正式入对话的坑啦🤣对话是目前NLP技术重要的落地场景之一,但是相比于其他的方向,对话目前的应用还不算成熟,也远远没有产生它应有的巨大商业价值,但是随着物联网与5G等的发展,对话的应用前景是非常光明的。此外,既然对话的坑还有很多,这也意味着总需要人去填满这些坑,对NLPer来说,是挑战也是机会。其他的不多说,本篇着重讲讲检索式对话的经典模型Multi-view。
Multi-view模型介绍
首先不得不说,这是一片非常好的文章,非常适合用来做对话入门🤩首先来说说为什么要有Multi-view模型。最先要说明的是,这篇文章是于2016年发表的,这时候匹配是以基于表示的模型为主,而基于交互的模型还为兴起。所以,在response selection任务中,大部分模型都是将context与response视为word的集合,然后对其进行embedding,论文中称其为word sequence model。这样的方法的缺点在于:其忽略了utterances之间的关系。譬如说:一个utterance可以是对上一个utterance的肯定、否定,或者是开启一个新的topic,但是word sequence model无法捕捉到这样的信息。再说明白点,word sequence model无法很好地处理多轮对话。所以,Multi-view模型通过在utterance level进行建模,并与word level进行combine,从而大幅提升在respone selection任务中的表现。
模型结构
首先介绍传统的word sequence model处理多轮对话的思路:将多轮对话首尾连接成一条长长的文本,从而输送到网络中。就是下面这个样子:
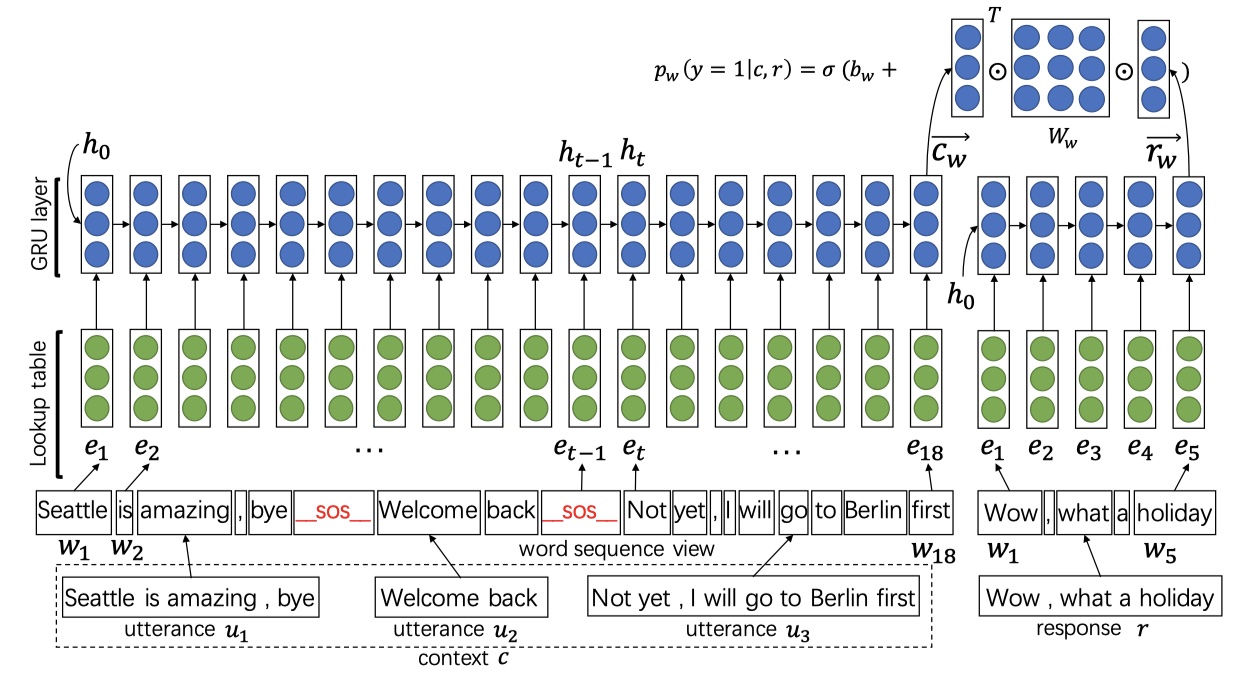
其中,_sos_是两个utterance之间的连接符。再将句子使用GRU进行encoder之后,我们使用GRU的最后一个hidden state来计算confidence,即匹配度。公式如下:
其中,$c,r$表示context1与response,$\sigma$是sigmoid函数。但是仅仅在word level进行建模是不够的,Multi-view模型更是在utterance level进进行建模,从而期望得到更高层次的语义表示。如下
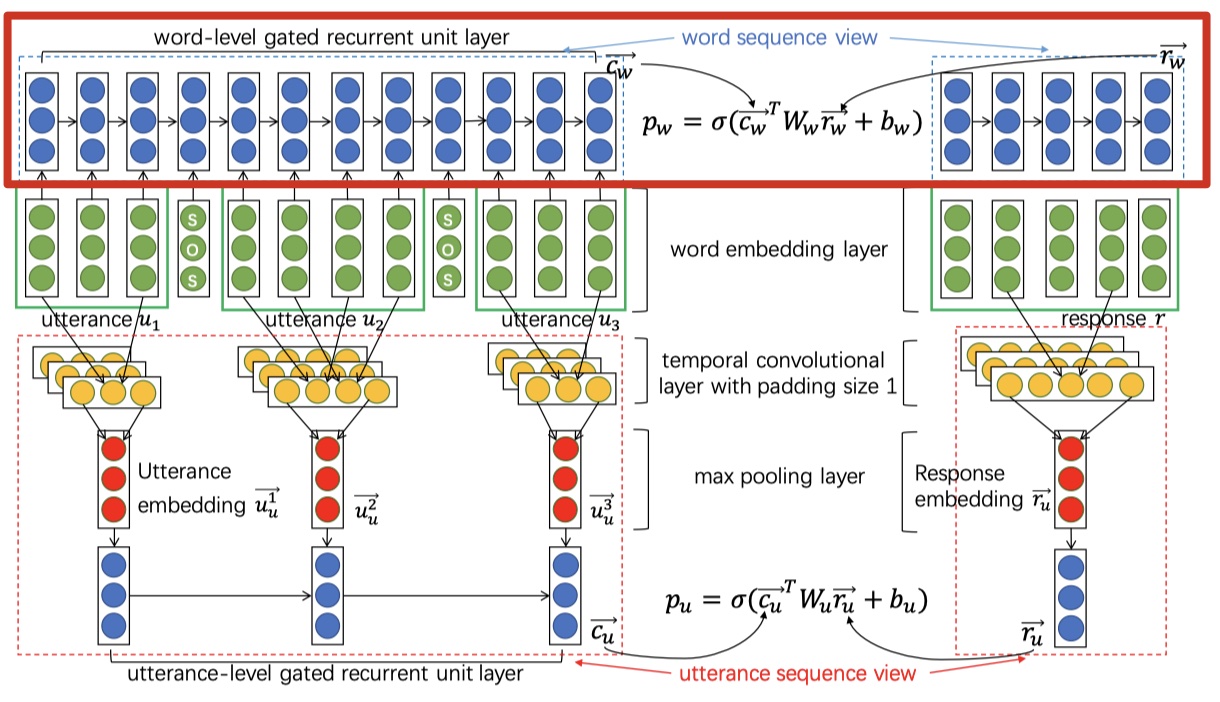
我在图上标记了一下,因为这个图要分成两部分来看(一开始我看的时候,有点模糊😷)。下面依次解析~
- 红框部分是word sequence model,这个没有可说的,与上面说的一样;红框下面的是utterance sequence model部分。
- 绿色部分是word embedding部分,可以使用word2vec、Glove或者是随机初始化。注意:word level与utterance level是共用word embedding的。
- 黄色部分是一维卷积层,与textCNN中的卷积一样。注意,这里使用的是等长卷积,并且每一个utterance产生一个输出,但是kernel部分是共享的。
- 红色部分是全局池化层,提取出context与response中的核心意思,这样就把对轮对话变成utterance embedding sequence了。
- 蓝色部分是GRU层,并利用最后一个hidden state来计算置信度。
注意:word level的GRU是context与reponse共享的;utterance level的GRU是context与response共享的,但是两个level之间的GRU不共享参数。
损失函数
Multi-view的损失函数是:likehood loss、disagreement loss与 regularization loss。
