近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要讲解一下cross-lingual NER,解读今年MSRA发表的三篇论文:《Enhanced Meta-Learning for Cross-lingual Named Entity Recognition with Minimal Resources》、《Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language》、《UniTrans : Unifying Model Transfer and Data Transfer for Cross-Lingual Named Entity Recognition with Unlabeled Data》,以及附带的《GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition》。
Enhanced Meta-Learning for Cross-lingual Named Entity Recognition with Minimal Resources(AAAI2020)
background
当我们想要在target language上进行NER任务的时候,但是如果没有足够的labled data的话,cross-lingual NER是一种有效的方式。所谓的cross-lingual NER指的是,我们有labeled source language data与unlabeled target language data,我们希望模型在labeled source language上学习到的知识能够迁移给unlabeled target language,从而使得target language data在没有label的情况下,也能够取得很好的结果。目前已有的cross-lingual NER model主要分为两种方式:methods based on direct transfer 与methods based on annotation projection。
- 所谓的methods based on direct transfer指的是:我们使用source language data去训练一个NER model,然后直接在target language data上进行test,这种方法的关键在于:怎么得到并在模型中融入一些language-independent feature,常用的是:cross-lingual word embedding,word cluster等等。
- 所谓的methods based on annotation projection指的是:我们将source language data在word level/phrase level上给他翻译成target language data,当然label也是copy过去,然后模型使用翻译后的target language data进行训练,最后在原有unlabeled target language data进行test。
