正式入对话的坑啦🤣对话是目前NLP技术重要的落地场景之一,但是相比于其他的方向,对话目前的应用还不算成熟,也远远没有产生它应有的巨大商业价值,但是随着物联网与5G等的发展,对话的应用前景是非常光明的。此外,既然对话的坑还有很多,这也意味着总需要人去填满这些坑,对NLPer来说,是挑战也是机会。其他的不多说,本篇着重讲讲检索式对话的经典模型MRFN。
MRFN模型介绍
MRFN模型是2019年PKU与MSRA在WSDM顶会上所发表的关于检索式对话的论文。个人认为这是一篇不可多得的好论文,实验做的很详细,而且在representation或者说是granularities上做到了极致,综合了目前几乎所有的表示方法。MRFN模型解决的是两个问题:1.怎么对多个representation进行融合?2.不同的representation对最终matching performance的贡献是怎么样的?下面就来一一介绍~
MRFN模型架构
首先给出一些定义:给定数据集:$\cal D=\{c_i,r_i,y\}_{i=1}^{N}$,其中,$c_i=\{u_{i,1},u_{i,2},..,u_{i,m_i}\}$,$u_{i,j}$表示第i个样本的第j个utterance in context,$y_i\in\{0,1\}$,目标是:衡量$c_i$与$r_i$之间的匹配度。下面直接模型结构图~
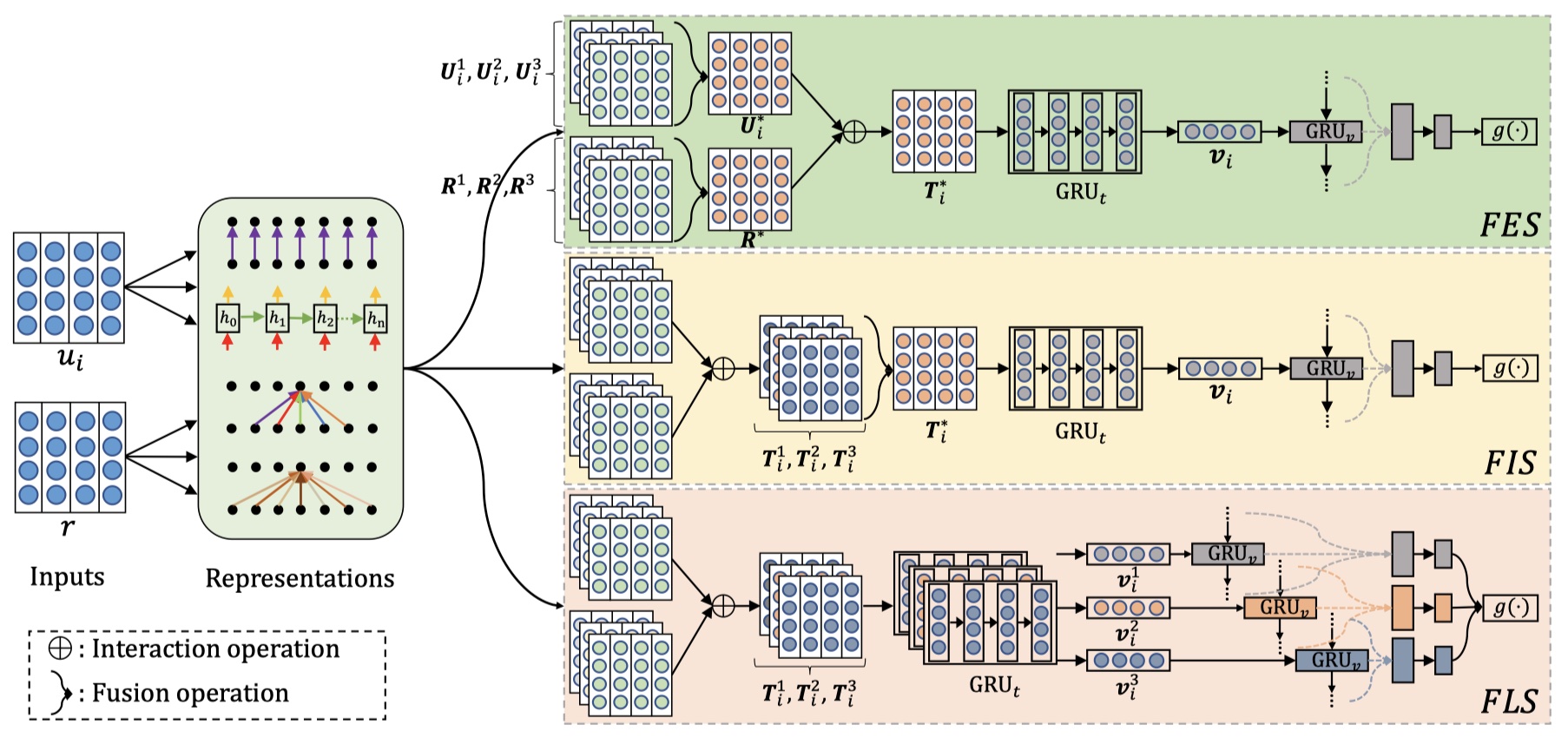
MRFN模型主要分为两大部分:Representations与Fusion strategies。下面依次介绍~
Representations
在MRFN模型中,有三种类型的representation:word representations, contextual representations, and attention-based representations。
- word representation分为两种:Character-based Word Embedding与Word2Vec。前者能够将subword的信息考虑进去,后者能够考虑corpus中的共现信息,为其他的表示打下基础。
- Character-based Word Embedding指的是将文本按照character来划分,得到的是4维向量,将这四维向量进行reshape,输入到激活函数为tanh的一维卷积中,再经过全局池化,得到二维向量,再经过reshape得到最终的三维向量;
- Word2Vec指的是使用word2vec训练得到的词向量作为初始化,并在训练过程中进行微调。
contextual representation分为两种:Sequential Representation与Local Representation。前者编码的是子序列的语义信息,后者编码的是n-gram的语义信息,两种都是旨在捕获单词之间的短期依赖关系。
