近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要讲解一下《Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network》论文,即:CGN模型,个人认为这篇文章将GNN应用到NER任务中的方式非常的优雅,值得一读。
CGN模型提出的背景
词汇增强是目前NER中提升模型效果最有效的方法之一。LatticeLSTM是词汇增强的开山之作。但是LatticeLSTM中,仍然有三个问题没有解决:无法并行化、没有集成self-matched lexicon words到character中、没有直接集成与当前character最接近的lexicon words的信息(会导致word conflicts问题)。CGN模型正是为了解决这些问题而被提出来的。
ps:latticeLSTM模型一定要好好研读一下,对于词汇增强类NER模型,基本上都是基于latticeLSTM模型的缺陷改进而来。
CGN模型介绍
还是先放模型图,再逐步介绍~
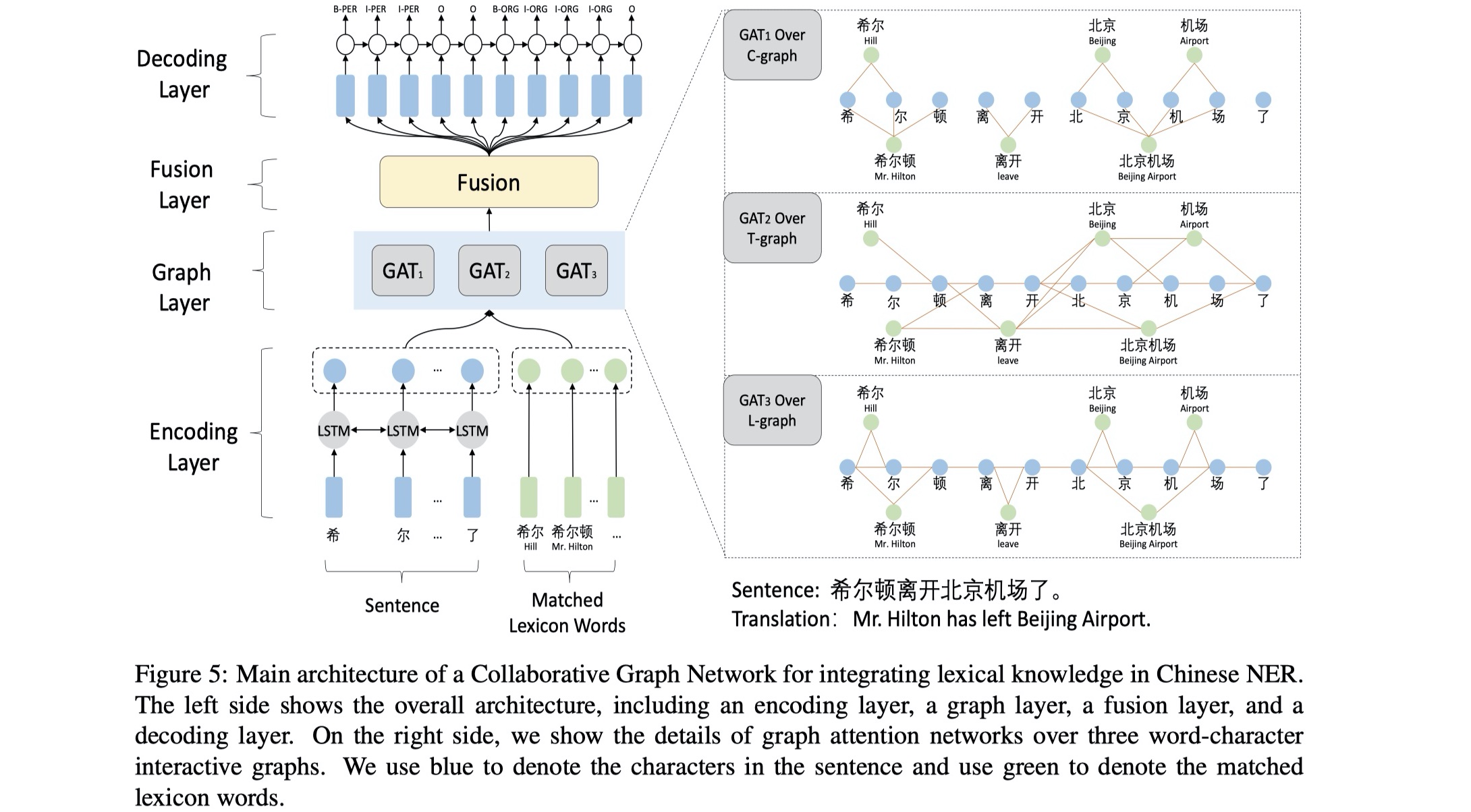
整个模型分为四层:encoding layer、graph layer、fusion layer、decoding layer,下面详细介绍~
encoding layer:模型的输入分为两部分:sentence以及与sentence相匹配的lexicon words,分别表示为:$s=\{c_1,c_2,…,c_n\},l=\{l_1,l_2,…,l_m\}$,其中$c_i$表示sentence的第i个character,$l_i$表示与sentence相匹配的第i个lexicon word。