本篇paper提出的方法属于第一种,因为作者认为这种方法还有提升的空间。为什么呢?因为最近有paper显示:通过建立一个cross-lingual encoder,任何句子都能够被encode到同一个feature space。另外,在mBERT中,还给出了这样一个结论:通过mBERT,我们可以通过简单的余弦相似度来计算不同语言的句子的similarity,这样的话,给定一个target language example,我们就能够在source language data中召回出一些与其在结构/语义上相似的句子。所以在正式对unlabeled language data进行test之前,我们是不是可以在source language data中找到与给定的unlabeled language data中相似的那些sample,从而使用这些sample来对模型进行fine-tuning,来提升效果?答案是肯定的!此外,召回的example会是一个比较少的数目,从而避免引入额外的噪音,伤害模型的性能。到此,cross-lingual NER任务就转化为了:模型需要在一个小数目的训练集上进行训练,并在新的target language上取得比较好的结果。这就很自然地引入了meta learning。
model
首先简单的介绍一下什么是meta learning。所谓的meta learning,也叫做LTL(学会学习),它适用于:模型只需要使用少量数据进行训练,就能够快速在适用于一个新的任务,它强调的是fast adaptation。目前常用的meta learning算法,主要分为三类:leanrning a metric space 、learning a good parameters initialization、learning an optimizer,本篇paper采用的MAML算法属于第二类。OK,点到为止,下面将讲解如何利用meta learning来进行cross-lingual NER任务。
问题定义
我们把labeled source language data记做: $D^S_{train}=\{x^{(i)}\}_{i=1}^{N}$ ,unlabeled target language data记做:$D^T_{test}=\{x^{(j)}\}_{j=1}^{M}$。我们的目标是:希望使用$D^S_{train}$来训练一个模型,从而让模型能够在$D^S_{test}$有着很好的效果。
Base model:使用预训练的mBERT,同时添加一个softmax用于token解码,损失函数采用CE。
enhanced meta learning approach:在这篇paper里,使用MAML算法来进行meta learning。不了解的MAML算法请看这个link。整个算法其实分为三部分:task的构建、meta-training(在MAML中就是预训练阶段)与adaptation(在MAML中就是微调阶段)。
task的构建
在执行MAML算法之前,我们需要构建task,因为在MAML中,一个task就相当于一个样本。对于$D^S_{train}$中每一个样本$x^{(i)}$,我们将其本身当作meta task $\tau_i$的测试集$D^{\tau_i}_{test}$(其实就是query set),从source language data召回的与$x^{(i)}$最相似的样本的集合作为meta task $\tau_i$的训练集$D^{\tau_i}_{train}$(其实就是support set),所以每一个meta task $\tau_i$可以表示为:
具体怎么召回呢?其实就是通过mBERT得到$x^{(i)}$的sentence presentation,然后计算$x^{(i)}$与$x^{(j)}$的余弦相似度,选取最相似的K个样本即可。
meta-training
这一步可以看作是预训练,模型在多个不同task进行训练,从而能够让模型获得很强的泛化能力,之后在目标task当中,我们只需要fine-tuning很少的次数,就可以得到很好的结果,也就是fast adaption。这一步核心的东西叫做:gradient by gradient。具体就是:我们随机sample一些task作为一个batch来训练模型的参数$\theta$,在这一个batch的参数更新的时候,是一个样本一个样本来进行参数更新的,等到一个batch结束后,我们就得到了一个新的参数$\theta^{‘}$,然后用$\theta^{‘}$来更新最原始的参数$\theta$。当然了,预训练可以执行很多次。
adaptation
这一步是模型在target language data上进行微调。当然了,具体的task的构建方法也是第一步说的一样,不过使用的样本全部来自于target language data。值得注意的是,这一步中我们只有一次的参数更新。整体的架构图如下:

当然了,由于不同语言的句子之间的对齐很重要,为了让模型能够学习到这种对齐,model还在token-level上对entity进行了mask。还有一个max loss的操作,具体就是:传统的CE loss,它对每一个token 的loss都是平等对待,但是这是不对的,不同的token它对整体的loss贡献是不一样的,所以我们可以减去所有token loss中最大值,从而让那些loss 比较高的token能够学习的更加充分。当然在本paper里没有使用,因为本来训练数据就少,没有必要,而且这样搞很容易过度学习了,从而伤害模型的性能。
experiment
数据集:CoNLL-2002/2003、Europeana Newspapers、MSRA,en作为source language,其他语言作为target language。
实验结果
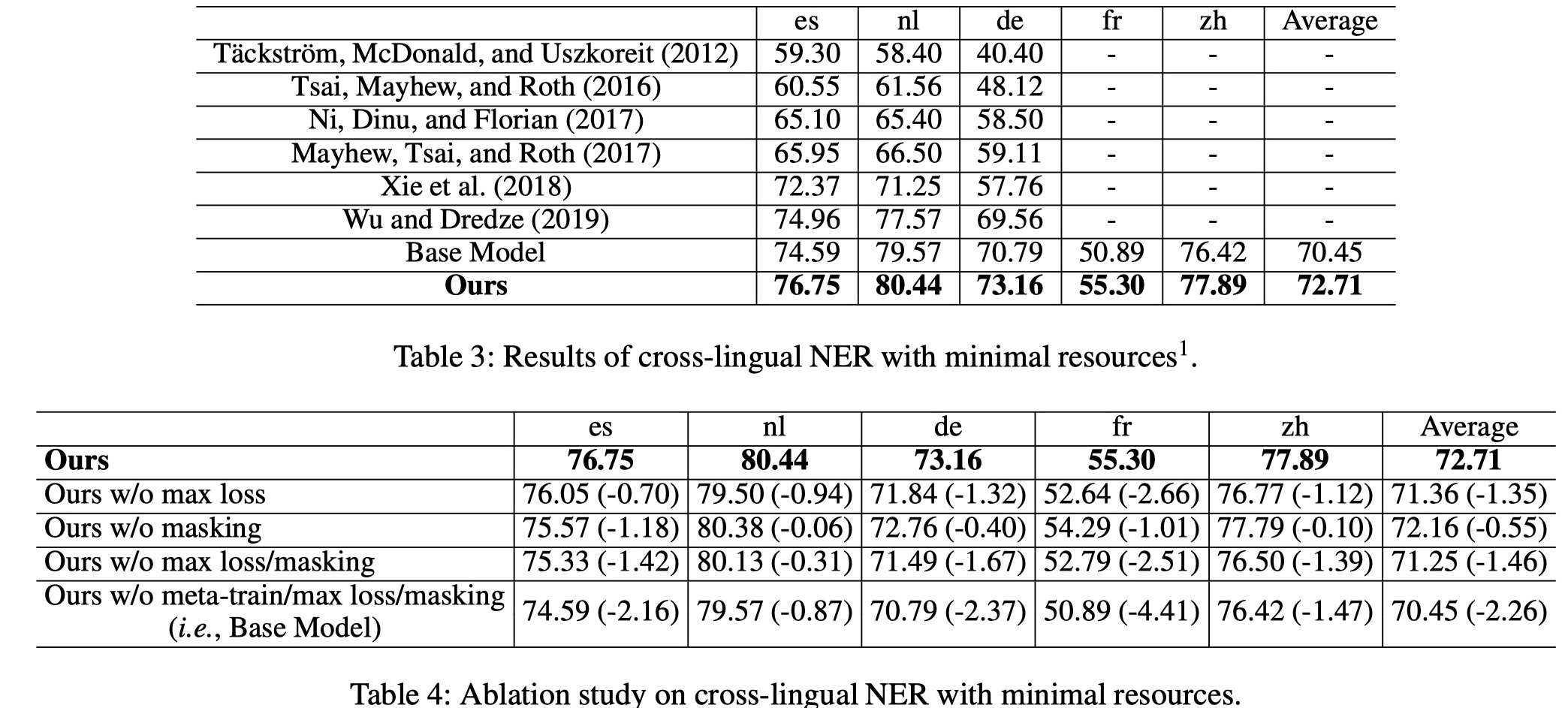
从结果来看,还是不错的。个人认为这种思路还是蛮新颖的。
Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language(ACL2020)
background
这篇论文假设的任务更加的严苛:之前的cross-lingual NER都是有可用的labeled source language data,那如果没有可用的labeled source language data,要怎么样才能在unlabeled target language data上取得好的效果呢?它首先对在cross-lingual NER上两种方法进行了对比:
- methods based on direct transfer缺点的在于:没有很好地利用unlabeled target language data,并且模型效果非常依赖language-independent feature;
- methods based on annotation projection的缺点在于:需要parallel text of target language data,一般都是通过对source language data进行翻译得到,这样以来,难免会引入噪音,对最终模型的性能存在损害,同时这种方法对于zero-source cross-lingual NER的情况不适用。
对两种方法进行分析之后,我们希望构建的模型,能够处理zero-source cross-lingual NER这种情况,同时能够很好地利用unlabeled target language data中的信息。具体的做法是:采用teacher-student learning(借鉴了知识蒸馏)。
model
整个模型分为两大情况:single source cross-lingual NER和multi-source cross-lingual NER,都是采用teacher-student learning的方式来进行训练。
single source cross-lingual NER
training:对于single source cross-lingual NER,我们把在source language上训练好的模型作为teacher model。具体在这篇paper里面,选取mBERT作为teacher model,student model可以与teacher model一样的结构,也可以是不一样的结构。我们把使用后unlabeled target language data去训练student model,让其去模拟teacher model输出的实体标签的分布。损失函数采用MSE,解码使用softmax。注意,训练过程中,我们不去更新teacher model的参数。模型图如下:
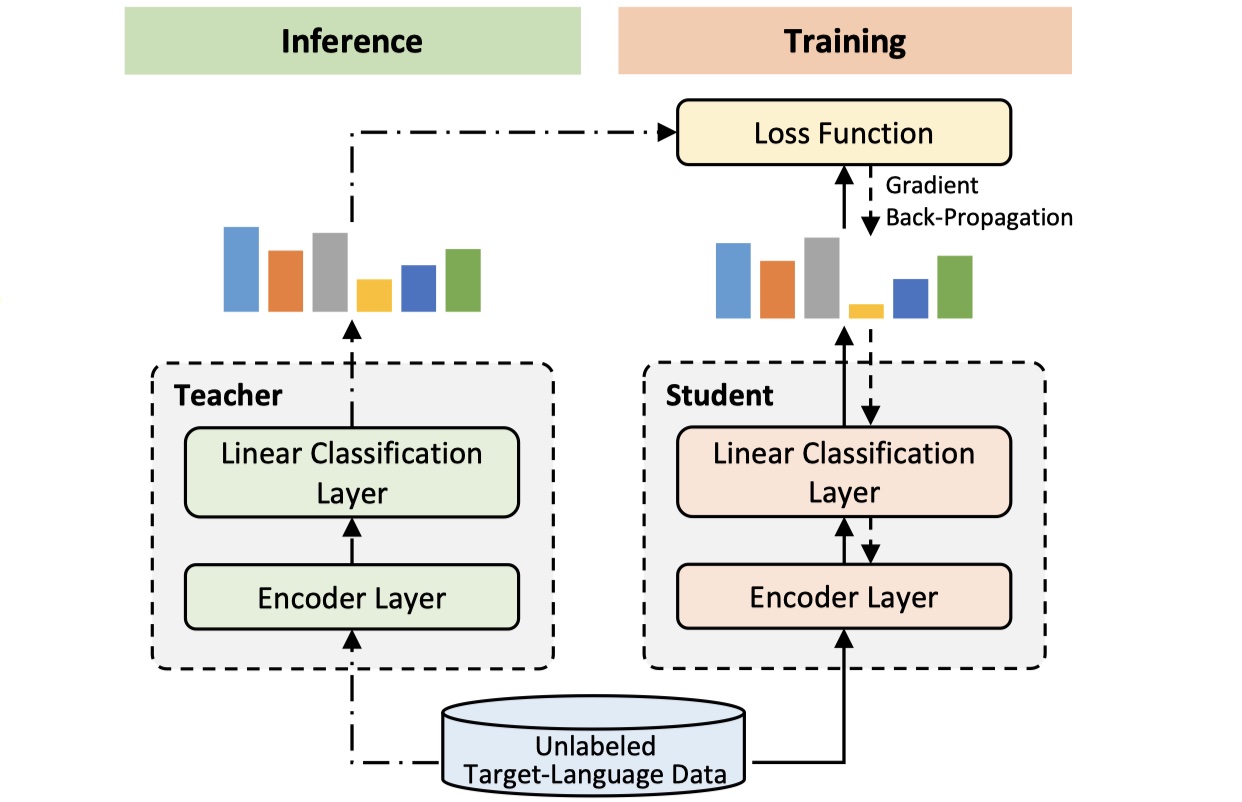
inference:我们只使用srtudent model 来进行inference,解码仍然采用softmax。
multi-source cross-lingual NER
training:对于multi-source cross-lingual NER,我们把K个在source language data上训练好的模型当作teacher model(注意,共有K个model,每一个模型在一种source language上训练过),sutdent model的结构仍然可以相同或者不同。但是与single source cross-lingual NER不同的在于,student model是要拟合teacher model的输出的分布,而teacher model有多个,需要对多个teacher models进行融合,实际上就是多个teacher model的输出的概率分布进行加权融合,权重就是不同teacher models的相对重要性。公式如下:
其中,$\tilde p(x_i^{‘},\theta_T^{(k)})$表示第$k$个teacher model的输出概率分布,$\alpha_k$表示第$k$个teacher model的权重。关键是$\alpha_k$怎么计算呢?在这篇paper中,设计一个language identification auxiliary task,来计算$\alpha_k$。
language identification auxiliary task
这个任务通过学习得到不同language的language embedding,来计算source language与target language的相似度,从而给各个teacher models分配权重。假设第k种source language的数据集表示为:$D^{(k)}_{src}=\{(u^{(k)},k)\}$,我们要做的是:去学习所有的 source language embedding vector:$\mu^{(k)}\in R^m,k\in 1,2,3,..,K$。具体公式如下:
其中,$P\in R^{m\times K}=\{\mu^{(1)},\mu^{(2)},…,\mu^{(K)}\}$,K表示K种语言,m表示其embedding dimension,$g^T(u)$表示得到$u$的sentence embedding,$k$我个人觉得是一个one-hot vector,要不然不对劲。得到$P$之后,我们就可以计算$\alpha$了,如下:
其中,$|D_{tgt}|$表示target language data中的样本数目,$\tau$设置为所有的$g^T(x^{‘})M\mu^{(k)}/\tau)$的方差,从而保证得到的$\alpha$不会为0也不会为1。总的来看,这个任务还是蛮简单的,但是很work。值得一提的是,在实际实现的过程中,对$M$使用了低秩近似,从而减少参数量,加快训练。
inference:还是只使用student model来进行inference,解码使用softmax。
experiment
数据集:CoNLL-2002、CoNLL-2003
hypoparameters的设置参考原始论文
实验结果
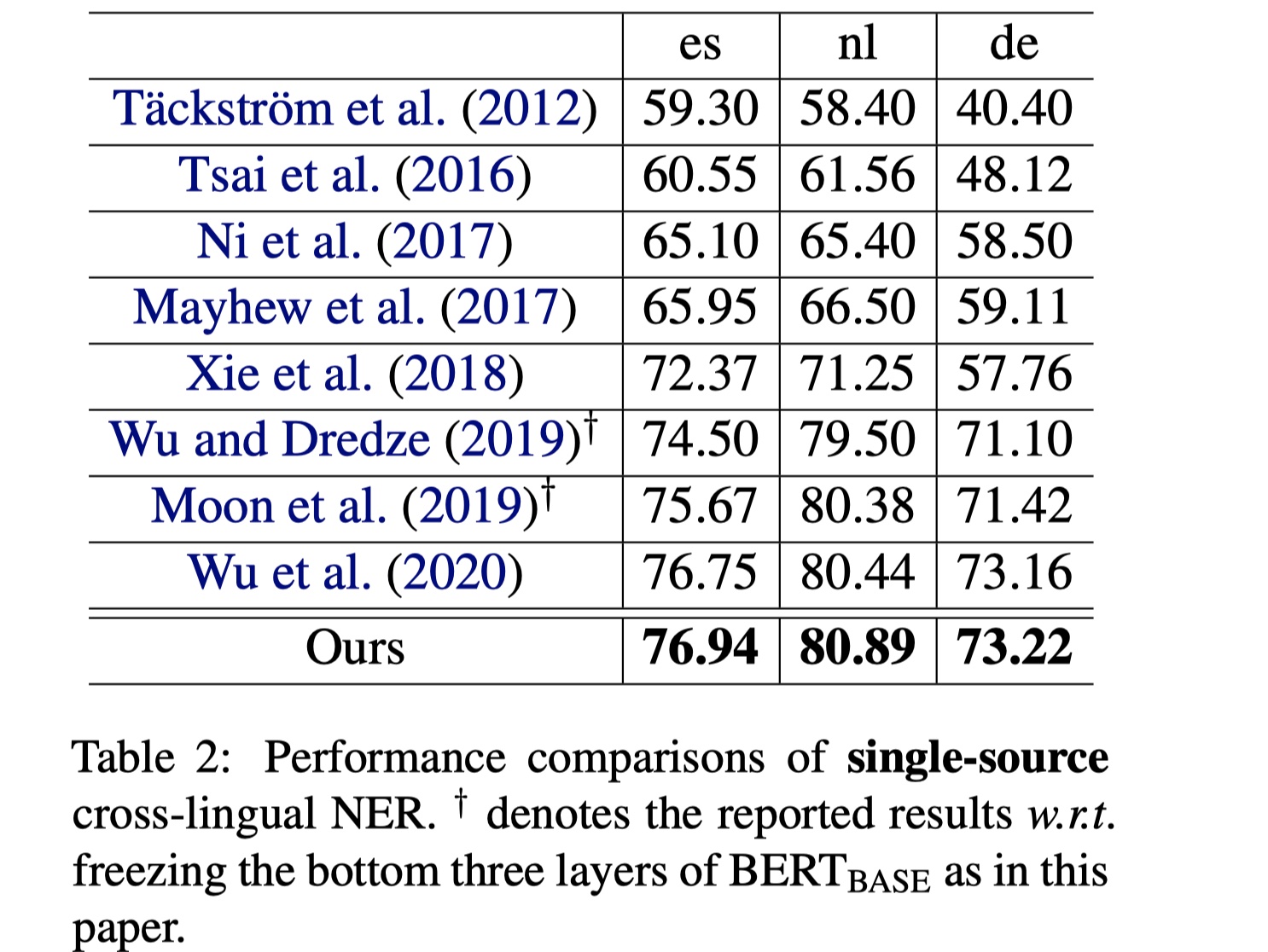
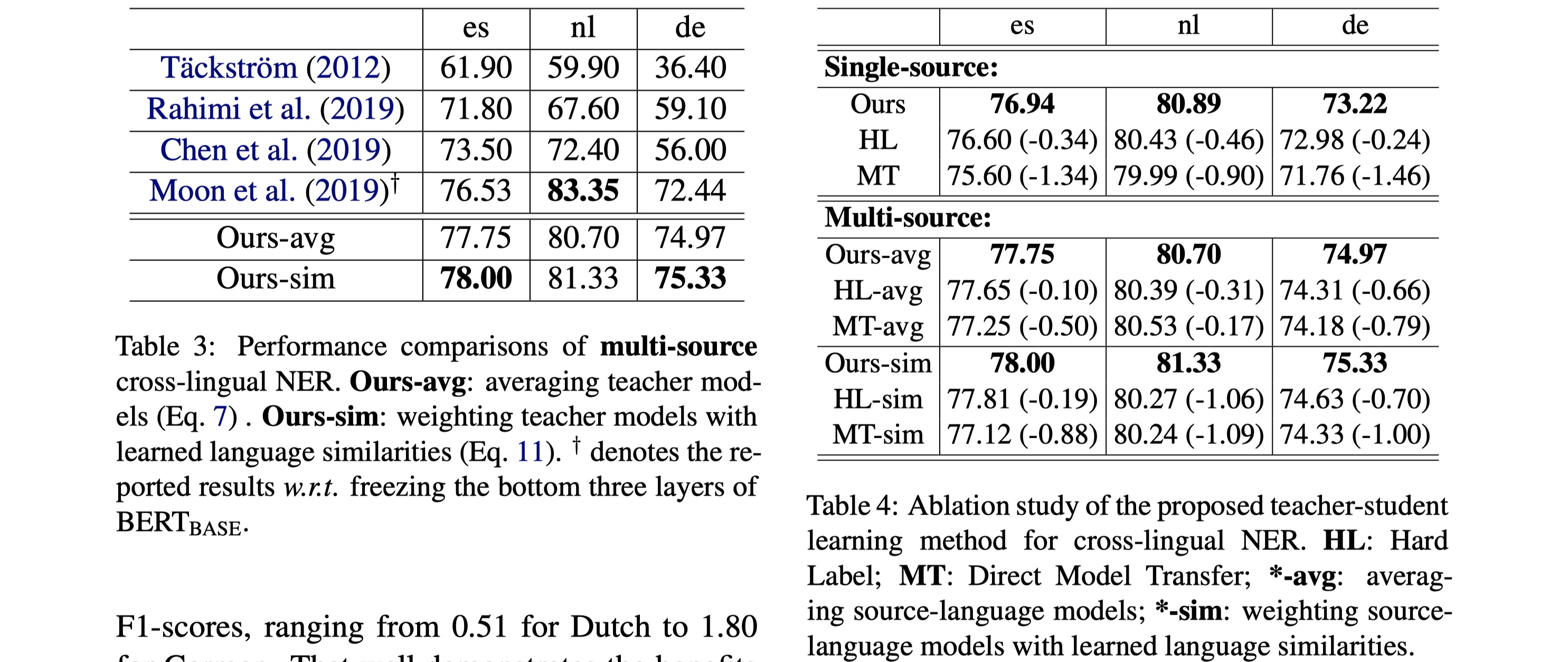
从结果来看,效果是惊人的,在single source cross-lingual NER中,仅仅使用unlabeled target language data,就超越了meta learning那篇的结果;对于multi-source cross-lingual NER中,效果更是大幅提高,说明teacher-student learning这种方法有着很大的潜力。之后可以再在这上面做一些探索。
UniTrans : Unifying Model Transfer and Data Transfer for Cross-Lingual Named Entity Recognition with Unlabeled Data(IJCAI2020)
background
