近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要讲解一下《FLAT: Chinese NER Using Flat-Lattice Transformer》论文,即:FLAT模型,这是今年ACL2020上NER任务的SOTA,个人觉得模型设计上非常优雅,非常值得一读,预测以后会成为比赛的标配🧐。
FLAT模型提出的背景
对于中文NER任务,词汇增强是有效提升效果的方法之一。LatticeLSTM是词汇增强的典型模型。但是这种Lattice结构,其模型结构比较复杂,并且由于lexicon word插入位置的动态性,导致LatticeLSTM模型无法并行,所以LatticeLSTM无法很好的利用GPU加速,其training以及inference的速度非常慢。所以怎么既能够很好的融入lexicon信息,同时又能够在不降低效果甚至提升效果的同时,大幅提升training以及inference的速度,这就是FLAT模型提出的背景。目前在NER中,处理lattice结构的方式有两大类:1. 设计一个框架,能够兼容词汇信息的输入,典型的模型有:LatticeLSTM、LRCNN,这种模型的缺点是无法对长期依赖进行建模;2.将lattice结构转换为graph结构,典型的模型有:LGN、CGN,这种模型的缺点是:1.序列结构和graph结构还是有一定的差别;2.通常需要使用RNN来捕获顺序信息。而FLAT基于transformer,能够很好的解决上述的问题,但是vanilla transformer对于位置信息的捕捉其实是很弱的,很多实验表明transformer对于NER这种对于位置信息要求很高的任务,并不是很适合,所以怎么解决这个问题,具体的将在下面几节介绍。
FLAT模型介绍
先放模型图~
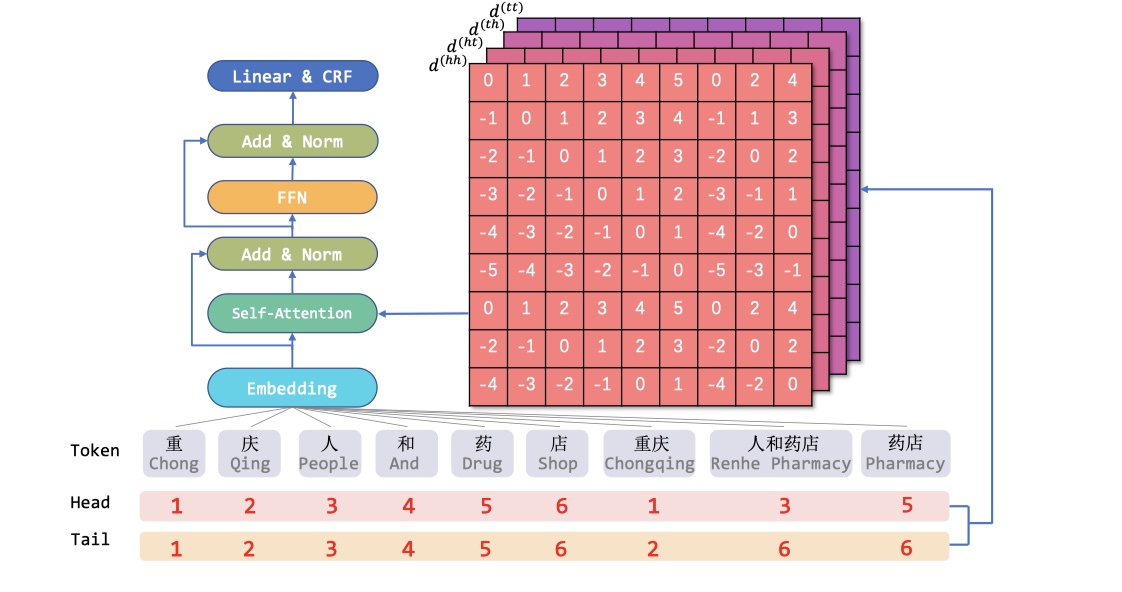
上图是FLAT模型的整体结构。整体结构就是transformer的encoder部分+CRF。主要的改进就是在position encoding部分,因为transformer使用的是self-attnetion,这种点积的方式,破坏了transformer的距离感知和方向感知性。具体怎么改呢?下面具体介绍。
在FLAT中,将lattice结构转换为flat 结构。怎么做呢?每一个character以及mathced lexicon word都有head index与tail index。这样的话,我们就将lattice转换为flat结构,而且由于有了head index与tail index,所以转换是可以逆转的。