通过使用pretrained char embedding table,我们可以得到每一个character的char embedding:$x_i=e^c(c_i)$;得到char embeding,我们需要将输入到BILSTM进行编码,这一步主要是为了捕获句子的顺序关系,得到contextual representation;对于matched lexicon words,我们也是通过使用pretrained word embedding table,得到每一个word的embedding:$wv_i=e^w(l_i)$。最终encoding layer的输出是对这两者进行concat的结果,表示为:$Node_f=[h_1,h_2,…,h_n,wv_1,wv_2,…,wv_m]$,其维度是:$[batch_size,n+m,hidden_size]$,我认为这样融合lexicon word的方式是更加优雅的,因为这样不仅可以融合lexicon word information,同时还解决了latticeLSTM模型无法并行的问题。
graph layer:这一层就是使用GNN来解决后面的两个问题的。总共分为三个graph层:Containing graph、Transition graph、Lattice graph。下面依次介绍:图的构建以及aggregate。
图的构建
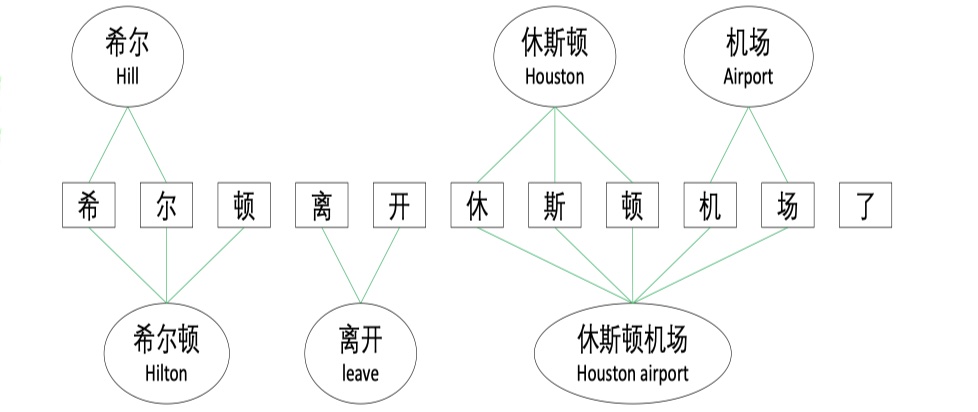
Containing graph(C-graph):这一层是为了集成self-matched words到character中而设计的,主要就是建模character与self-matched words的关系。那么怎么构建呢?既然是graph,就要首先确定node set与edge set,C-graph中的node就是所有的character与matched lexicon words;C-graph中的edge是:我们首先根据所有的character与matched lexicon words来构造邻接矩阵(行代表word,列代表character),如果word $i$包含character $j$的话,那么邻接矩阵中的$(i,j)$的值为1,否则为0,对应于C-graph的话,就是word与character有连接,如下图所示:
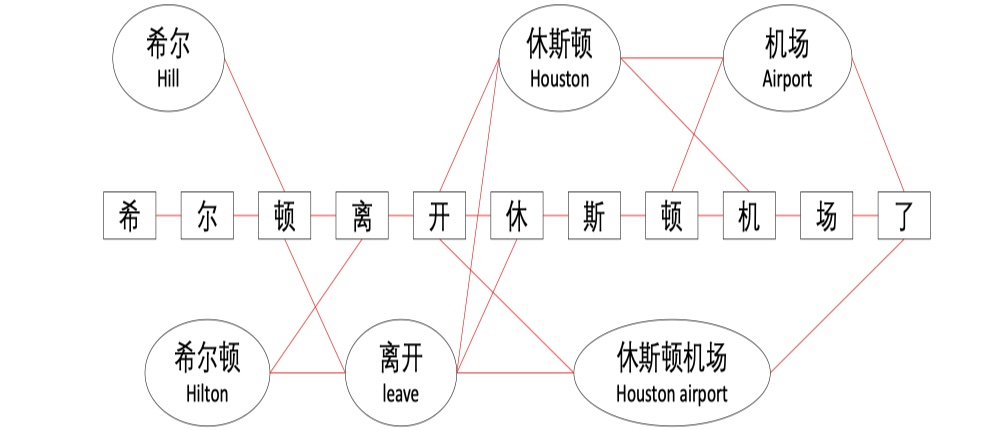
Transition graph(T-graph):这一层是为了直接集成与当前character最接近的lexicon word信息(preceding or following)。怎么构建图呢?node set还是有C-graph一样,但是edge set不一样,edge是:我们仍然是更加node set来构建邻接矩阵(行:words+character,列:word+character),如果word $i$或者character $m$是 character $j$的最接近的信息,那么邻接矩阵中的$(i,j) or (m,j)$的值为1,同时为了捕获word与word之间的关系,如果word $i$是word $k$ 的preceding或者following的信息,那么$(i,k)$的值为1。对应于T-graph的话,如下图所示:
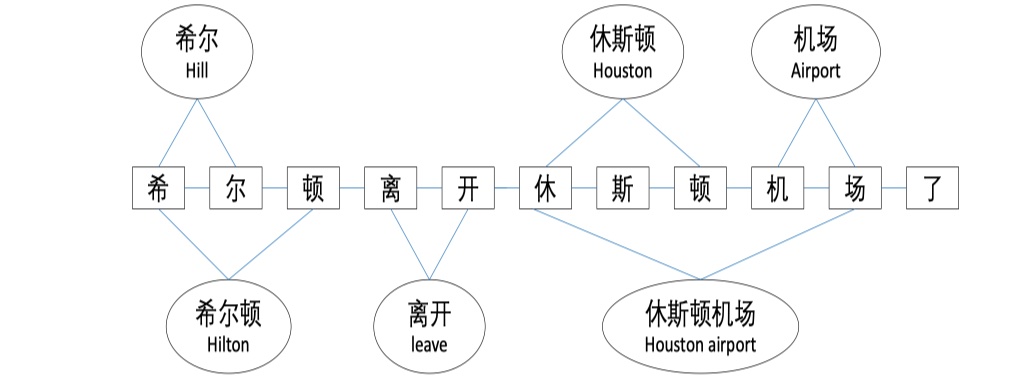
Lattice-graph(L-graph):对应于LatticeLSTM中的Lattice结构,主要是能够捕获到self-matched word的局部信息以及隐式的的集成最接近的lexicon word(个人认为加这个其实就是为了融合更多信息,也没有什么特别的作用,就算不加也是OK的,逻辑上没有什么错误或者不通,但是效果可能就不会这么好了)。怎么构建图呢?node set与前面的一样,edge set1不一样,edge是:我们根据node set来构建邻接矩阵(行:word+character,列:word+character),如果character $m$是character $j$最接近的character,那么$(m,j)$的值为,那其实相对的,$(j,m)$的值也为1,另外,如果character $j$是word $i$的首位或者尾位,那么$(i,j)$的值为1。对应到L-graph上的话,如下图所示:
aggeragte
构建完图之后,我们对每一个graph,都使用GAT模型来进行encoding(不知道可不可以这么说,我理解的aggregate就是encoding🧐)。假设有对于一个graph,有M层。第$j$层的输入是node feature:$NF^{j-1}=\{f_1,f_2,..,f_N\}$以及邻接矩阵$A$,其中$f_i\in R^F,A\in R^{N\times N}$,第$j$层的输出是新的node feature:$NF^{j+1}=\{f_1^{‘},f_2^{‘},…,f_N^{‘}\}$。具体怎么计算呢,其实也比较简单,如下:
其中,$K$表示的是有$K$个head,在GAT中,使用了multihead attention(但不是self-attention),$||$表示concat,$\alpha_{ij}^k$表示的是第k个head中,邻域内第$j$个node对$i$ node的重要性程度,$\sigma$是激活函数,不是sigmoid函数,$a^T$表示的是单层的FFN,激活函数选择leakyrelu。对于GAT的最后一层,则是先avg,然后在使用激活函数来激活,具体如下:
当然了,这是对于一个graph,我们构建了三个graph,所以三个graph的输出的node feature如下:
其中,$G_k\in R^{F^{‘} \times (n+m)},k=\{1,2,3\}$。在得到最终的输出的node feature之后,我们只取前$n$列,后面的$m$列不要,因为我们要得到的是character的representation,然后输送到CRF。如下:
Fusion layer:这一层就是对上一层得到的各种node feature进行fusion。这里就是简单的使用了相加。如下:
$H$是最初的char embedding送入BILSTM之后,得出的contextual representation。
Decoding layer:这一层就是使用标准的CRF来解码,加入了L2正则。
实验结果
数据集:OntoNotes、MSRA、Weibo
参数设置:batch size:64(MSRA),20(OntoNotes),10(Weibo);optimizer:Adam(MSRA)、GD(OntoNotes and Weibo)
实验结果:
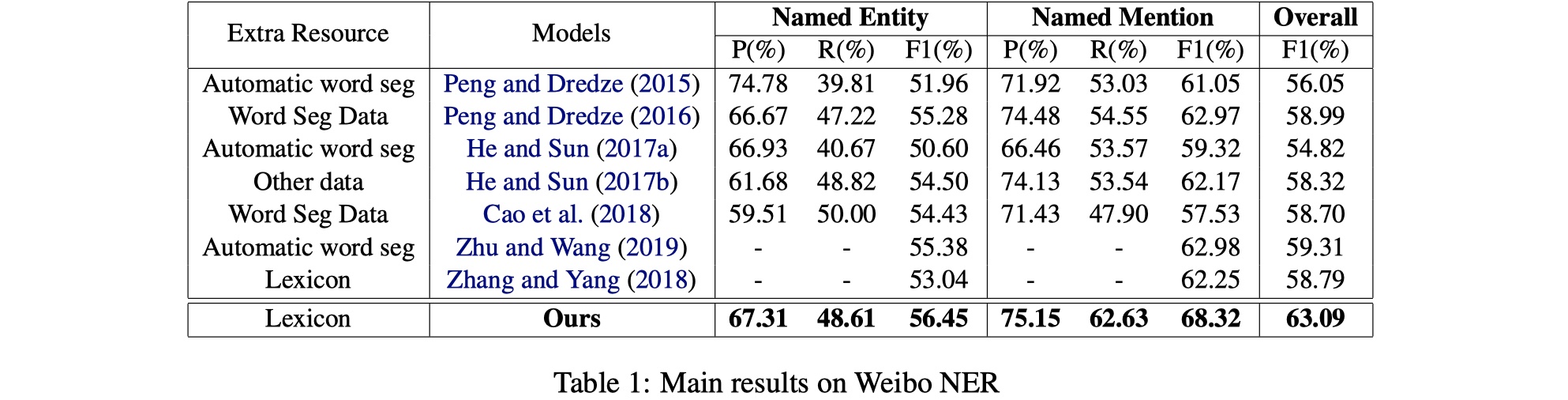
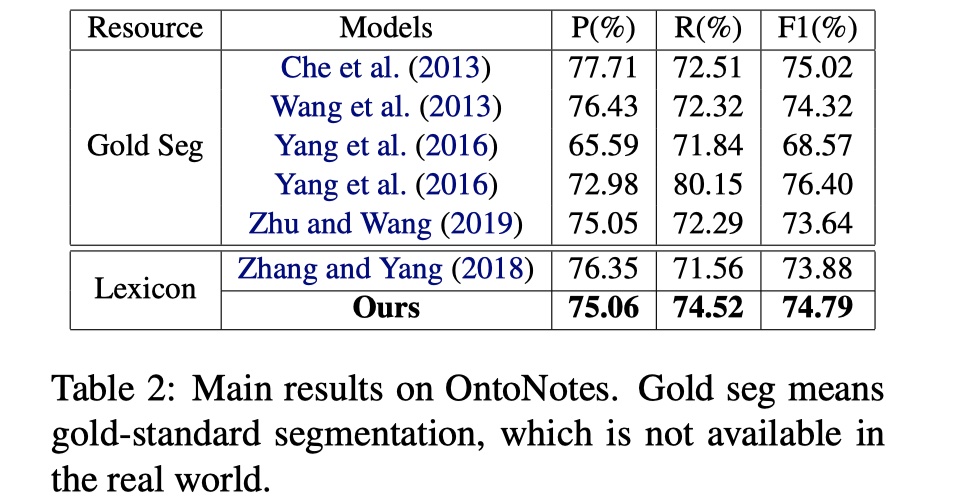
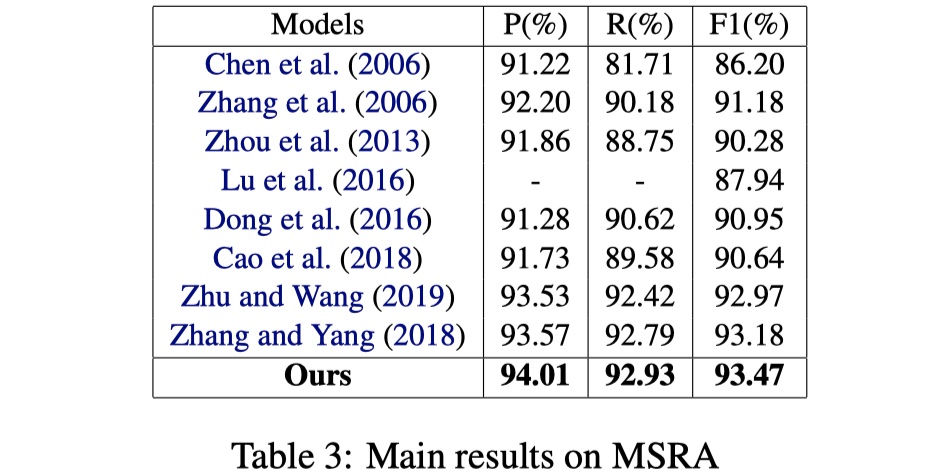
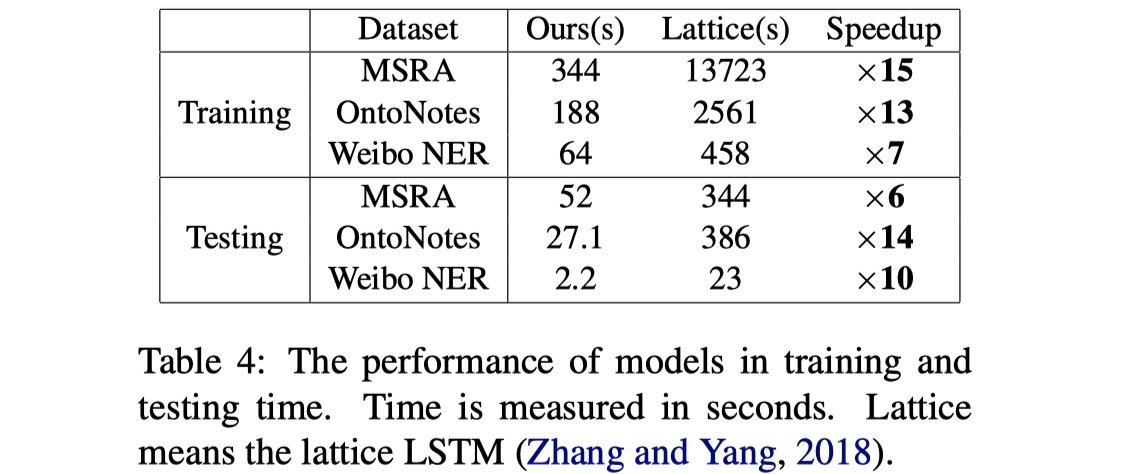
从结果来看,CGN还是不错的,尤其是在Weibo数据集上,提升非常大。另外一篇使用GNN来做的LGN模型,从paper中发布的结果来看,ontonotes以及msra的结果要比CGN好上一点点,但是我个人认为CGN融合lexicon的方式要更加优雅一些,而且扩展性比较强。当然了,FLAT出来之后,几乎秒杀CGN和LGN,不过要是还是想用GNN来做NER的话,CGN是一个可以follow的工作,个人想法🧐。
参考文献
《A Lexicon-Based Graph Neural Network for Chinese NER》
code:https://github.com/DianboWork/Graph4CNER
GAT讲解:https://zhuanlan.zhihu.com/p/81350196?utm_source=wechat_session

