正式入对话的坑啦🤣对话是目前NLP技术重要的落地场景之一,但是相比于其他的方向,对话目前的应用还不算成熟,也远远没有产生它应有的巨大商业价值,但是随着物联网与5G等的发展,对话的应用前景是非常光明的。此外,既然对话的坑还有很多,这也意味着总需要人去填满这些坑,对NLPer来说,是挑战也是机会。其他的不多说,本篇着重讲讲检索式对话的经典模型DAM。
DAM模型介绍
DAM模型是2018年百度发表的论文,思路非常清晰。由于传统的RNN并行效率低,所以DAM模型中全部使用了self-attention机制;除此之外,在多个粒度上去匹配文本,能够得到更加高层的语义特征,对结果有好处,这个在SSE模型上证明了这一点。下面就具体地来讲解这些DAM模型细节~(ps:这篇论文还总结了检索式对话与生成式对话的区别,非常值得一读)
DAM模型架构
首先给出一些定义:给定训练集:$\cal D=\{c,r,y\}_{z=1}^{N}$,其中,$c=\{u_0,u_1,…,u_{n-1}\}$,$y=\{0,1\}$,c表示context,r表示response,y表示标签,目标是:衡量与c与r之间的匹配度。下面直接给出模型图吧~
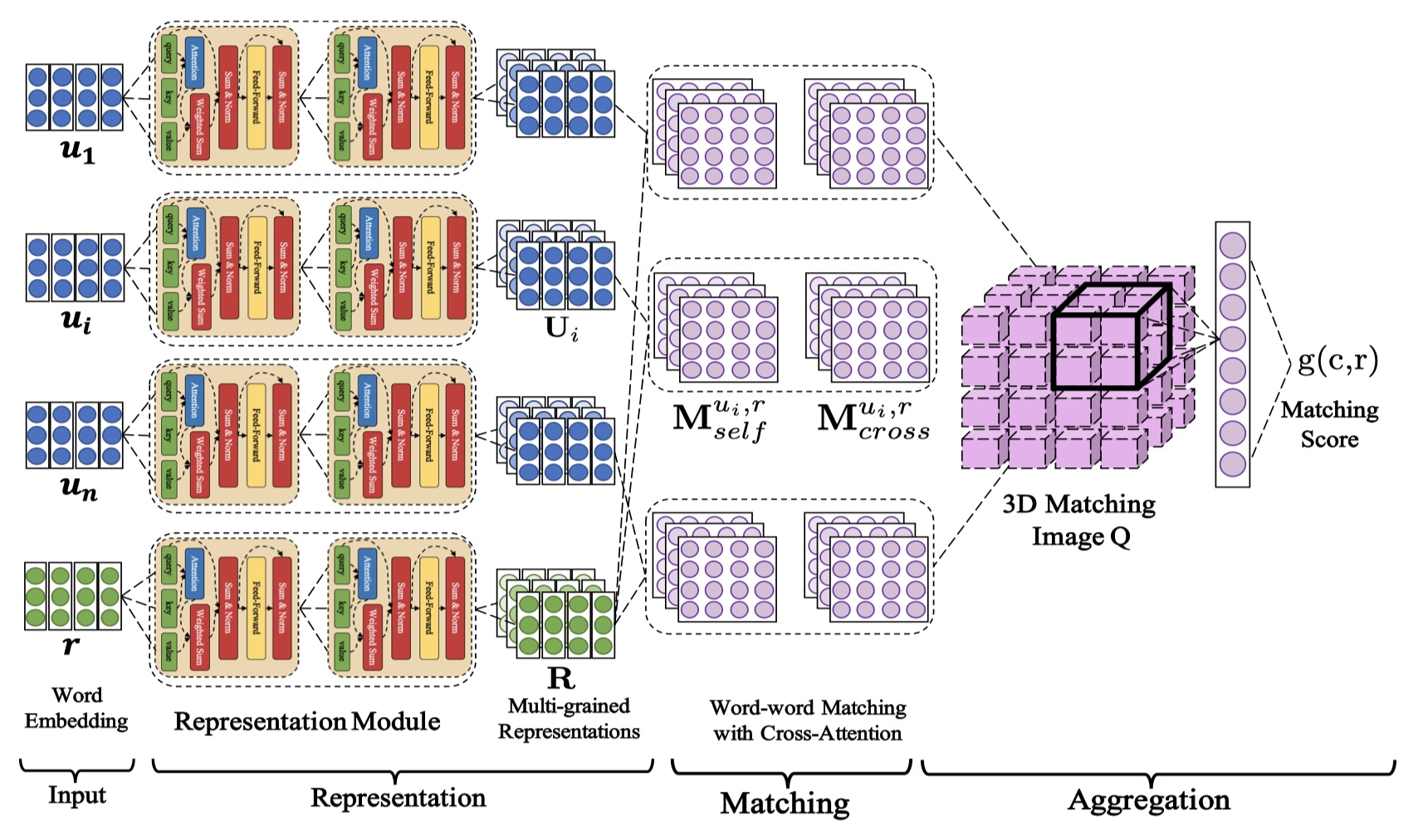
DAM模型大致遵循:representation-matching-aggregation框架,下面一一介绍~
Input layer
c与r共享word embedding,对于第i个utterance in context,它的表示为:$U_{i}^{0}=\{e_{u_i,0}^{0},e_{u_i,1}^{0}…,e_{u_i,n_{u_i}-1}^{0}\}$,对于response,表示为:$R^0=\{e_{r,0}^{0},e_{r,1}^{0},…,e_{r,n_r-1}^{0}\}$。
representation layer and matching layer
这一层主要是叠加多个self attention,从而提取出多个粒度的语义表示。假设有L层,那么每一层的结果都被保存下来,即:$\{U_{i}^{0},U_{i}^{1},…,U_{i}^{L}\}_{i=0}^{n-1}$,$\{R^{0},R^{1},…,R^{L}\}$。计算公式如下:
然后,根据这些结果,来构建self attention match matrix $M_{self}^{u_i,r,l}$与cross attention match matrix $M_{cross}^{u_i,r,l}$。那么,具体怎么来构建呢?如下:
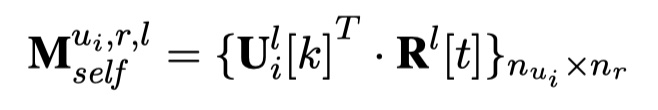
要计算$M_{cross}^{u_i,r,l}$,需要计算cross attention的值,公式如下:
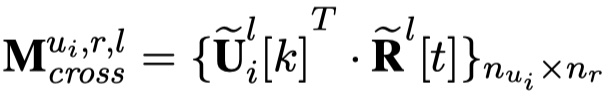
从公式可以看到,两种matrix的构建实际上就是dot product。最终,对于每一个utterance in context的每一层来说,每一个矩阵的维度是:(batch_size,max_length_utterance,max_length_response)。
aggregation layer
aggregation layer的输入维度是:(batch_size,num_utterance,max_length_utterance,max_length_response,2(L+1)),这是一个五维向量。我们记做:$Q=\{\cal Q_{i,k,t}\}_{n\times n_{u_i},r}$。它是self attention与cross attention矩阵concat之后的结果。然后对其使用两层的三维卷积(每一层都接上最大池化),第二个最大池化是全局最大池化,得到的输出维度是:(batch_size,filters),最终将输出送入一层preceptron中,公式如下:
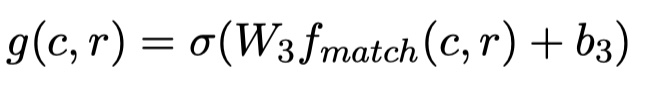
details
数据集:Ubuntu Corpus、Douban Conversation Corpus
评价指标:$R_n@k$,MRR,MAP
- loss function:
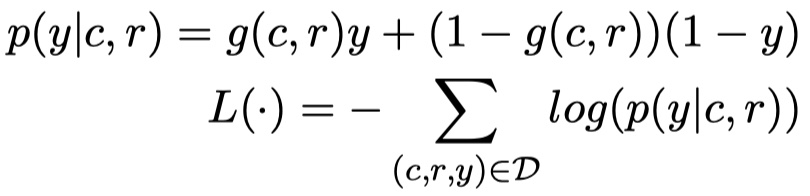
- 每一个context最多有9个utterance,每一个utterance(reponse)最多有50个word
- word embedding使用word2vec得到的词向量,维度是200
- FFN的维度为200,self attention层最大是7层,最后是5层最好
- 第一个卷积层有32个[3,3,3]的filters,stride为[1,1,1],最大池化大小为[3,3,3],stride为[3,3,3];第二个卷积层有16个[3,3,3]filters,stride为[1,1,1],最大池化大小为[3,3,3],stride为[3,3,3]
- batch szie 为256
结果
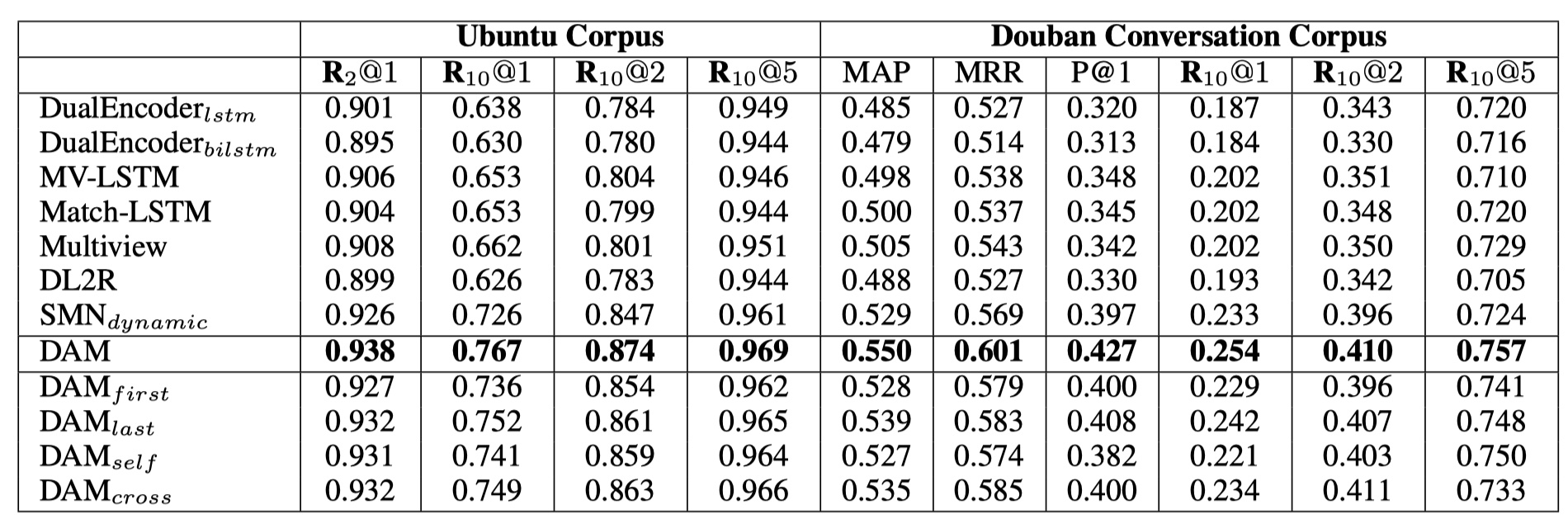
从结果来看,DAM模型效果还是不错的~
DAM模型实现
参考文献
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network

