近期会更新一系列NER的paper解读,计划2周时间将NER的重要的论文刷完,有一个想做的事情嘻嘻😁。这篇博客主要讲解一下《CNN-Based Chinese NER with Lexicon Rethinking》论文,即:LRCNN模型。
LRCNN模型提出的背景
词汇增强被证明是有效提升NER性能的方式。其中最具开创性的工作就是LatticeLSTM,通过设计巧妙的gate机制将词汇信息融入到char level model中,大幅提高了效果。但是LatticeLSTM存在着两个非常严重的缺陷:
1. 无法并行化。在LatticeLSTM中,引入的词汇信息的位置与数量是不固定的,所以无法使用batch来加速训练;
2. 无法有效处理词汇信息冲突的问题。譬如:广州市长隆公园,在lexicon中有:广州市,市长,长隆,由于 长 是 市长 与 长隆的组成部分,所以模型对于长这个字的标记就会出现偏差,因为模型不知道要怎么对其进行标记,从而很可能标记出错,换句话说,词汇中的某些词会对模型中的字的标记进行误导。为了解决这两个问题,就有了LRCNN模型。
LRCNN模型介绍
在LRCNN模型中,对于第一个问题:LRCNN采用了CNN而不是RNN来对句子进行编码,这样的话,在不同的cnn layer,不同长度的词汇将被融入模型中;对于第二个问题:LRCNN模型使用了rethinking mechanism。先放图~
