正式入对话的坑啦🤣对话是目前NLP技术重要的落地场景之一,但是相比于其他的方向,对话目前的应用还不算成熟,也远远没有产生它应有的巨大商业价值,但是随着物联网与5G等的发展,对话的应用前景是非常光明的。此外,既然对话的坑还有很多,这也意味着总需要人去填满这些坑,对NLPer来说,是挑战也是机会。其他的不多说,本篇着重讲讲检索式对话的经典模型DUA。
DUA模型介绍
DUA模型是2018年SJTU所发表的一篇论文,在检索式对话当中也是非常有影响力的一片论文。不管是Multi-view还是SMN模型,其实并没有对utterances之间的关系进行很好的建模(即使是在SMN中,也只是对utterances使用简单的GRU就完事了),而且每一个utterance对于得到合理response的作用是不一样的,所以不应该享有同样的权重(attention),所以,DUA模型针对于这一点做出了改进,对utterance也进行了深度的encoding。下面将介绍DUA模型的详细细节,注意,DUA模型相对来说,个人认为有些细节还是挺难理解de1,符号定义得乱七八糟的,而且该讲清楚的没讲清楚,所以一定要仔细地下面的讲解(或者原始论文)~
回过头来看,我还是要吐槽一下,符号定义的真的乱七八糟,这是我读过的符号使用最混乱的paper。。。
DUA模型架构
首先给出一些定义:训练集的一个sample表示为:[C,R,Y],其中$ C=\{U_1,U_2,…,U_t\}$, 另外$U_k$表示第k个utterance,R表示一个response,Y表示label(合理回复/不合理回复)。目标是:衡量context于response的匹配度。先给出模型图吧~
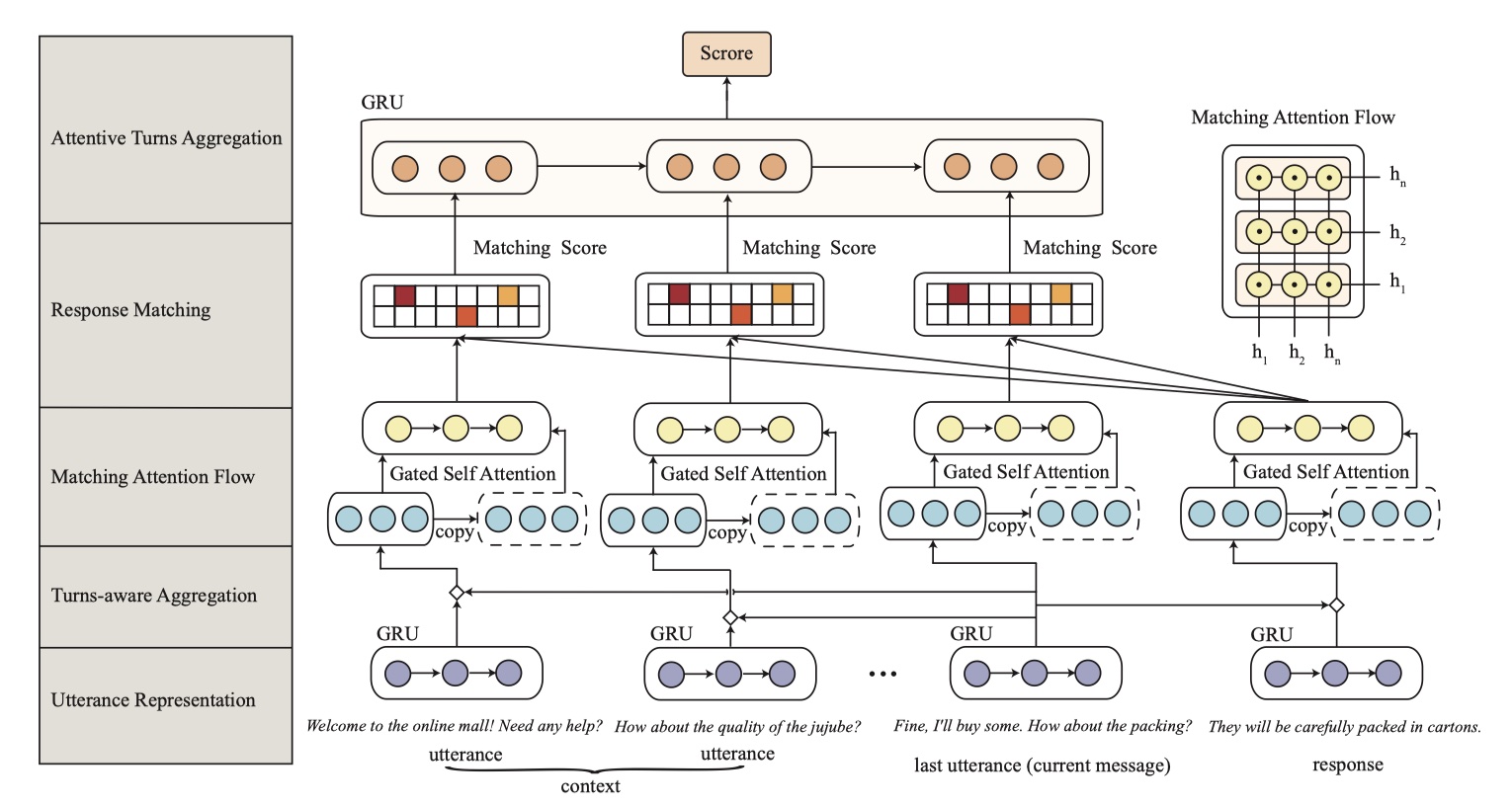
模型架构和SMN挺像的,但是更复杂了,有些细节还是挺难懂的,下面依次讲解~
utterance representation
- 这一层首先是将每一个utterance in context以及response进行encoding,得到相应的utterance embedding或response embedding。输入是:$C=\{U_1,U_2,…,U_t\}、R=[r_1,r_2,…,r_{n_r}]$,$U_k$表示第k个utterance,且:$U_k=[u_1,u_2,…,u_{n_u}]$,其中$u_i,r_i$分别表示utterance in context于response的第i个word的向量表示。
