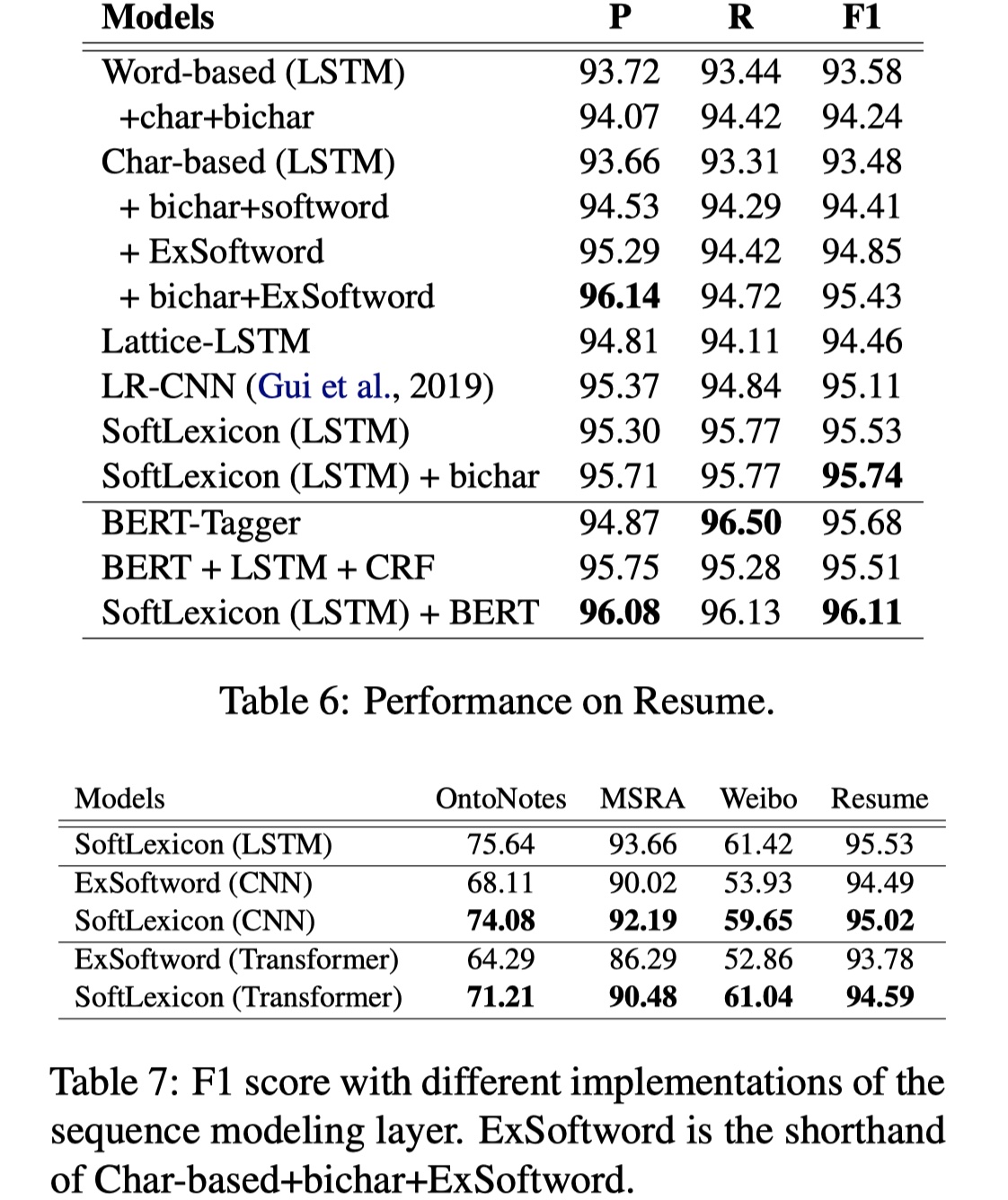
从结果上看,还是不错的,而且speed上有了很大的提升。
参考文献
《An Encoding Strategy Based Word-Character LSTM for Chinese NER》
wc-lstm code:https://github.com/liuwei1206/CCW-NER
《A Neural Multi-digraph Model for Chinese NER with Gazetteers》
multi-digraph code:https://github.com/PhantomGrapes/MultiDigraphNER
《Simplify the Usage of Lexicon in Chinese NER》
softlexicon code:https://github.com/v-mipeng/LexiconAugmentedNER
《GATED GRAPH SEQUENCE NEURAL NETWORKS》