这篇同样也是研究zero-resource cross-lingual NER。目前在cross-lingual NER常用的两种方法的优缺点在上面应提到过了,这里不再赘述。这篇paper希望能够对两种方法进行结合,从而充分利用两者的优点,同时避免其缺点。所以就提出了unitrans模型。额外说一句,这篇paper应该是zero-resource cross-lingual NER的SOTA,结果大幅超越之前所讲解的两篇paper,非常优秀的论文,值得一读。
model
先放图~
![]()
unitrans整体的架构是:1.我们首先确定一个base model,然后使用source language training data $D_{src}$来训练base model得到新的参数为$\theta_{src}$ 的 model;对source language data通过word-to-word translation来得到翻译后的target language data $D_{trans}$,基于$\theta_{src}$,使用翻译后的$D_{trans}$来对参数为$\theta_{src}$的NER model进行fine-tune,并将fine-tuning后的NER model作为teacher model(参数:$\theta_{teach}$);除此之外,我们使用$D_{trans}$来训练base model,得到参数为$\theta_{trans}$的模型(不基于$\theta_{src}$);2.我们得到三个模型($\theta_{src}、\theta_{teach}、\theta_{trans}$)之后,通过设计一种voting机制,去得到unlabeled target language data的pseudo label,然后使用pseudo label来训练student model。下面依次讲解其中重要的compoment。
base model:在这篇paper中,就是一个mBERT+softmax,loss就是entity-level的ce loss。
word-to-word translation:这一部分借鉴的是《Word translation without parallel data》paper中的做法。具体做法是:假设我们已经得到source language与target language的word embedding:$S,T\in R^{d\times D}$,并且得到了D对word的词典,我们希望能够找到一个变化,使得两个语言的word可以相互转换。公式是:
得到$P$之后,对于任何一个source language word,我们可以通过最近邻的方法来找到对应的翻译。但是关键是怎么找到最近邻呢?方法是定义CSLS方法来衡量不同语言的word之间的相似度。具体可以参看link。
knowleage distillation:得到三个模型($\theta_{src}、\theta_{teach}、\theta_{trans}$)之后,我们需要将这些模型的知识蒸馏给student。具体做法是如下:
- 首先,我们将unlabeled target language data输入到$\theta_{teach}$与$\theta_{stu}$中,来让$\theta_{stu}$模型去拟合$\theta_{teach}$的输出的分布,loss使用MSE;这样做,不仅可以将$\theta_{teach}$的知识蒸馏给$\theta_{stu}$,同时还能让$\theta_{stu}$学习到unlabeled language data中的信息;
