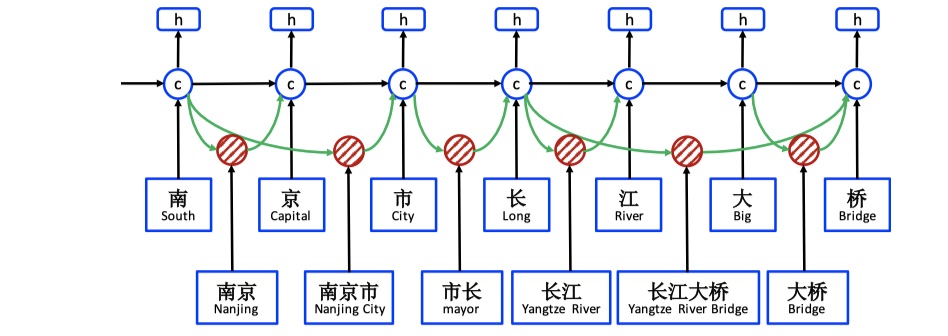
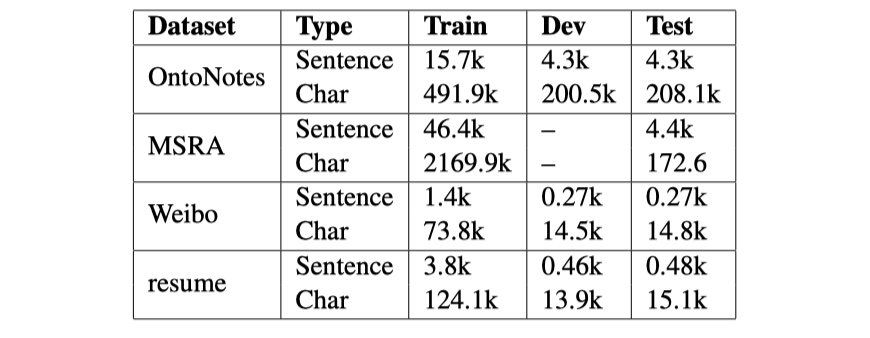
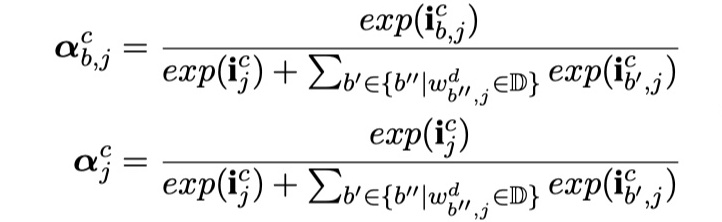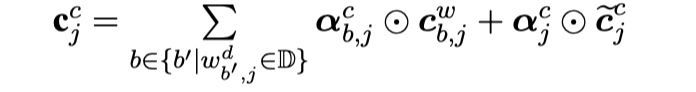1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
| class MultiInputLSTMCell(nn.Module):
"""A basic LSTM cell."""
def __init__(self, input_size, hidden_size, use_bias=True):
"""
Most parts are copied from torch.nn.LSTMCell.
"""
super(MultiInputLSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.use_bias = use_bias
self.weight_ih = nn.Parameter(
torch.FloatTensor(input_size, 3 * hidden_size))
self.weight_hh = nn.Parameter(
torch.FloatTensor(hidden_size, 3 * hidden_size))
self.alpha_weight_ih = nn.Parameter(
torch.FloatTensor(input_size, hidden_size))
self.alpha_weight_hh = nn.Parameter(
torch.FloatTensor(hidden_size, hidden_size))
if use_bias:
self.bias = nn.Parameter(torch.FloatTensor(3 * hidden_size))
self.alpha_bias = nn.Parameter(torch.FloatTensor(hidden_size))
else:
self.register_parameter('bias', None)
self.register_parameter('alpha_bias', None)
self.reset_parameters()
def reset_parameters(self):
"""
Initialize parameters following the way proposed in the paper.
"""
init.orthogonal(self.weight_ih.data)
init.orthogonal(self.alpha_weight_ih.data)
weight_hh_data = torch.eye(self.hidden_size)
weight_hh_data = weight_hh_data.repeat(1, 3)
self.weight_hh.data.set_(weight_hh_data)
alpha_weight_hh_data = torch.eye(self.hidden_size)
alpha_weight_hh_data = alpha_weight_hh_data.repeat(1, 1)
self.alpha_weight_hh.data.set_(alpha_weight_hh_data)
if self.use_bias:
init.constant(self.bias.data, val=0)
init.constant(self.alpha_bias.data, val=0)
def forward(self, input_, c_input, hx):
"""
Args:
batch = 1
input_: A (batch, input_size) tensor containing input
features.
c_input: A list with size c_num,each element is the input ct from skip word (batch, hidden_size).
hx: A tuple (h_0, c_0), which contains the initial hidden
and cell state, where the size of both states is
(batch, hidden_size).
Returns:
h_1, c_1: Tensors containing the next hidden and cell state.
