近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要讲解一下《A Lexicon-Based Graph Neural Network for Chinese NER》论文,即:LGN模型,有意思的是,这篇论文与LRCNN是同一个作者。
LGN模型提出的背景
LGN着眼解决的问题与LRCNN模型是一样的(两个模型来自于同一作者),就是LatticeLSTM中存在着一个问题:lexicon conflicts。在LRCNN模型中,是通过rethinking mechanism来解决,而在LGN模型中,则是通过GNN来进行解决这个问题,那么为什么可以用GNN来解决呢?因为对于word conflicts问题,很重要的就是要利用句子的全局信息和高层特征来进行解决,而GNN对于全局信息的建模和聚合有着非常强大的能力。具体是怎么解决的将在下面几小节具体说明。
LGN模型介绍
先放图~
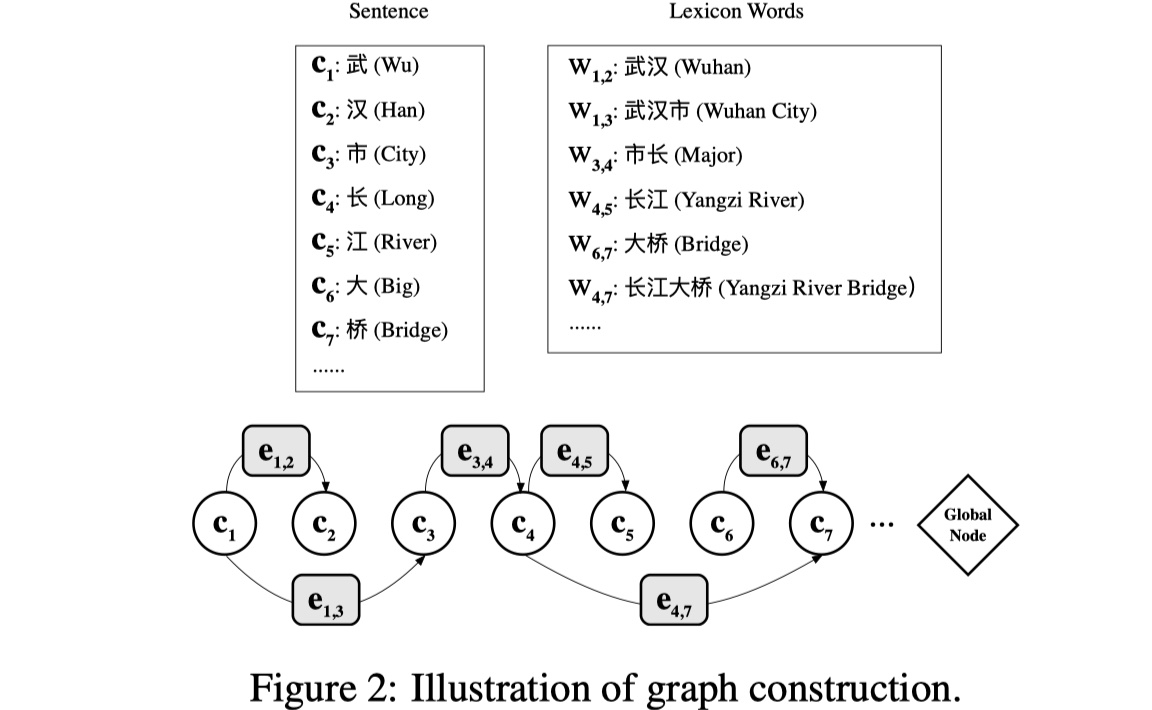
图的构建及node与edge的初始化。既然使用了GNN来解决,那么首先需要解决的问题就是:如何构建图?
- node:在LGN模型中,sentence中的char当作node,node的初始化并不是直接使用char embedding,而是将其输入到LSTM当中,输出的结果当作node的初始化;
- edge:lexicon中的word被当作edge,(edge的初始化直接使用word embedding即可),edge的指向是从首个字指向尾个字,以此来构建一个有向图。
- global relay node:此外,在LGN中,还设置了全局中继节点来获取全局信息来用以解决word conflicts问题。
- 使用公式来表示:假设句子表示为:$s=\{c_1,c_2,…,c_n\}$,$c_i$表示第$i$个字,lexicon中的word表示为:$w_{b,e}=\{c_b,c_{b+1},…,c_{e-1},c_e\}$,$b,e$分别表示该词的首部与尾部的index,整个图表示为:$\cal G=(V,E)$,$c_i\in \cal V$,$e_{b,e}\in \cal E$。除此之外,原图转置后的反向图表示为:$\cal G^T$。我们最终的是
图的Local Aggregation。local aggregation分为两大部分:node aggregation和edge aggregation。下面依次介绍。
- node aggregation其实和普通的GNN一样,就是聚合其邻域特征,在这里,使用transformer中的multihead attention来进行聚合,具体公式如下:
其中,$\tilde c^t_i$表示第i个char的第t次step aggregate之后的结果(个人理解是为计算$c^{t+1}_i$做准备),$c^t_i$表示第i个char的第t次step的结果,$e^{t}_{k,i}$表示第t次step的index从k到i的edge的state。
- edge aggregation也是一样,聚合其邻域特征。对于$e^t_{b,e}$,它的邻域特征有index从b到e的所有char的信息。所以同样通过multihead attention来进行聚合,具体公式如下:其中$C^t_{b,e}$表示index从b到e的char sequence embedding。
Global aggregation。由于句子并不是完全的sequential的,所以为了捕获长期依赖和高层特征,在LGN当中设置了global relay node来aggregate node和edge。具体公式如下:
其中,$C^t_{1,n}$表示第t个step的整个句子的hidden state,$g^t$表示的是第t个step整个图的全局信息。
Node update。在进行聚合之后,就要开始对node进行更新。具体公司如下:
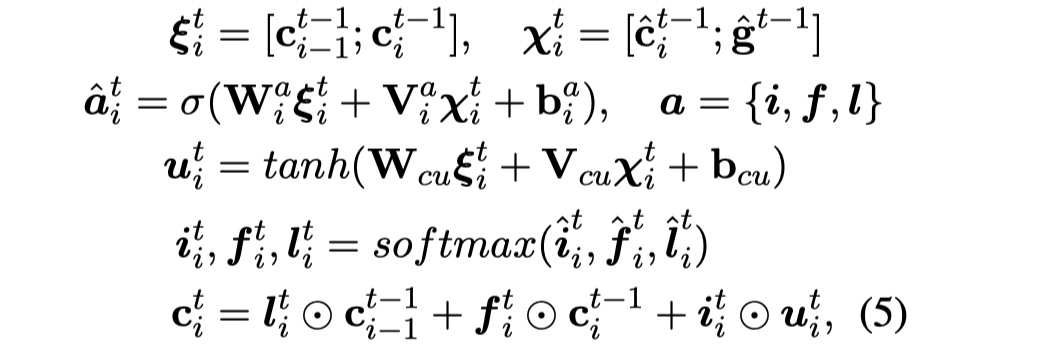
其中,$\cal X^t_i$表示的是node i与全局中继节点$\tilde g^{t-1}$的concat,$\xi ^t_i$表示的是bigram的concat,这个实际上和LSTM有点像。
Edge update。这个与node update是一样的。具体公式如下:
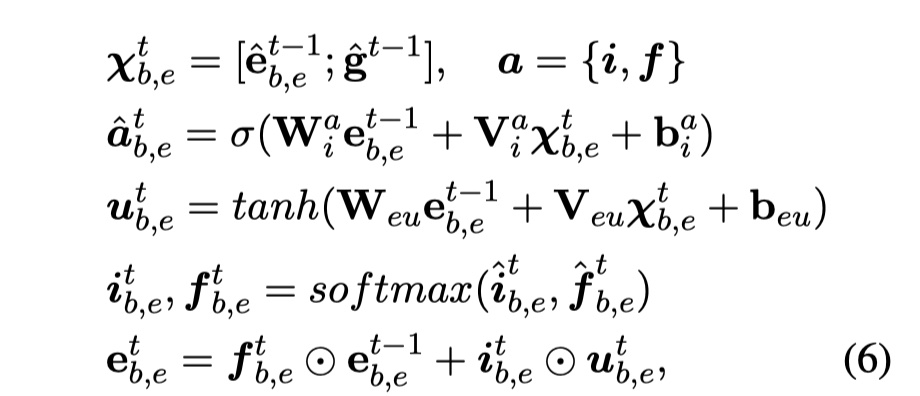
其中,$\cal X^t_{b,e}$表示的是aggregation edge $\tilde e^{t-1}_{b,e}$与全局中继节点$\tilde g^{t-1}$的concat。
Global relay node update。与上述一样,不再赘述,具体公式如下:
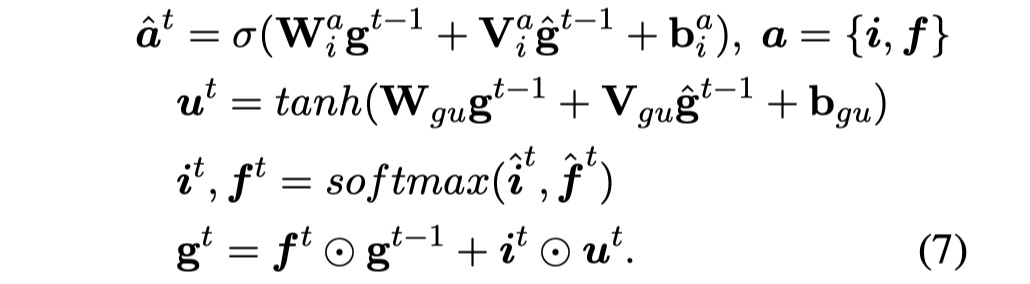
重复2-6步骤若干次,之后接入CRF,这没什么可以说的。
实验结果
数据集:OntoNotes、MSRA、Weibo、Resume
参数设置:Adam optimizer(learning rate=2e-5 on MSRA and OntoNotes, 2e-4 on Weibo and resume);droput(0.5 on embedding ,0.2 on aggregation module);embedding size and state size is 50;
结果
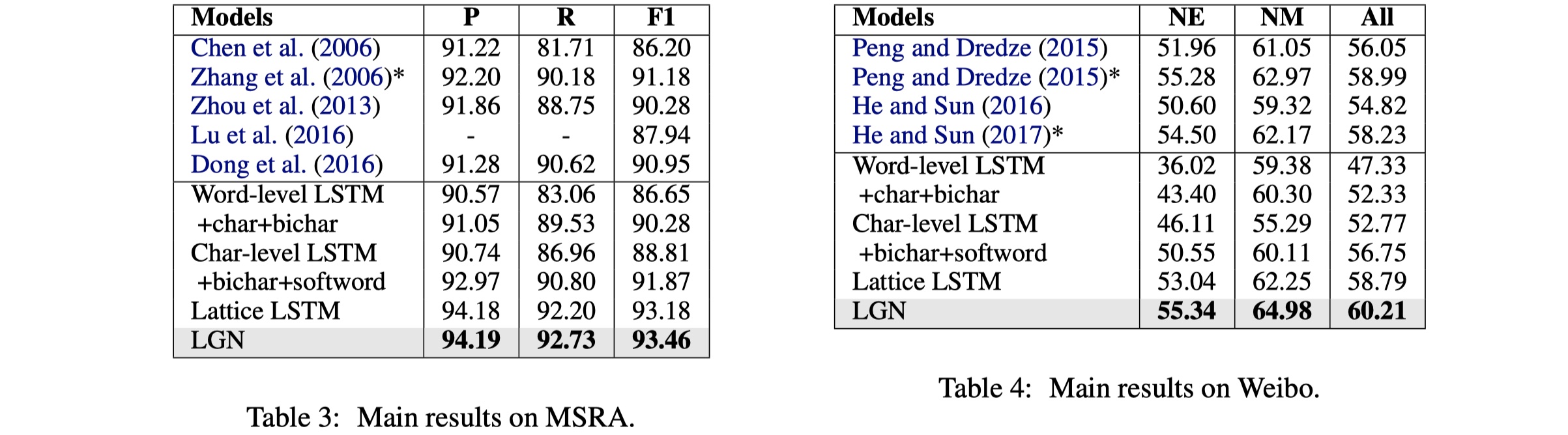
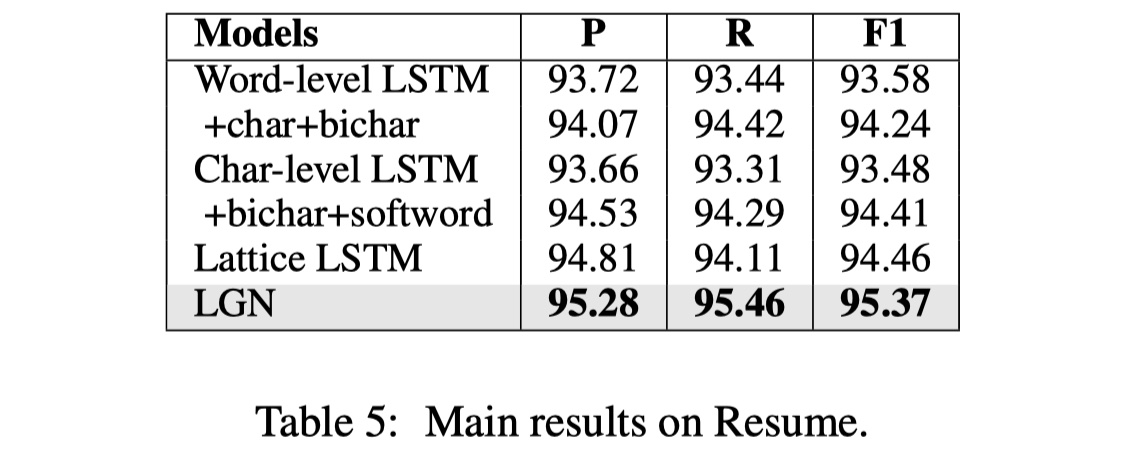
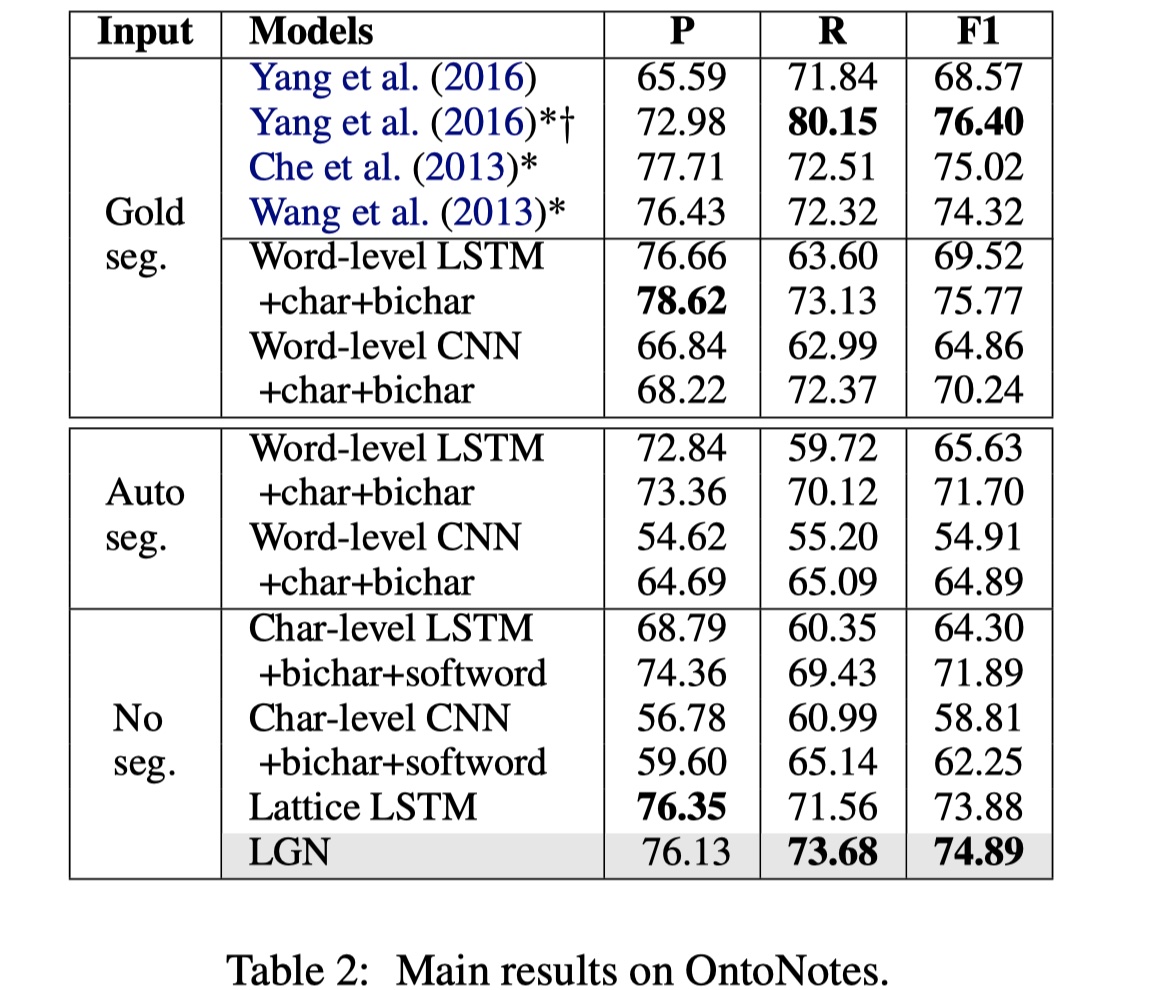
从结果来看,要比LatticeLSTM要好,但是有意思的是,这个结果要比这个作者提出的LRCNN要差一些,我查了一下,都是19年发的,一个在emnlp(this paper),一个在ijcai,anyway,enjoy。
参考文献
《A Lexicon-Based Graph Neural Network for Chinese NER》