- Sequential Representation指的是将输入的三维向量(是使用word2vec初始化的)经过GRU编码,return_sequence=True;
- Local Representation指的是使用4种不同卷积核尺寸的[1,2,3,4]卷积层对输入的三维向量(是使用word2vec初始化的)进行same卷积,各个卷积核的数目均一致,为:$n_c$,论文里使用的是50,最终对4个结果进行concat,得到最终的结果。
Attention-based Representations分为两种:self attention与cross attention。这种representation能够对单词之间的长期以来进行建模,以及对单词之间的重要性进行建模。
- self attention指的就是transformer中的attention机制,用公式来表达utterance $u$ 经过attention之后,得到的表示如下:
self attention与self attentio就在输入不一样,用公式来表达utterance $u_i$经过attention之后,得到的表示如下:
注意:attention的输出是word2vec初始化的三维向量!
Fusion Strategies
首先明确一下,经过上一步,我们现在得到的是:对于utterance $u_i$ in context,表示为:$\{U_i^k\}_{k=1}^K,K=6$;对于reponse r,表示为:$\{R^k\}_{k=1}^K,K=6$。也就是说,现在对于网络的输入是:context:$\{U_i^k\}_{k=1}^K,1<=i<=m$,response:$\{R^k\}_{k=1}^K$。OK,接着往下走~
我们得到了这么多的表示后,要得到最终的matching score,就必须要对这些表示进行融合,那么怎么融合呢?论文里考虑了三种融合策略:FES(Fusing at an early stage)、FIS(Fusion at an intermediate stage)、FLS(Fusion at the last stage)。下面依次来看~
FES
所谓的FES指的是,在utterance与response进行交互之前,就将各种表示进行融合。具体来说,对于utterance $u_i$来说,它的6种表示可以表述为:$\{U_i^k\}_{k=1}^K,K=6$,由于这6种表示都是三维的,且batch_size维度与seq_lengt维度相同,所以一个做法就是将这6种表示在最后一个维度上进行concat,最后得到的向量为:U_i*,其维度是:(batch_size,seq_length_u_i,hidden_units);同样的,得到的reponse的向量为:R*,其维度是:(batch_size,seq_length_r,hidden_units)。