"""
h_0, c_0 = hx
batch_size = h_0.size(0)
assert(batch_size == 1)
bias_batch = (self.bias.unsqueeze(0).expand(batch_size, *self.bias.size()))
wh_b = torch.addmm(bias_batch, h_0, self.weight_hh)
wi = torch.mm(input_, self.weight_ih)
i, o, g = torch.split(wh_b + wi, split_size=self.hidden_size, dim=1)
g = torch.tanh(g)
o = torch.sigmoid(o)
c_num = len(c_input)
if c_num == 0:
f = 1 - i
c_1 = f*c_0 + i*g
h_1 = o * torch.tanh(c_1)
else:
c_input_var = torch.cat(c_input, 0)
alpha_bias_batch = (self.alpha_bias.unsqueeze(0).expand(batch_size, *self.alpha_bias.size()))
c_input_var = c_input_var.squeeze(1)
alpha_wi = torch.addmm(self.alpha_bias, input_, self.alpha_weight_ih).expand(c_num, self.hidden_size)
alpha_wh = torch.mm(c_input_var, self.alpha_weight_hh)
alpha = torch.sigmoid(alpha_wi + alpha_wh)
alpha = torch.exp(torch.cat([i, alpha],0))
alpha_sum = alpha.sum(0)
alpha = torch.div(alpha, alpha_sum)
merge_i_c = torch.cat([g, c_input_var],0)
c_1 = merge_i_c * alpha
c_1 = c_1.sum(0).unsqueeze(0)
h_1 = o * torch.tanh(c_1)
return h_1, c_1
def __repr__(self):
s = '{name}({input_size}, {hidden_size})'
return s.format(name=self.__class__.__name__, **self.__dict__)
class LatticeLSTM(nn.Module):
"""A module that runs multiple steps of LSTM."""
def __init__(self, input_dim, hidden_dim, word_drop, word_alphabet_size, word_emb_dim, pretrain_word_emb=None, left2right=True, fix_word_emb=True, gpu=True, use_bias = True):
super(LatticeLSTM, self).__init__()
skip_direction = "forward" if left2right else "backward"
print "build LatticeLSTM... ", skip_direction, ", Fix emb:", fix_word_emb, " gaz drop:", word_drop
self.gpu = gpu
self.hidden_dim = hidden_dim
self.word_emb = nn.Embedding(word_alphabet_size, word_emb_dim)
if pretrain_word_emb is not None:
print "load pretrain word emb...", pretrain_word_emb.shape
self.word_emb.weight.data.copy_(torch.from_numpy(pretrain_word_emb))
else:
self.word_emb.weight.data.copy_(torch.from_numpy(self.random_embedding(word_alphabet_size, word_emb_dim)))
if fix_word_emb:
self.word_emb.weight.requires_grad = False
self.word_dropout = nn.Dropout(word_drop)
self.rnn = MultiInputLSTMCell(input_dim, hidden_dim)
self.word_rnn = WordLSTMCell(word_emb_dim, hidden_dim)
self.left2right = left2right
if self.gpu:
self.rnn = self.rnn.cuda()
self.word_emb = self.word_emb.cuda()
self.word_dropout = self.word_dropout.cuda()
self.word_rnn = self.word_rnn.cuda()
def random_embedding(self, vocab_size, embedding_dim):
pretrain_emb = np.empty([vocab_size, embedding_dim])
scale = np.sqrt(3.0 / embedding_dim)
for index in range(vocab_size):
pretrain_emb[index,:] = np.random.uniform(-scale, scale, [1, embedding_dim])
return pretrain_emb
def forward(self, input, skip_input_list, hidden=None):
"""
input: variable (batch, seq_len), batch = 1
skip_input_list: [skip_input, volatile_flag]
skip_input: three dimension list, with length is seq_len. Each element is a list of matched word id and its length.
example: [[], [[25,13],[2,3]]] 25/13 is word id, 2,3 is word length .
"""
volatile_flag = skip_input_list[1]
skip_input = skip_input_list[0]
if not self.left2right:
skip_input = convert_forward_gaz_to_backward(skip_input)
input = input.transpose(1,0)
seq_len = input.size(0)
batch_size = input.size(1)
assert(batch_size == 1)
hidden_out = []
memory_out = []
if hidden:
(hx,cx)= hidden
else:
hx = autograd.Variable(torch.zeros(batch_size, self.hidden_dim))
cx = autograd.Variable(torch.zeros(batch_size, self.hidden_dim))
if self.gpu:
hx = hx.cuda()
cx = cx.cuda()
id_list = range(seq_len)
if not self.left2right:
id_list = list(reversed(id_list))
input_c_list = init_list_of_objects(seq_len)
for t in id_list:
(hx,cx) = self.rnn(input[t], input_c_list[t], (hx,cx))
hidden_out.append(hx)
memory_out.append(cx)
if skip_input[t]:
matched_num = len(skip_input[t][0])
word_var = autograd.Variable(torch.LongTensor(skip_input[t][0]),volatile = volatile_flag)
if self.gpu:
word_var = word_var.cuda()
word_emb = self.word_emb(word_var)
word_emb = self.word_dropout(word_emb)
ct = self.word_rnn(word_emb, (hx,cx))
assert(ct.size(0)==len(skip_input[t][1]))
for idx in range(matched_num):
length = skip_input[t][1][idx]
if self.left2right:
input_c_list[t+length-1].append(ct[idx,:].unsqueeze(0))
else:
input_c_list[t-length+1].append(ct[idx,:].unsqueeze(0))
if not self.left2right:
hidden_out = list(reversed(hidden_out))
memory_out = list(reversed(memory_out))
output_hidden, output_memory = torch.cat(hidden_out, 0), torch.cat(memory_out, 0)
return output_hidden.unsqueeze(0), output_memory.unsqueeze(0)
|