在FLAT中,定义了新的相对位置编码。对于span $x_i$与$x_j$,它的head与tail分别表示为:$head[i],tail[i]$与$head[j],tail[j]$。$x_i$与$x_j$的关系可以用以下四个相对距离来表示:
最终,相对位置编码计算如下:
融合后的$R$的维度是:$[batch_size,hidden_size,seq_len,seq_len]$。当然了,既然使用了相对位置编码,那么vanilla transformer中的self attention的方式就不能用了(适用于绝对位置编码),所以在FLAT中,采用的是transformer-xl中的variant self attention,公式如下:
关于这个是怎么来的,可以参考transformer-xl原始论文或者link。
实验结果
数据集:OntoNotes、MSRA、Weibo、Resume
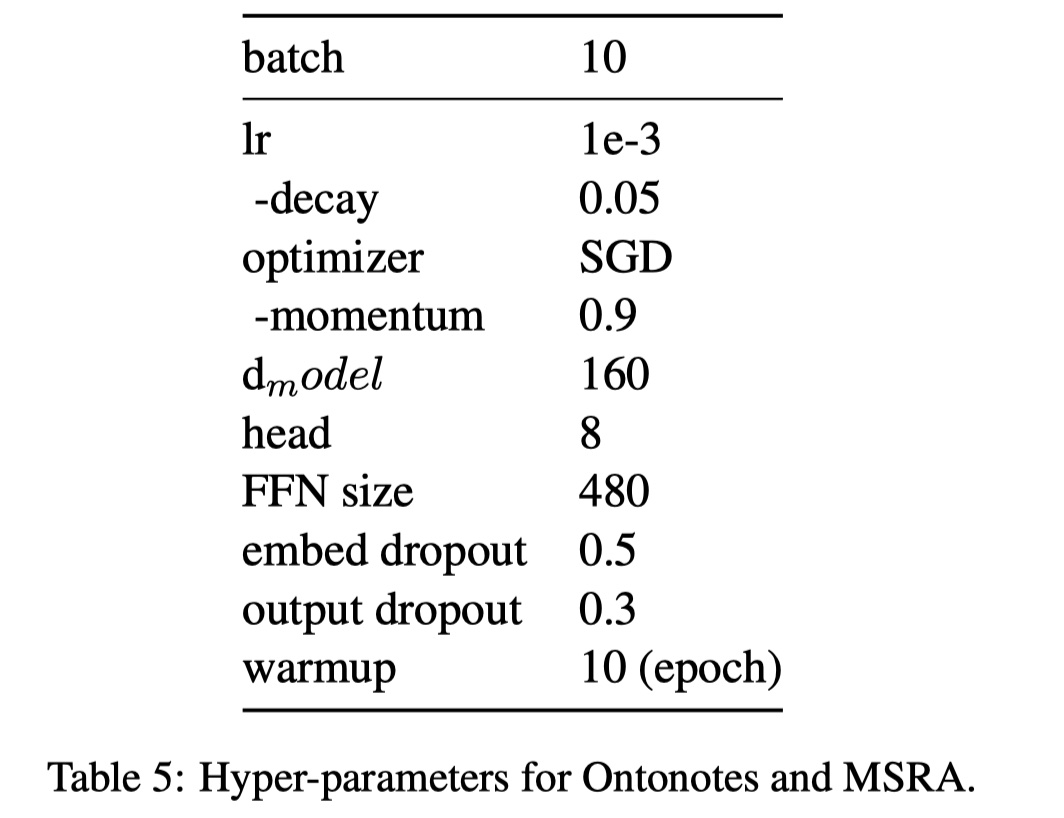
参数设置:

实验结果
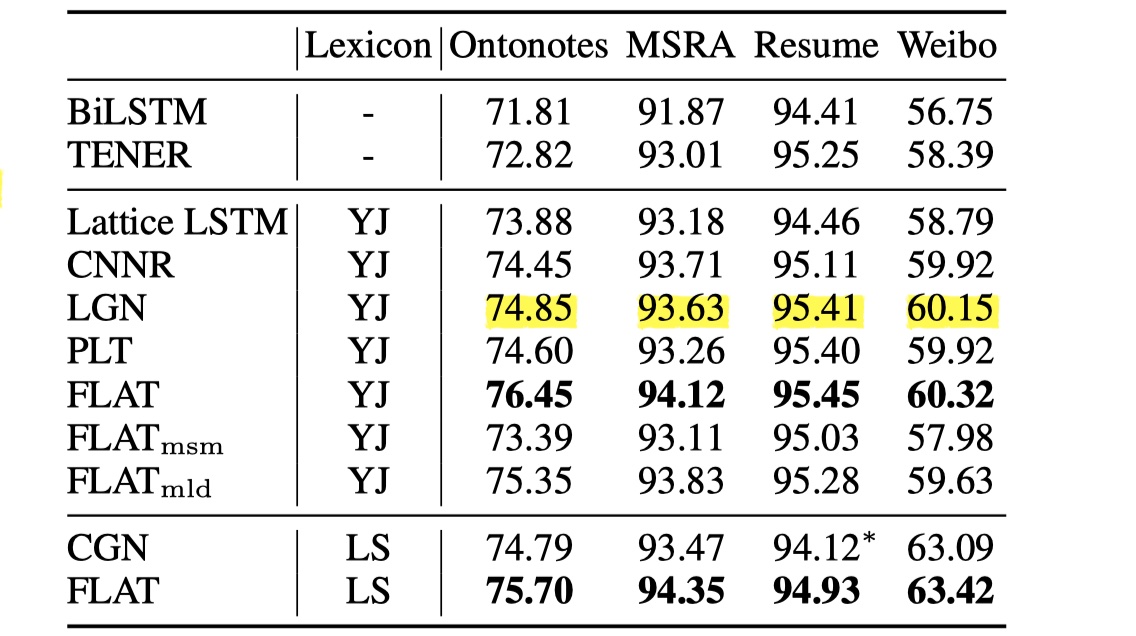