得到每一个utterance与response的表示之后,就需要对utterance in context与response进行交互。如下:
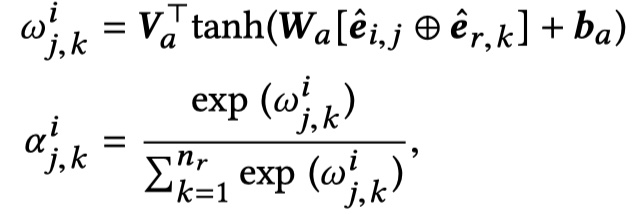
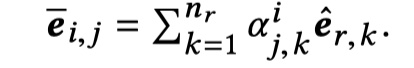
然后将 U_i* 与 $\overline e_{i,j}$ 一起送入CompAgg模型中提出的SUBMULT+NN方法中,从而得到 $T_i^*\in R^{n_i\times d}$。具体 $t_{i,j}$ 的计算如下:
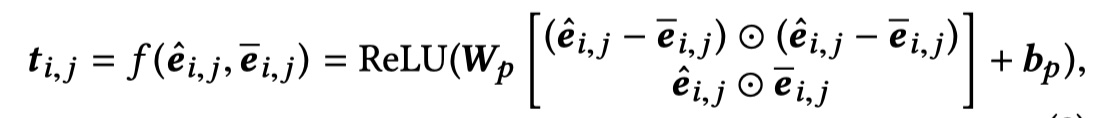
然后在此基础上,使用GRU+MLP,得到最终的matching score。
FIS
在FIS中,对每种表示形式都执行utterance与response交互。然后对结果进行fusion,在经过GRU+MLP,得到matching score。
FLS
在FLS中,对每种表示形式都执行utterance与response交互,经过GRU,然后对结果进行fusion,在经过GRU+MLP,得到matching score。
结果证明,FLS效果最好。
details
- 数据集:UDC、douban
- 评价指标:MAP、MRR、$P@1$、$R_n@k$
- sequential representation使用的GRU的维度为200,其他部分使用的GRU的最佳维度是1000
- batch size为100,学习率为0.001,采用earlystoping
结果
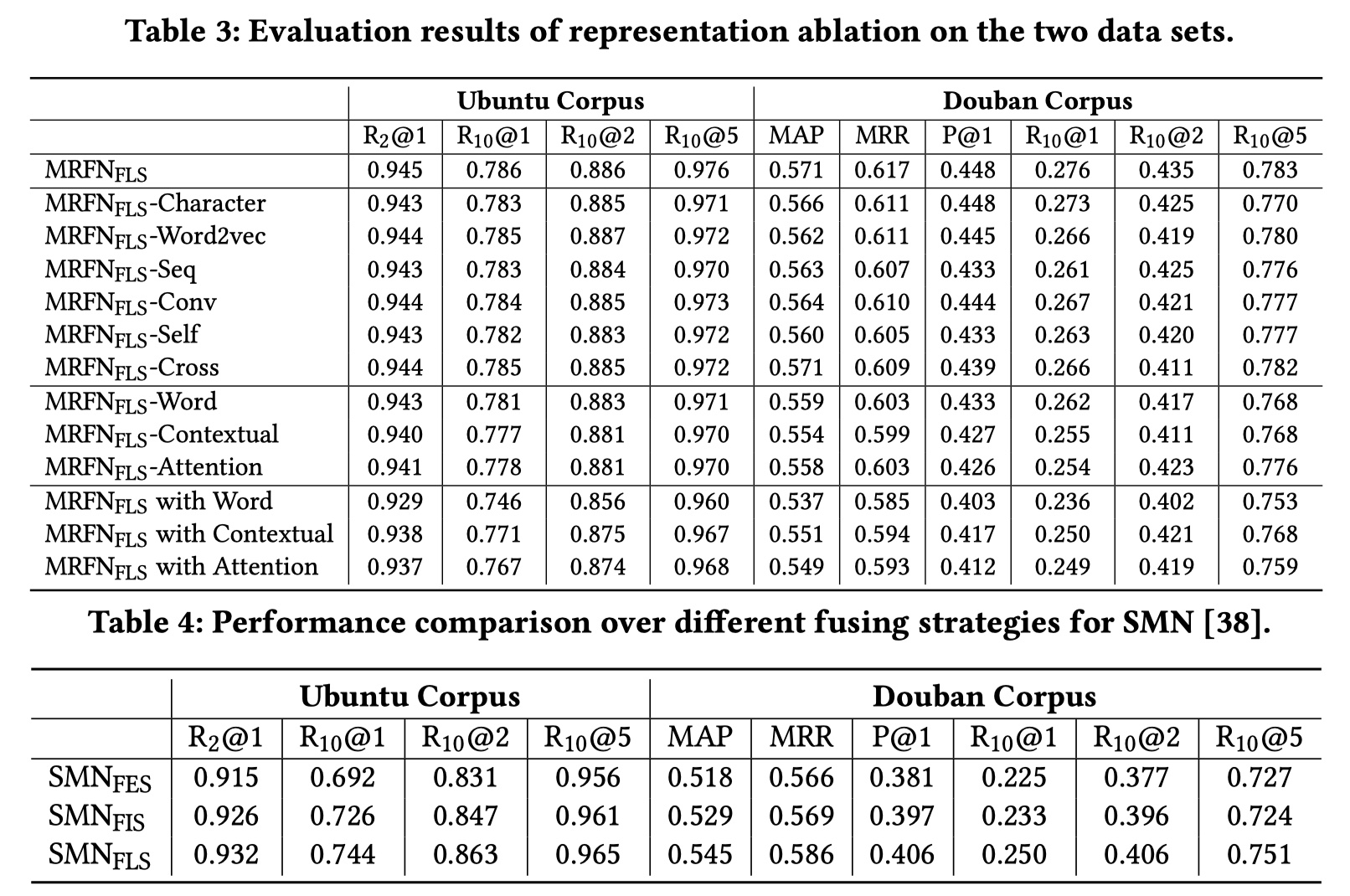
结果不错~
最后说一点点叭,关于检索式对话近期可能不会再看了。看了这么多篇paper,其实都差不多,基本上就是representation-matching-aggregation这样一个框架,但是每一个部分都能够去做修改和探索。之后可能会去看看生成式对话的东西(不知道为什么,总是对生成式任务有着谜一般的执念🤣),然后可能再去看看强化学习的东西吧,毕竟对话要离开DRL的东西很难。其实我还是蛮想做pretraining的东西,或者MRC/VQA也行啊(如果有人带我的话),但是摸得GPU啊,要是intern能做preretraining这块的话,就灰常好了(洗洗睡吧)。然后主要就是去做实现这块吧,感觉代码能力还是蛮重要的。就是这样了,keep learning,加油~
MRFN模型实现
参考文献
Multi-Representation Fusion Network for Multi-turn Response Selection in Retrieval-based Chatbots

