正式入对话的坑啦🤣对话是目前NLP技术重要的落地场景之一,但是相比于其他的方向,对话目前的应用还不算成熟,也远远没有产生它应有的巨大商业价值,但是随着物联网与5G等的发展,对话的应用前景是非常光明的。此外,既然对话的坑还有很多,这也意味着总需要人去填满这些坑,对NLPer来说,是挑战也是机会。其他的不多说,本篇着重讲讲检索式对话的经典模型SMN。
SMN模型介绍
SMN模型是检索式对话中一篇非常有影响力的工作。由于attention机制在2016年后大幅兴起,所以SMN模型的思路也是基于交互的方式,来做context与response的match。首先讲讲SMN所要解决的问题:1.怎么在context中辨别出对选出合理response的有用的重要信息?2.怎么对context中的utterances之间的关系进行建模?针对于第一个问题,SMN模型使用基于交互的方式,从一开始就让context中每一个utterance与respons进行不同粒度的matching,并且使用卷积和池化来提取出重要的信息;针对于第二个问题,对得到utterance embedding,使用GRU来进行encoder,最终通过accumulation得到context embedding。明确了SMN所要解决的问题后,下面就具体讲讲具体的SMN模型架构与细节~
SMN模型架构
首先定义一些符号:数据集:$\{(y_i,s_i,r_i)\}_{i=1}^{N},s_i=\{u_{i,1},u_{i,2},u_{i,3},…,u_{i,n_i}\},y_i\in \{0,1\}$,其中,$y_i$表示第i个样本的label,$s_i$表示第i个样本中的context(包括多个utterances),$r_i$表示第i个样本的一个候选回复(合理回复/不合理回复)。我们的目标是:对于一对$(s,r)$,得出其匹配度,对于chatbot来说,我们要从candidate responses中选出匹配度最高的回复。SMN架构还是挺好懂的,直接放图吧~
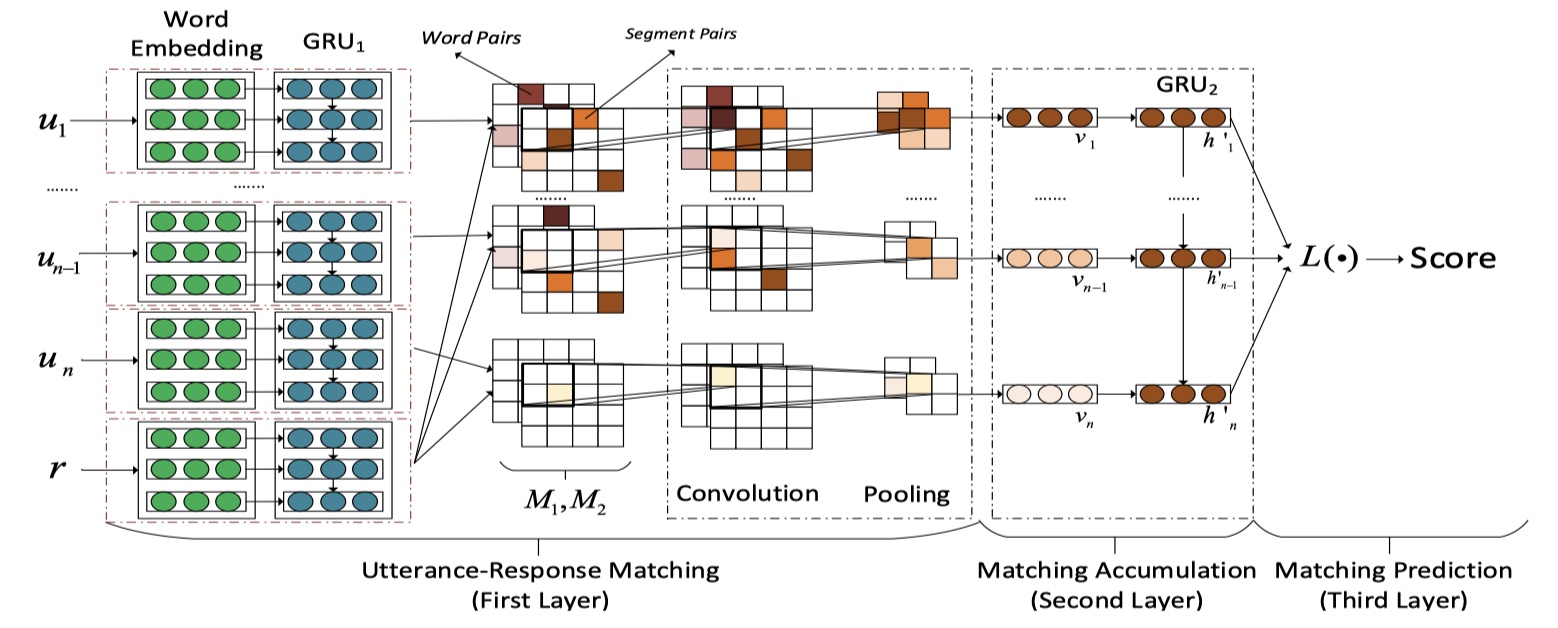
SMN模型分为三个部分:utterance-response matching layer、matching accumulation layer、matching prediction layer。下面依次介绍~
utterance-response matching layer