- 我们希望进一步提升student model的效果,采用的方式是:我们希望能够得到unlabel target language data的pseudo label,然后使用pseudo label来训练student model。具体怎么得到pesudo label呢?我们设计了一种voting 机制,我们将unlabel target langugae输入到三个模型当中,只有当三个模型的输出的结果完全相等时,我们才给其标上label,然后使用这些数据来训练sutdent model。
- 综合第一步与第二步,knowledge distillation的总的loss,表示如下:
其中,${\cal L}_{hard}^{\tilde x}$是第二步的loss,${\cal L}_{soft}^{\tilde x}$是第一步的loss,$\eta=1$。
inference:我们只使用student model,另外注意,解码使用CRF。
experiment
数据集:CoNLL-2002、CoNLL-2003、NoDaLiDa-2019
结果

从结果中我们可以看到,效果提升非常大,这个还可以通过teacher ensembling进一步提升效果。作者也做了一些消融实验,如下:

这篇论文结果真的太强了,甚至给我感觉使用teacher-student learning这种方式来做cross-lingual NER,这篇paper到顶了。
GRN model(not for cross-lingual NER)
background
GRN模型是2019年MSRA发表在AAAI上的《GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition》。在NER任务中,由于其对word的位置信息极其敏感,所以常用的编码器常常使用RNN,但是RNN系列的编码器最大的缺点就在于并行效率太低,而CNN相比RNN来说,最大的优势在于:并行效率高,但是其缺点在于CNN只能对word周边的信息进行建模,捕捉局部context information,但是CNN对global context information的捕捉能力太弱,基于CNN的NER模型(IDCNN)在NER任务上的结果都弱于RNN系列的NER模型,所以,是否能够设计某种机制,让CNN能够捕捉到global context information呢?在GRN里,通过使用gating机制对sentence中的任意两个word之间的relation进行建模,从而让CNN捕捉global context information的能力大大提高,这就是GRN提出的背景。
吐槽一下,这篇说实话很一般,idea真的一般,2019年,BERT都出来了,在GRN的实验里,都没有使用BERT来进行对比,结果也没啥说服力。
GRN model
整个GRN模型分为四层:representation layer、context layer、relation layer、CRF layer。