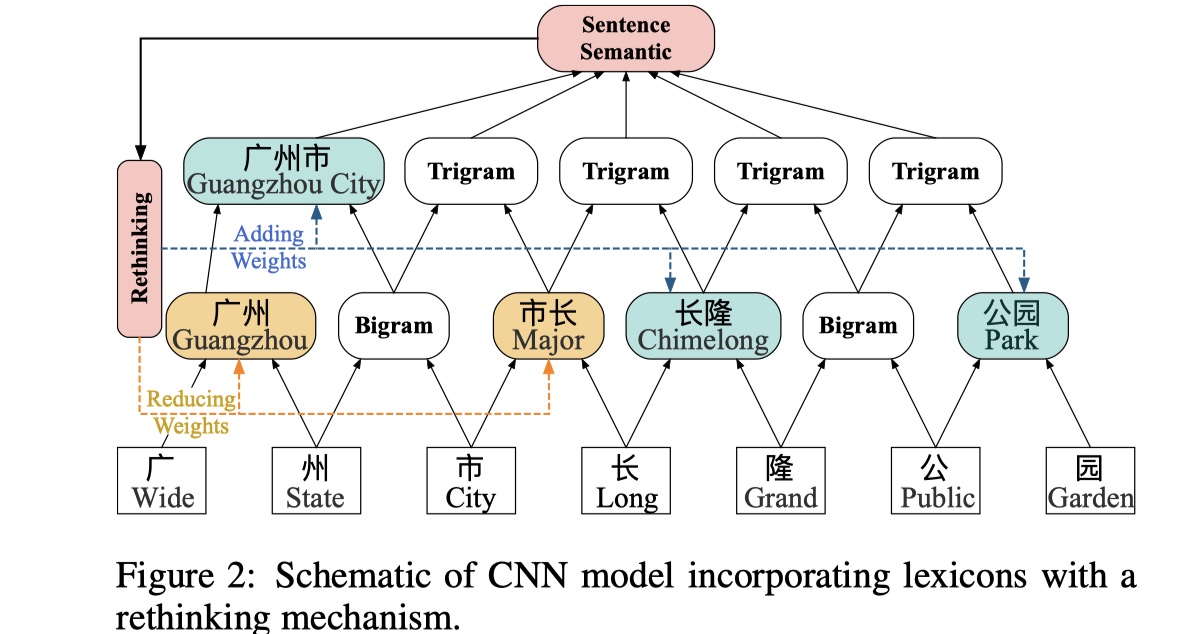
具体的LRCNN模型描述如下:
假设输入的句子表示:$C=\{c_1,c_2,…,c_M\}\in\cal R^{M \times d}$,基于字的词汇表为$\cal V$,其中$c_i$是第$i$个字的char embedding,且$c_i\in \cal R^d$,句子中与lexicon相匹配的每一个词语表示为:$w_m^l=\{c_m,…,c_{m+l-1}\}$,其中$c_m$表示这个词语的首个字,$l$是这个词语的长度。
在句子编码层,LRCNN模型stack多层的cnn layer,主要目的就是:不仅能够很好的融入词汇信息,同时还能够并行化加速训练。具体来说:采用window size为2的一维卷积,以上图为例,我们将char embedding当作第一层,那么使用一次卷积后,可以得到第二层,这一层中每一个token都是一个bigram,如果在此基础上,在使用一次卷积,就可以得到trigram,以此类推,我们就可以不断地扩大感受野。除此之外,我们可以将词汇信息融入其中,具体来说:譬如