这一层是让context中的每一个utterance与response进行matching,输出是word-word similarity matrix与sequence-sequence similarity matrix。具体来说,对于一个给定的utterance:$U=[e_{u,1},…,e_{u,n_u}]$与一个response:$R=[e_{r,1},…,e_{r,n_r}],U\in R^{d\times n_u},R\in R^{d\times n_r}$。我们使用$U$与$R$来构建word-word similarity matrix($M_1$)与sequence-sequence similarity matrix($M_2$)。
- $M_1$的构建相对简单,直接使用utterance与response的word embedding sequence来进行dot即可,得到的结果的维度:$M_1\in R^{n_u\times n_r}$。
- $M_2$的构建相对复杂一点。我们需要将utterance与response的word embedding sequence输入到GRU层中,得到编码过之后的word embedding sequence:$H_u=[h_{u,1},h_{u,2},…,h_{u,n_u}]$、$H_r=[h_{r,1},h_{r,2},…,h_{r,n_r}]$,然后在将$H_u$与$H_r$进行dot,即:$e_{2,i,j}=h_{u,i}^{T}Ah_{r,j}$。其中,$A\in R^{m\times m}$。得到的结果的维度是:$M_2\in R^{n_u\times n_r}$。
得到$M_1$与$M_2$之后,将其作为CNN的两个channel,输入到CNN当中,做二维卷积,然后再使用全局二维池化。注意:CNN的输入维度是:$(seqLengthUtterance,seqLengthResponse,2)$,最终通过全局池化的输出的维度是:$(numFilters,)$。注意,对于一个utterance与response,经过全局池化的输出的维度是:$(numFilters,)$,由于有n个utterance,所以有n个$(numFilters,)$,维度是:$(n,numFilters)$。
Note:这里没有算上batch_size维度,也没有算上num_utterance这个维度,针对的就是一个utterance的计算!具体复现论文的时候,需要注意一下tensor的维度。
matching accumulation layer
经过utterance-response matching layer,每一个向量都表示一个utterance embedding,然后将其输入到GRU中,进行编码。得到$[h_1^{ ‘},h_2^{ ‘}…,h_n^{ ‘}]$。然后使用$L$函数,得到最终的context embedding。
