正式入对话的坑啦🤣对话是目前NLP技术重要的落地场景之一,但是相比于其他的方向,对话目前的应用还不算成熟,也远远没有产生它应有的巨大商业价值,但是随着物联网与5G等的发展,对话的应用前景是非常光明的。此外,既然对话的坑还有很多,这也意味着总需要人去填满这些坑,对NLPer来说,是挑战也是机会。其他的不多说,本篇着重讲讲检索式对话的经典模型IMN。
IMN模型介绍
IMN是2019年中科大发表在CIKM上的一篇论文,整个模型与SMN比较像,但是做了很多的改进,实验也做的比较扎实。总的来看:IMN模型的优势在于:1.使用char embedding来解决OOV问题,同时也加强了word的表示;2.使用了类似于ELMo的结构来做sentence encoder,从而增强sentence的表示;3.使用全局的方式来让context与response进行交互,而不是以往的那种每一个utterance in context分别与response进行交互,从而能够挑选出context中与response最相关的部分(有点pooling的味道?🧐)。下面直接介绍吧~
IMN模型架构
首先给出定义:给出数据集:$\cal D=\{c,r,y\}_1^N$,其中$c=\{u_1,u_2,…,u_n\}$,表示context;r表示response,$y=\{0,1\}$,表示标签,目标是:得到context与response的匹配度。下面给出架构图~
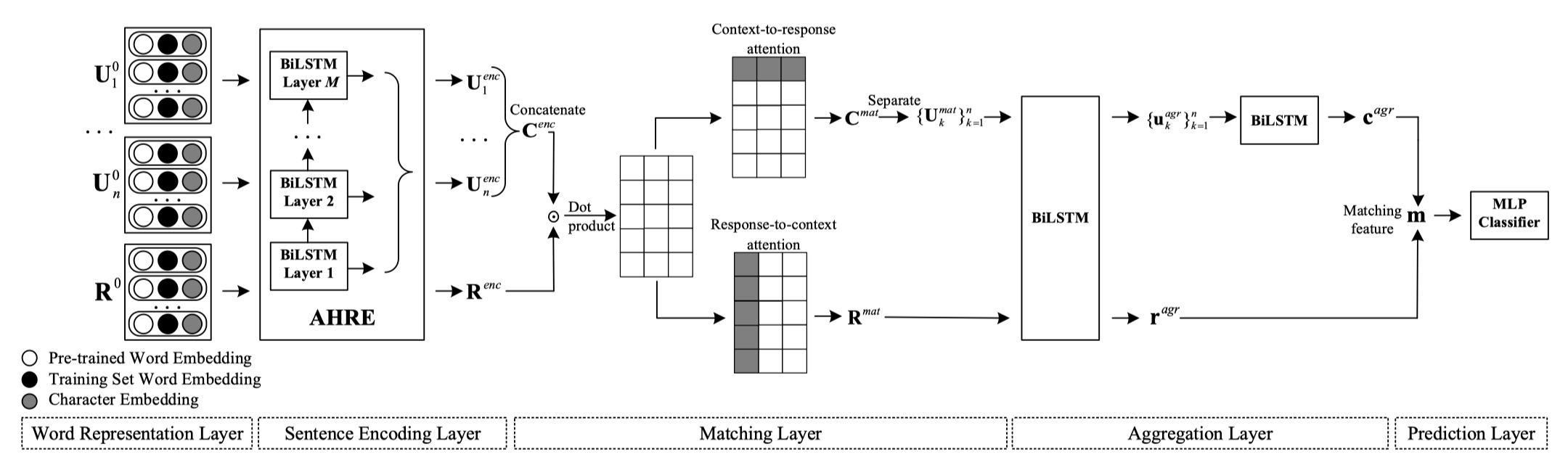
IMN模型总共分为5部分,下面一一介绍~
word representation layer
这一部分是模型最初的输入,分为三部分:pre-train word embedding、training set word embedding、character embedding,分别对应于:斯坦福发布的GloVe/Google的word2vec词向量、在训练集上使用word2vec得到的词向量、字向量(随机初始化)。最终的输出是这三个embedding的concat,表示为:$U_{k}^{0}=\{u_{k,i}^{0}\}_{i=1}^{l_{u_k}}$、$R^0=\{r_{j}^{0}\}_{j=1}^{l_r}$,$u_{k,i}^{0}\in R^d、r_{j}^{0}\in R^d$。
注意:当一个模型的输入既有word embedding又有char embedding的时候,那么对于一个sentence来说,word embedding一定是3维的,char embedding一定是4维的,这个时候我们是无法直接将word embedding与char embedding进行concat或者是作为两个channel,那么怎么办呢?从我目前看到的模型中,基本上有两种解决办法:
1.对char embedding进行reshape,变成3维的,然后输入一个lstm中,然后将lstm的输出再次进行reshape,将结果与word embedding进行concat/channel;
2.对char embedding进行reshape,变成3维的,然后输入到一个cnn中,然后将结果使用reduce_mean,reduce_sum等等操作(或者使用全局池化),使得结果变成2维的,然后再次进行reshape,将结果与word embedding进行concat/channel。
在IMN模型中,使用的是第二种方法,论文中没有具体说,但是如果去看它的开源代码的话,可以看到就是这样实现的。另外,第一种方法在BIMPM模型中有用到,感兴趣的可以去翻翻我之前关于BIMPM模型的解读~
sentence encoding layer
这一层主要是提出了一个sentence encoder,从而来得到一个好的sentence embedding。那具体怎么做的呢?在IMN模型中,它借鉴了ELMo模型中的结构。与以往的模型一样,它也是堆叠多层的BILSTM(论文里是三层),但是不同的是,以往的很多模型只使用最顶层的BILSTM的输出,而忽略了中间层的输出结果。实际上,中间层的输出结果同样也表示了很多的信息,只是相对于高层的输出而言,它表示的是较为低层的语义特征。所以,为了得到更好的sentence embedding,IMN模型中将所有层的输出都保留下来,并且还训练了softmax,得到了所有层的权重,最终的输出是所有层的加权求和,它把这种结构叫做:attentive hierarchical recurrent encoder (AHRE)。下面用公式来表达:
有M个层,对于第k个utterance,表示为:$\{U_k^1,U_k^2,…,U_k^M\}$,response表示为:$\{R^1,R^2,…,R^M\}$;最终context的输出表示为:$U_K^{enc}=\{u_{k,i}^{enc}\}_{i=1}^{l_{u_k}}$,response的输出为:$R^{enc}=\{r_{j}^{enc}\}_{j=1}^{l_r}$,其中:
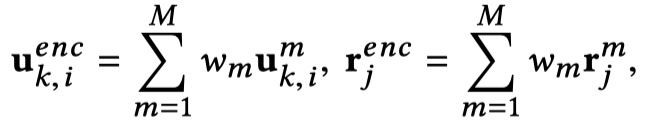
matching layer
在这块,IMN模型中采用的是将整个context与response进行match,而不是每一个utterance分别与response进行match。那么,context表示为:$C^{enc}=\{c_i^{enc}\}_{i=1}^{l_c} where l_c=\sum_{k=1}^{n}l_{u_k}$。然后将context与response进行dot preduct,即:$e_{ij}=(c_i^{enc})^T r_j^{enc}$。然后在此基础上,计算context-to-response representation $\overline R^{enc}=\{\overline r_j^{enc}\}_{j=1}^{l_r}$与response-to-context representation $\overline C^{enc}=\{\overline c_i^{enc}\}_{i=1}^{l_c}$,依次如下:
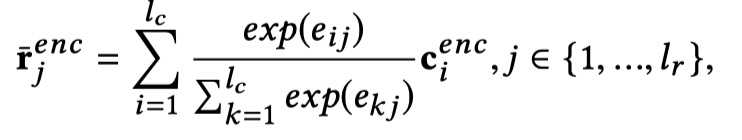
$\overline c_i^{enc}$的计算方法与$\overline r_j^{enc}$一样。然后在此基础上,形成两个矩阵,如下:
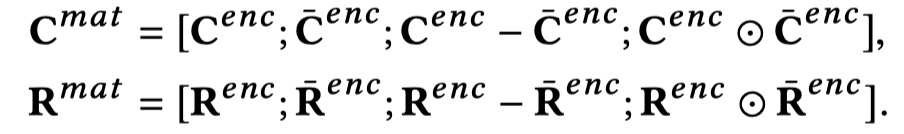
另外,得到$C^{mat}$之后,需要进行seperate,因为一开始是进行了flatten,得到$\{U_k^{mat}\}_{k=1}^{n}$。
aggregation layer
这一层就是将上一层的输出:$\{U_k^{mat}\}_{k=1}^{n}$以及$R^{mat}$作为输入,然后经过BILSTM,得到:$U^{agr}=\{u_k^{agr}\}_{k=1}^{n}$与$r^{agr}$。由于得到的$U^{agr}=\{u_k^{agr}\}_{k=1}^{n}$是一个三维的向量,所以再经过一层BILSTM,得到$c^{agr}$。最终的输出是:$m=[c^{agr};r^{agr}]$。
prediction layer
这一层是将$m$输入到一个MLP中,激活函数为relu,然后再经过线性层,使用sigmoid,得到最终的输出结果。最终的损失函数为cross entropy。
details
- 数据集:UDC V1,UDC V2,douban,e-commerce dialogue corpus
- 评价指标:$R_n@k$、MAP、MRR、$P@1$
- 优化器:adam
- 对于中文数据集,batch size为128,英文数据集为96
- 初始学习率为0.001,每5000step指数衰减0.96
- dropout应用与word embedding与所有的隐藏层,dropout为0.2
- 使用300维的GloVe词向量,100维的使用word2vec训练训练集得到的词向量,使用150维的char embedding(使用了3个卷积层[3,4,5],每一次卷积有50个filters)
结果
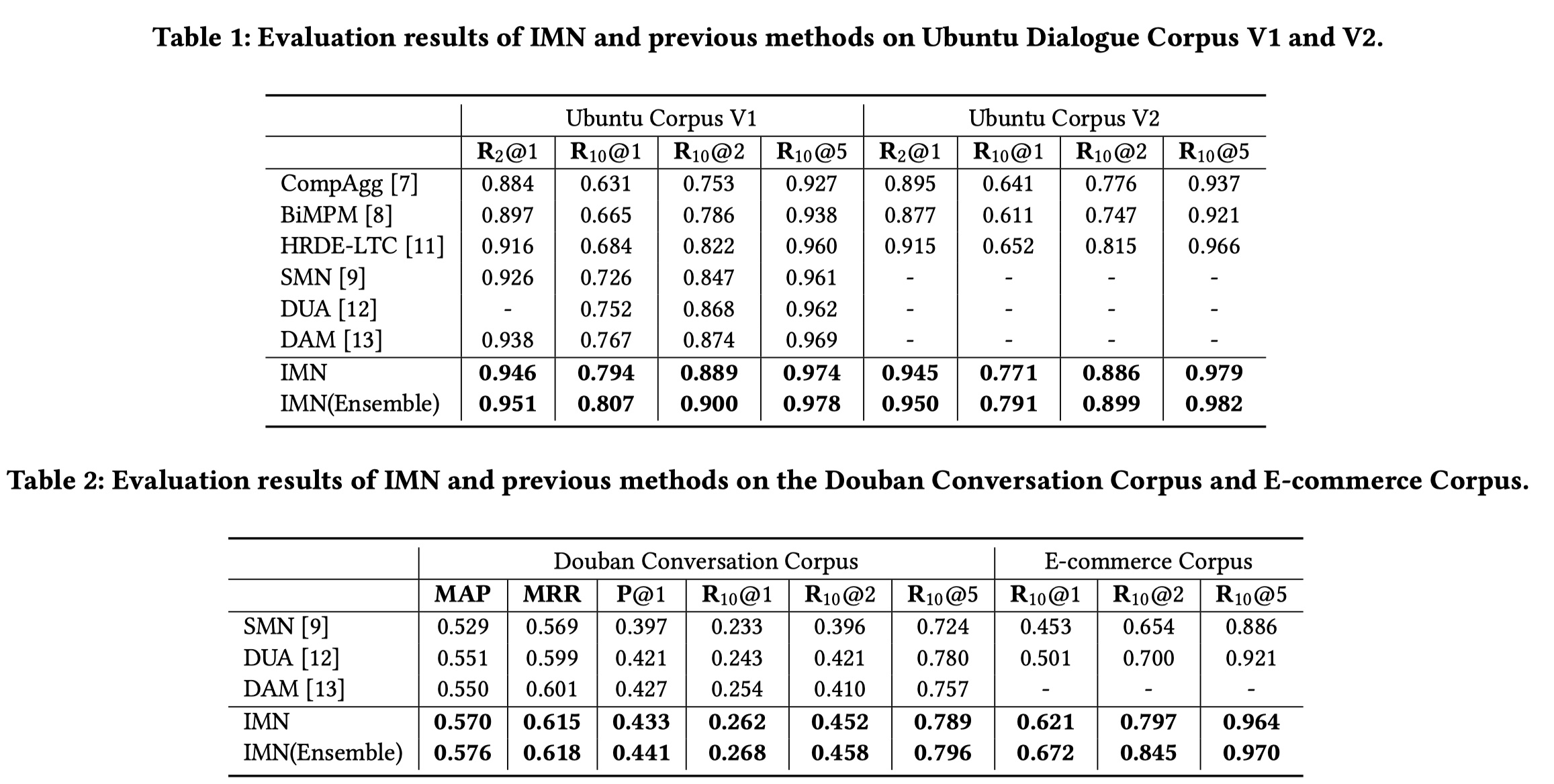
从结果上看,IMN表现还是不错的,但是有一个疑问,CompAgg以及BIMPM也可以用于多轮对话吗?🧐
IMN模型实现
参考文献
Interactive Matching Network for Multi-Turn Response Selection in Retrieval-Based Chatbots