- 然后将每个utterance embedding与response embedding输入到GRU中,得到编码后的utterance与response向量,表示为:$S=[S_1,S_2,…,S_t]$与$S_r$,分别表示utterance in context 与response,$S_i\in R^n$。
turns-aware aggregation
这是DUA模型中最重要的地方,也是创新的地方。如果仅仅只有上面那一步对utterance的处理的话,会存在一个缺点:也就是所有的utterance都被一样的处理了,也就是说我们认为所有的utterance对得到合理的response都有同样的作用,但这是不对的。由于最后一个utterance对于得到合理response来说,是最重要的,所以在DUA中,我们将每一个utterance in context与其他的utterance(包括 response)进行融合,从而挖掘最后一个utterance与其他utterance(包括response)之间的关系。具体如下:
输入是上一层的输出:$S=[S_1,S_2,…,S_t]$与$S_r$,输出表示为:$F=[F_1,F_2,…,F_t,F_r]$。其中,$F_j=S_j\Diamond S_t$,$j\in \{1,…,t,r\}$。$\Diamond$运算符表示aggregation运算,在论文中,采取了concatenation的方式。
matching attention flow
这是DUA模型中最重要的地方,也是创新的地方。通过turns-aware aggregation,所有的utterance得到了再一次的encoding。但是此时的utterance过于冗长,且并不是所有的word都发挥了作用,所以我们要从中提取出有用且重要的信息。为了解决这个问题,DUA模型采用了R-net中的self-matching attention机制(所以MRC中的模型最好去看看,VQA最好也看看(co-attention),这些都是不分家的,莫得办法,keep learning🤷♂️)。具体如下:
输入是上一层的输出:$F=[F_1,F_2,…,F_t,F_r]$;对于任意的$\hat F=[f_1,f_2,…,f_n]\in F$,输出表示为:$P=[p_1,p_2,…,p_n]$。(这里我认为论文中写错了,并不是只有response这样处理,应该是所有的utterances(包括response)都这样处理才对。)注意:这里的$n$与utterance representation中的n是一样的。其中,$p_t$的计算公式如下:
其中,$c_t$是self matching attention机制得到的结果,具体计算过程如下:
这一层的输出是:$P=[P_1,P_2,…,P_t,P_r],where P_i=[p_1,p_2,…,p_n]$。
注意:这一层之所以要在self matching attention之后加GRU,是因为self matching attention会丢失utterance内的顺序信息,所以将attention后的向量与之前的向量进行拼接,然后输入到GRU中,一方面可以进行再一次的encoding,另一方面,也可以把utterance中的无用信息给过滤掉。
response matching
经过matching attention flow之后,我们就已经对utterance进行了很好的encoding。这一层的处理和SMN就很像了,我们利用word level与utterance level 的utterance的表示,来构建word-word similarity matrix($M_1$)与sequence-sequence similarity matrix($M_2$)。
其中,$P_{u_i},P_{r_j}$是matching attention flow的关于utterance与response的输出,并且,$P_{u_i},P_{r_j}\in R^c$。对于$M_1$与$M_2$,分别输入到卷积层中,做二维卷积(是不是二维卷积还值得商榷)得到$M_{1c}$与$M_{2c}$。具体计算如下:
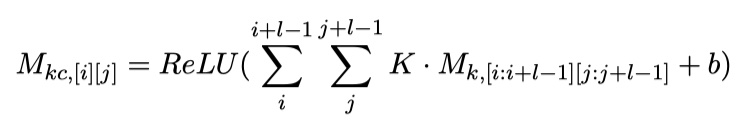
紧接着,接上一个池化,并对其进行flatten与concat。具体如下:
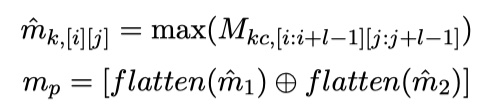