matching prediction layer
通过matching accumulation layer,我们可以得到$[h_1^{ ‘},h_2^{ ‘}…,h_n^{ ‘}]$,在此基础上,使用$L$函数,得到最终的context embedding。在论文中,$L$有三种方式。
- $SMN_{last}$:$L([h_1^{ ‘},h_2^{ ‘}…,h_n^{ ‘}])=h_n^{ ‘}$;
- $SMN_{static}$:$L([h_1^{ ‘},h_2^{ ‘}…,h_n^{ ‘}])=\sum_{i=1}^{n}w_ih_i^{ ‘}$;
- $SMN_{dynamic}$:使用与HAN模型类似的attention机制,如下:
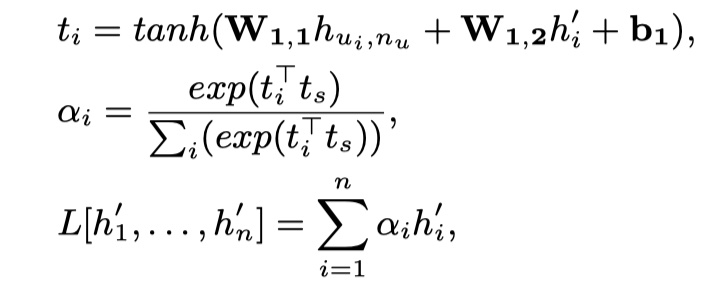
其中,$h_{u_i,n_u}$是第i个utterance通过GRU之后的最后一个位置的向量。
得到最终的context embedding之后,然后送入softmax中,得到最终的结果。如下:
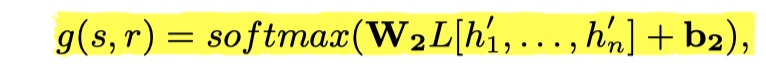
details
- 损失函数:cross entropy。如下:
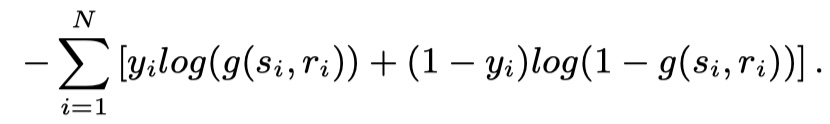
- 数据集:Douban conversation corpus
- 评价指标:$R_n@k$,MAP,MRR
- word embedding:使用word2vec预训练得到的200维向量
- GRU维度:200
- 卷积和池化的window大小:(3,3)
- 第二层的GRU维度:50
- batch_size:200
- 每一个utterance的最大长度为50,每一个context的最大的utterance的数目为10。如果context中utterance的数目大于10,那么取最近的前10个,否则,padding
- 初始学习率:0.001,应用earlystopping
结果
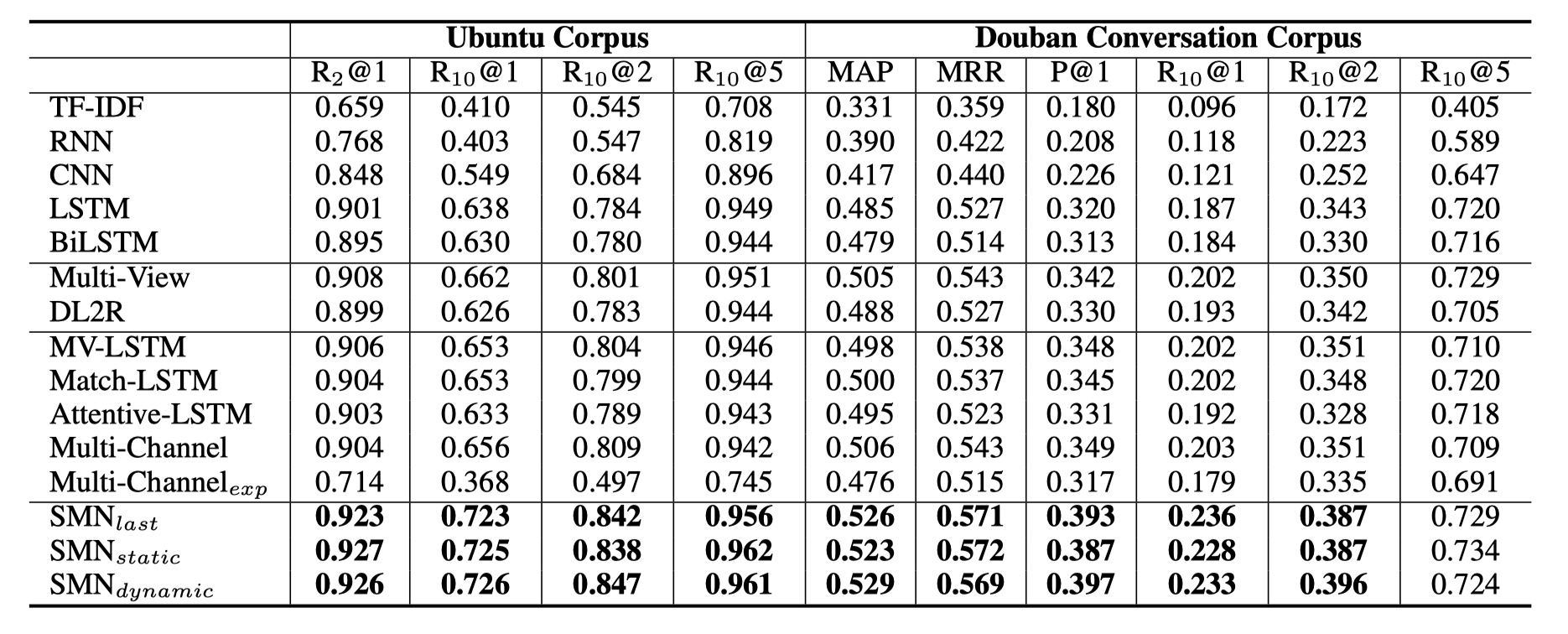
从结果来看,SMN模型要好于Multi-view模型,还是非常不错的。从这也说明,基于交互的匹配方式要比基于表示的好很多,并且多粒度表示对于性能的提升也是很有帮助的~
SMN模型实现
参考文献
Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots