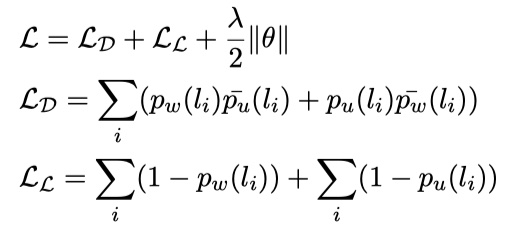
其中,$p_w(l_i)、p_u(l_i)$分别表示word level与utterance level的是第$i$个label的概率,label取$\{0,1\}$,$\hat p_w(l_i)=1-p_w(l_i)、\hat p_u(l_i)=1-p_u(l_i)$,$\cal L_D、\cal L_L$分别表示disagreement loss与likehood loss。likehood loss很好理解,不过关于disagreement loss,就不是很理解为什么要这么定义了,可能需要再看看其他论文。
在预测的时候,我们对每一个response的置信度的公式如下:
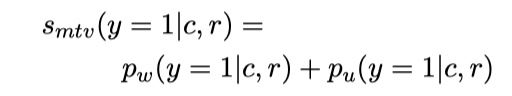
最后,我们从candidate中选出置信度最大的response,即可。
details
数据集:UDC(ubuntu corpus)
评价指标:1 in m Recall@k,在m个候选回复中,合理回复出现在前k个就算成功。1 in 2 Recall@1,就是二分类中的recall。
- training details:采用Glove词向量,GRU的hidden units为200,kernel数目为200,初始学习率为0.01,batch size为32,4-5个epochs就收敛了。
结果
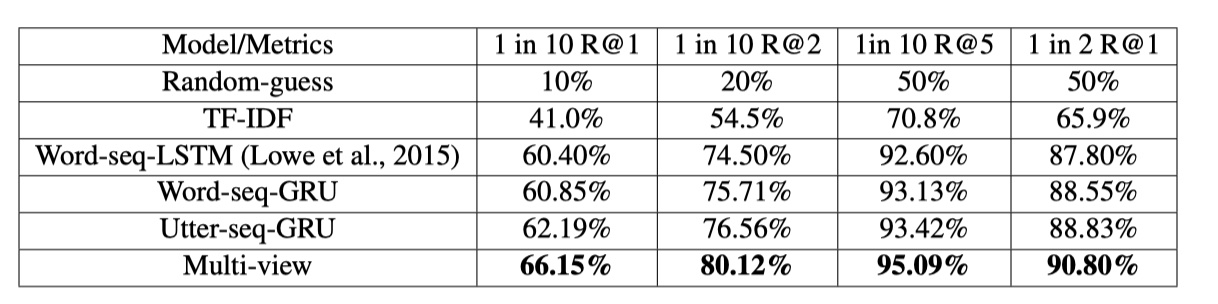
可以看到,结果确实非常好~论文中还去探索了_sos_tag的作用,也探索了不同数目的utterance对结果的影响,感兴趣的童鞋可以看原始论文,个人认为这篇论文写的非常好,非常值得一读~
Multi-view模型实现
参考文献
Multi-view Response Selection for Human-Computer Conversation