其中,$m_p$表示第p个utterance的表示。
attentive turns aggregation
这一层对所有的信息进行聚合,从而得到最终的结果。上一层的输出表示为:$M=[m_1,m_2,…,m_t]$(这里我认为原始论文写错了,通过CNN之后,得到的$m_p$表示的是第p个utterance in context的向量化表示,所以t个utterance,$M$中应该有t个元素),将其输入到GRU中,得到$H_m=[h_{m_1},h_{m_2},…,h_{m_t}]$,然后采用attention机制,得到attention值:$v_f=L(H_m)$。如下:
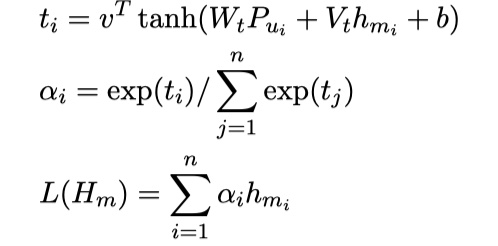
稍稍吐槽一下,这里符号定义得真是乱七八糟,和其他小节的符号冲突了,也不说明,关键是根本不对🤷♂️有点失望。而且每一步输出的维度也不讲清楚,虽然不用每一步都写,但是至少关键的地方,向量的维度要讲清楚,这样也方便读者阅读啊。我以后写论文,一定要把向量的维度说清楚。🧐
最后将结果通过一个softmax,得到最终的score。公式如下:
details
- 数据集:UDC、douban、E-commerce dialogue corpus(本文自己所release的corpus,ECD)
loss function:CE
评价指标:MAP、MRR、Rn@k、P@1
- 优化器:Adam
- utterance的最大数量为10,每一个utterance的最大单词数目为50
- batch size为200,初始学习率为0.001
- 卷积与池化的window size为(3,3)
- GRU的维度为200
- 词向量使用word2vec在训练集训练得到的词向量,维度为200
- 训练5个epcoh收敛
结果
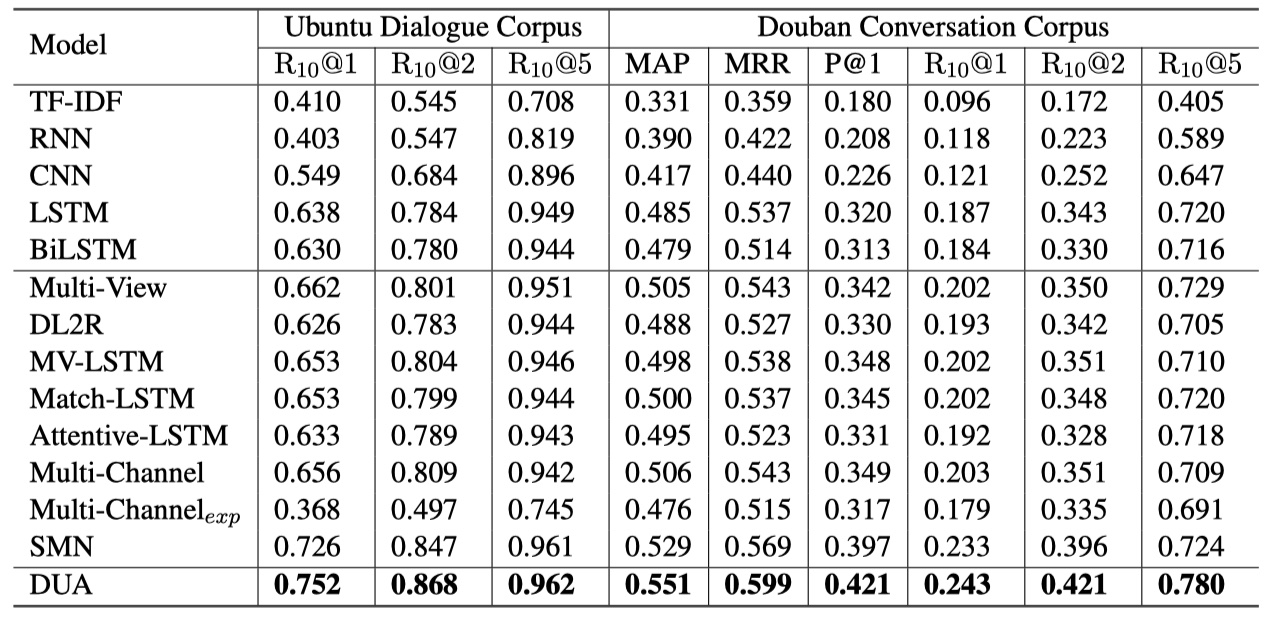
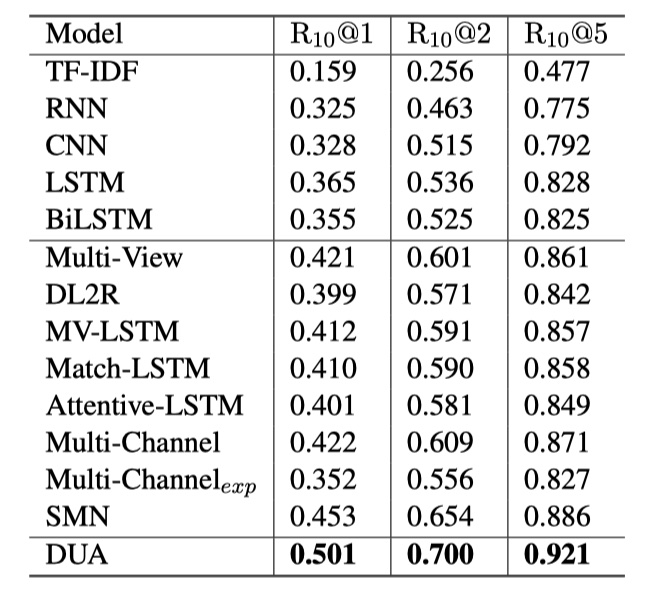
第二张图片是在ECD数据集上的结果。
从结果来看,DUA的效果确实不错~
DUA模型实现
参考文献
Modeling Multi-turn Conversation with Deep Utterance Aggregation