广州是lexicon中的词,也是卷积后的bigram,我们可以使用badanan attention,从而将bigram信息与词汇信息进行融合。具体公式如下: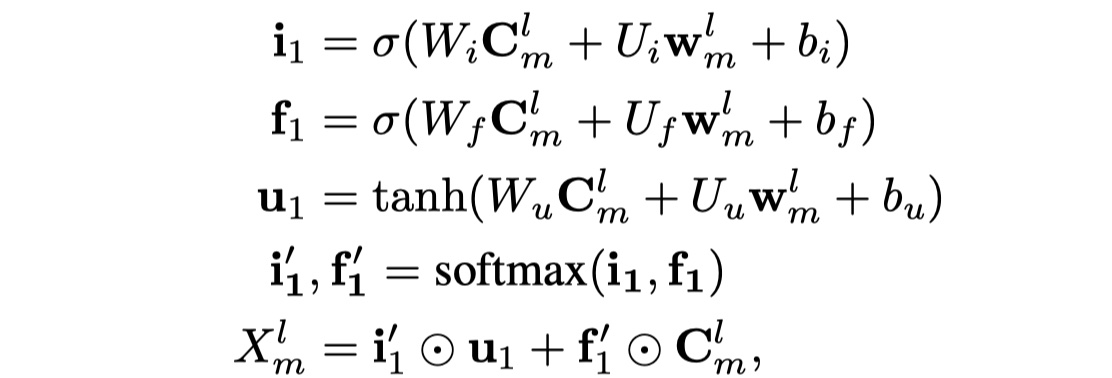
其中$X_m^l$表示的是融合之后的结果。
由于CNN的分层结构,低层的词汇无法影响到高层的词汇,所以为了解决第二个问题,LRCNN模型中应用了rethinking mechanism。所谓地rethinking mechanism指的是:使用最顶层的CNN的feature map来指导低层的lexicon conflicts问题。具体做法是:向每一层CNN添加一个feedback layer来调整lexicon的权重。举个例子,如果高层特征中没有得到
广州市与长隆,那么低层的市长这一词汇将会对最终的标注产生误导,所以需要广州市来降低市长一词在输出特征中的权重。具体公式如下: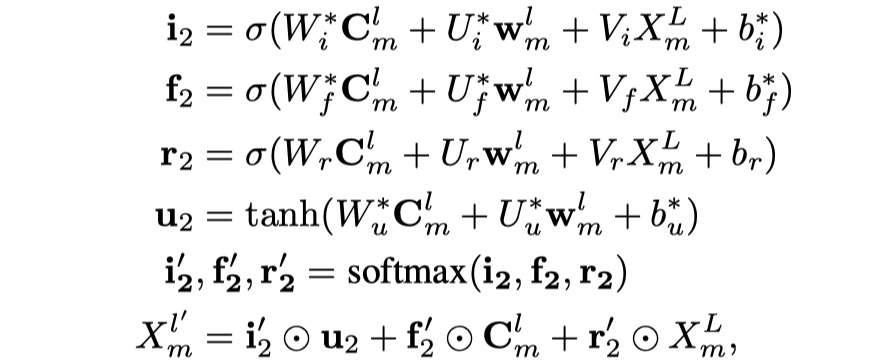
需要注意的是,其中$W,U,b$都是reuse attention module中的参数,为了避免过拟合。
经过$L$层,我们可以得到$L$个multigram的信息,其维度都是$[batch_size,hidden_size,seq_length]$。接下来,为了让句子的每一个字能够自适应的选择不同gram的feature map,LRCNN借鉴了《Densely Connected CNN with Multi-scale Feature Attention for Text Classification》link paper中的multi-scale attention机制,具体如下:
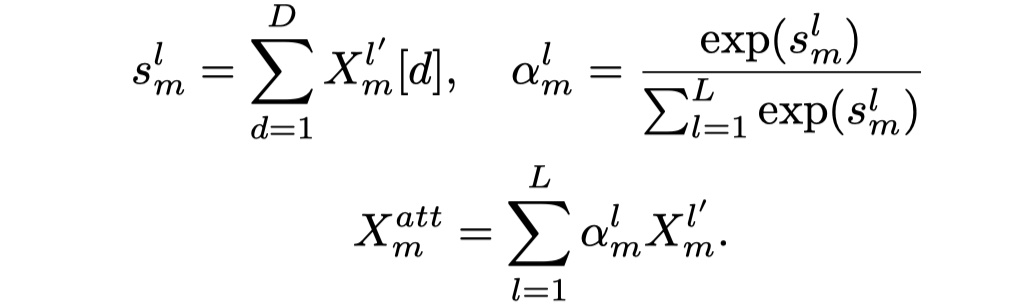
其中,$s_m^l$表示的是第L层的feature的第m个字对其D个特征进行求和得到的scalar,我们最终输入到CRF层的是:$X^{att}=\{X_1^{att},X_2^{att},…,X_M^{att}\}$。
实验结果
数据集仍然是那四个:MSRA、OntoNotes、Weibo、Resume
参数设定:initial learning rate:0.0015 with decay rate:0.05,dropout rate:0.5 on char embedding,lexicon embedding,cnn layers; char embedding(50) and lexicon embedding(50) were initialized by pretained embedding and fine_tuned during training; four cnn layer with 128 output channels for other datasets except MSRA(5 cnn layer with 300 channels);use earlystopping.
结果
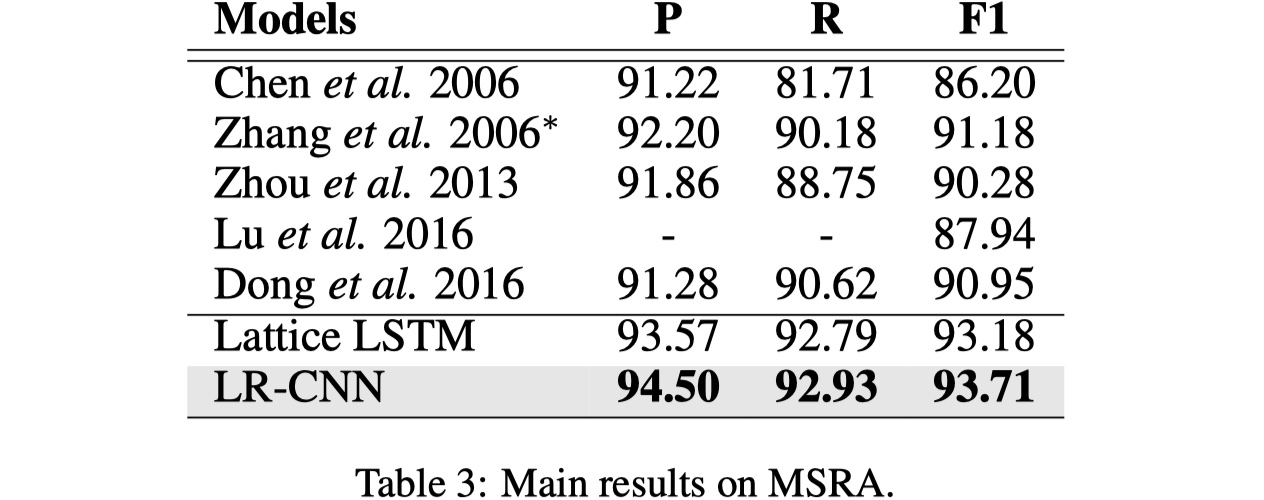
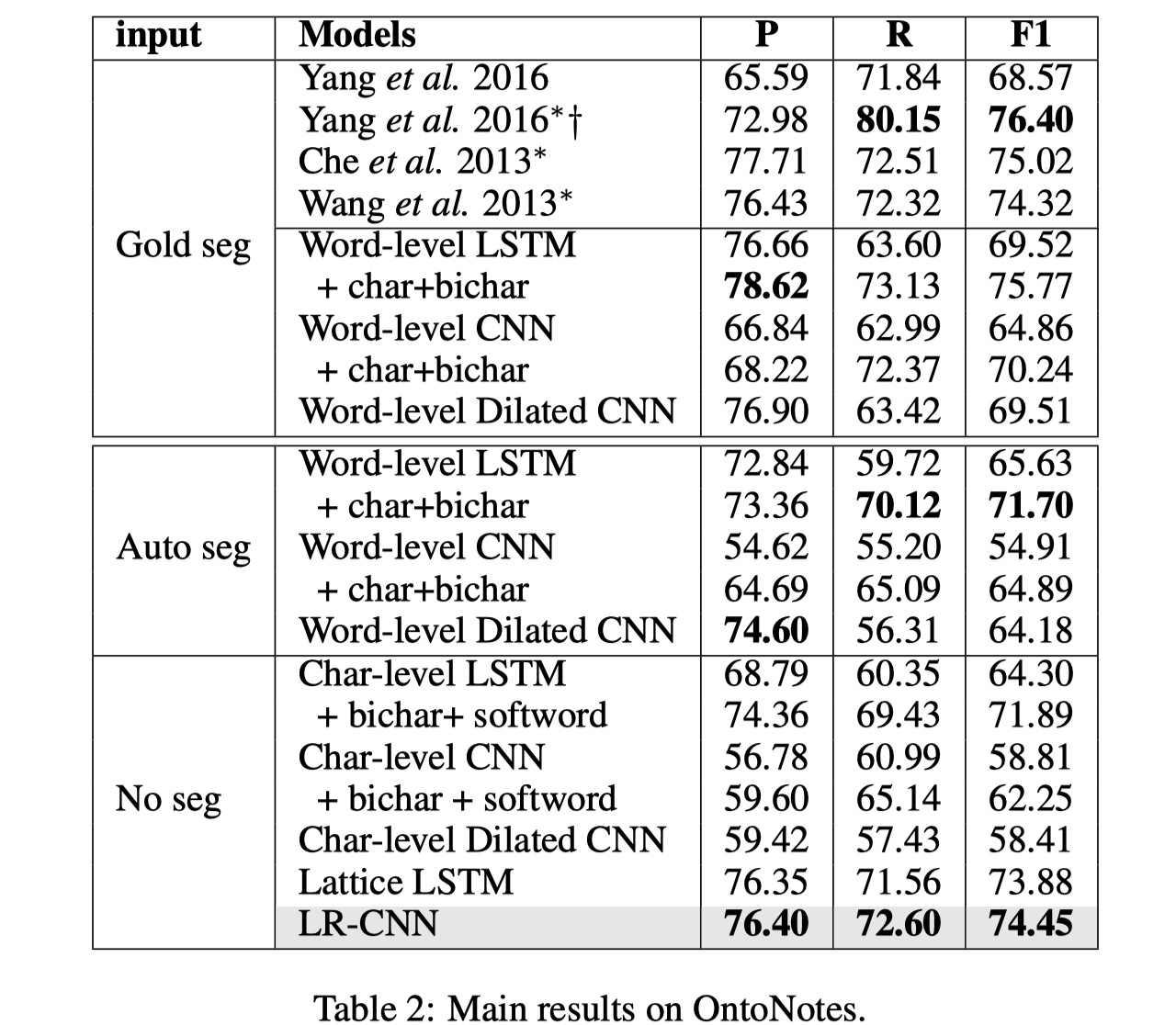
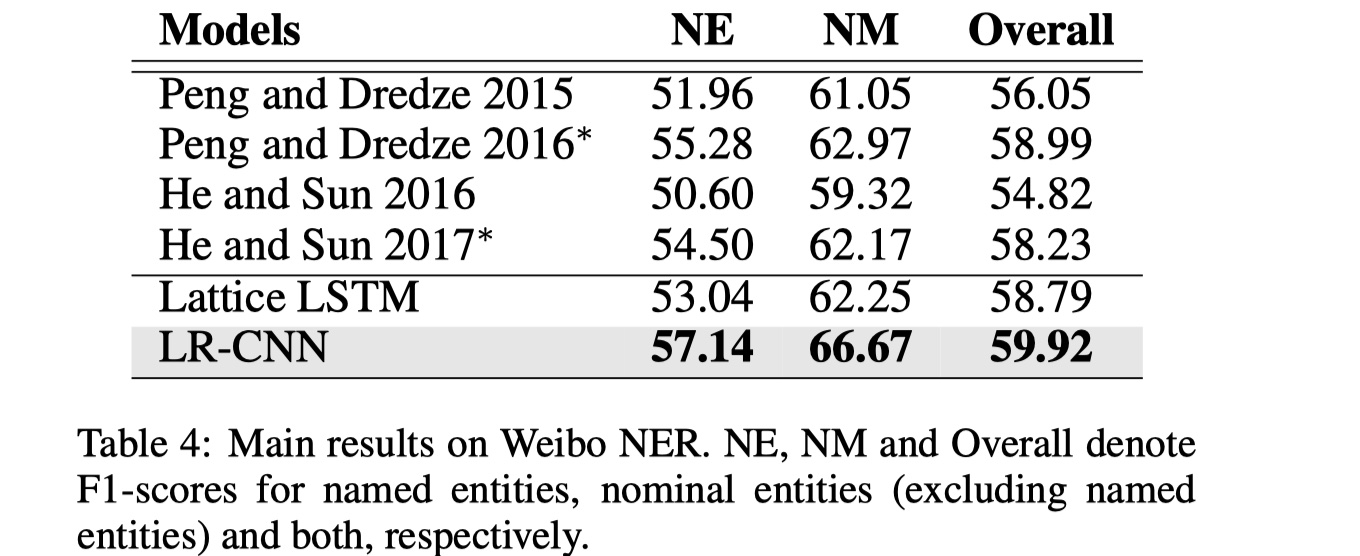
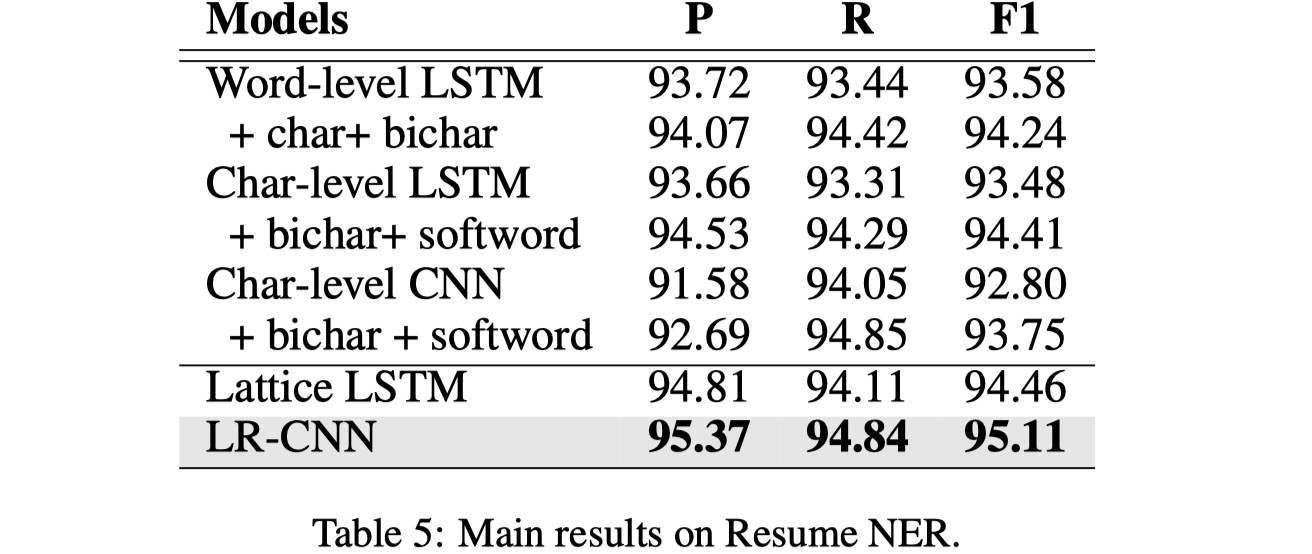
从实验结果来看,LRCNN还是不错的,不过我个人的感觉就是还是太过于复杂了,主要是rethinking那块,应该不是很好迁移到其他模型上。
参考文献
《CNN-Based Chinese NER with Lexicon Rethinking》
《Densely Connected CNN with Multi-scale Feature Attention for Text Classification》
LRCNN-code:https://github.com/gungunXD/LR-CNN