我们首先来看一下FLAT以及其他的模型在四个数据集上的表现,如下图所示。从结果可以看到,FLAT的结果都超过了之前提出的模型。
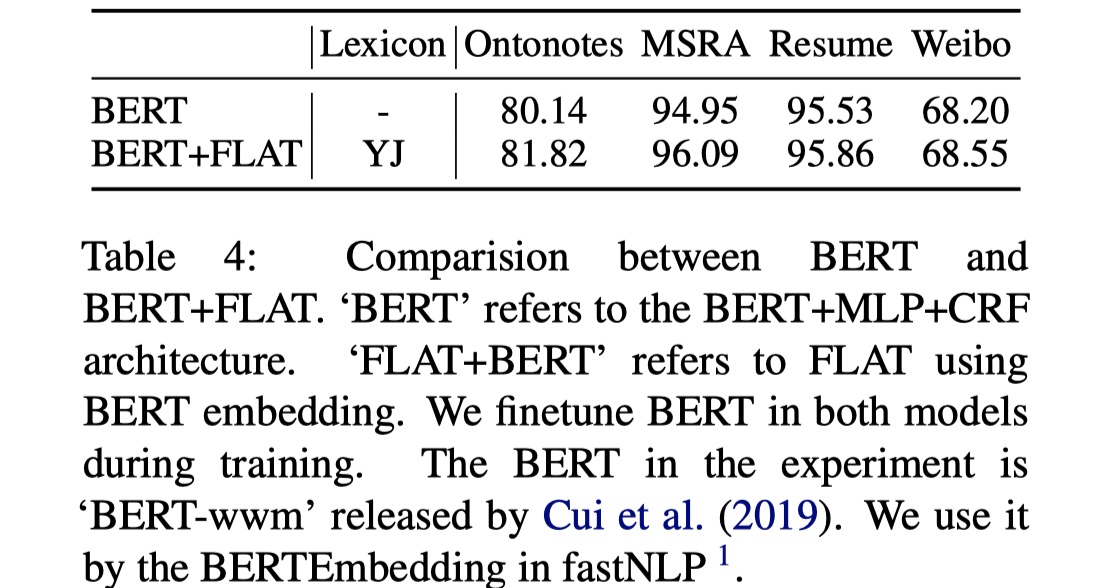
我们看一下加上了BERT之后的结果,如下图所示。NB!以后比赛可以搞起来了就不一定是BERT+BILSTM+CRF了,也可以是是BERT+FLAT+CRF,不过词汇表在其中还是占了大部分作用,以后要用的好的话,就得制作词汇表了。🧐
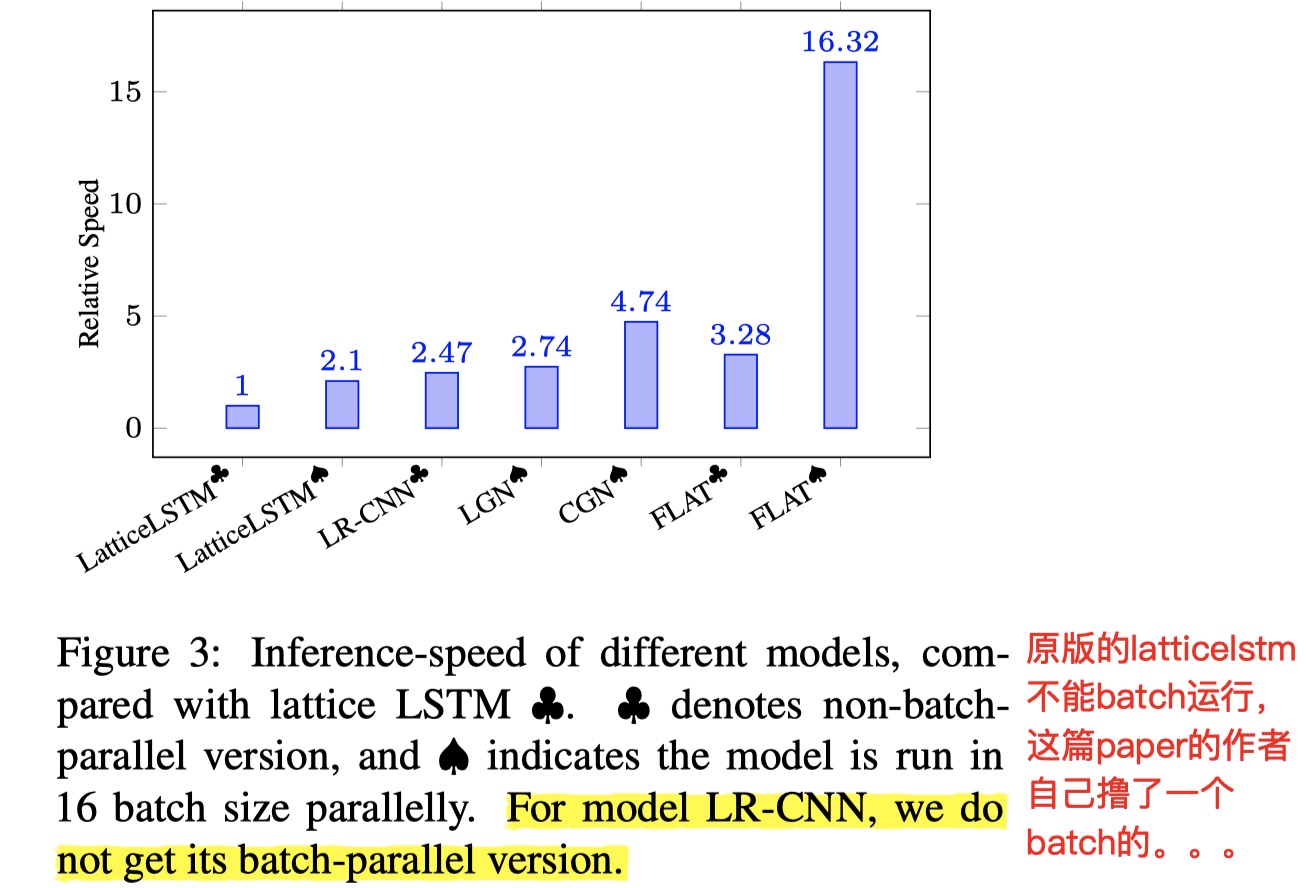
我们再来看一下推理速度,如下图所示。在batch的情况下,inferance的速度比其他模型快上好几倍,FLAT nb!这个实验另外让我非常惊奇的是,原始的LatticeLSTM的code是不能batch训练的,但是这篇paper的作者自己手撸了一个batch的LatticeLSTM,向大佬低头,有空去看看具体是怎么做到的。code
参考文献
《FLAT: Chinese NER Using Flat-Lattice Transformer》
《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》