representation layer:假设输入的sentence表示为:$s=\{s_1,s_2,…,s_T\}$,每一个token对应的标签表示为:$y=\{y_1,y_2,..,y_T\}$。整个layer的输出有两部分:由GloVe初始化的word embedding(update in training stage)+char embedding通过kernel=3的CNN+max-over-time pooling,从而得到char feature。第一部分表示为:$w_i=E(s_i)$;第二部分:$c_i$,输出是两者concat的结果:$z_i=[c_i,w_i]$。
context layer:这一层主要是捕捉word的局部信息。具体做法是:使用多个不同kernel size的CNN(等长卷积,kernel size=1,3,5)来得到encoding的输出,卷积的激活函数使用$tanh$,然后对使用激活函数之后的结果进行concat,再使用max pooling(不是global max pooling,所以维度数目不变)。
relation layer:这一层的目的主要是用来对sentence中的任意两个word之间的关系进行modeling,并利用gating机制来获取全局内容信息,具体公式如下(其实还是attention,没啥创新,不过这个layer的实现code还是可以去看看的):
其中,$r_i$就是word $x_i$的全局fusion feature,当然了,为了增加非线性,对$r_i$使用tanh进行变换,得到$p_i$,这就是最终输入到CRF的输入。
CRF layer:就是标准的CRF layer。
experiment
- 数据集:CoNLL-2003 English NER、OntoNotes 5.0
- hypoparameters的设置请参考原始论文,具体结果就不放了,反正就在当时达到了SOTA,anyway。
references
《Enhanced Meta-Learning for Cross-lingual Named Entity Recognition with Minimal Resources》
code:https://github.com/microsoft/vert-papers/tree/master/papers/Meta-Cross
《Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language》、
code:https://github.com/microsoft/vert-papers/tree/master/papers/SingleMulti-TS
《UniTrans : Unifying Model Transfer and Data Transfer for Cross-Lingual Named Entity Recognition with Unlabeled Data》
code: https://github.com/microsoft/vert-papers/tree/master/papers/UniTrans
《GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition》。

