正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的BIMPM模型,并采用tensorflow2实现。
BIMPM模型的介绍
BIMPM模型来源于2017年的《Bilateral Multi-Perspective Matching for Natural Language Sentences》论文。这篇文章总结了Siamese架构与matching-aggregate架构的优缺点,非常值得一读,有时间的童鞋一定要去读读原始论文🤩
BIMPM模型提出的原因
在文本匹配模型中,大致可以分为两大类:基于表示的文本匹配模型,即Siamese架构,以及基于交互的文本匹配模型,即matching-aggregate架构(有时候也称作compare-aggregate架构)。两种结构的优缺点如下:
- Siamese架构的优点在于两个句子可以共享参数,所以模型容量比较小,也容易训练;但是其缺点也很明显,由于在encoder部分没有明显的交互,所以会导致失去某些重要的信息,即没法捕获到更加丰富的语义特征。
- matching-aggregate架构的优点可以及早地捕获更为丰富的交互特征,因此效果通常来说会更好一些。但是其缺点在于:一方面,很多模型只考虑了单个细粒度的匹配,比如word by word,而没有考虑其他细粒度的匹配;另一方面,匹配往往是单向的,即只有P对Q的匹配,或者是Q对P的匹配。
知道了两种架构的优缺点后,作者提出了BIMPM模型。该模型本质上还是属于matching-aggregate架构,但是与其他模型不同的地方在于:其考虑了两个方向的匹配,即P对Q与Q对P。这样的话,就可以得到更为丰富的语义特征。事实证明,其确实取得了比较好的效果。
BIMPM模型的架构
首先给出相关定义。假设sample的形式为三元组:$(P,Q,y)$,其中$P=\{p_1,p_2,p_3,…,p_M\},Q=\{q_1,q_2,q_3,…,q_N\}$。其中,每一个token的维度均是d维的;$y$是label。从这里可以看出,BIMPM模型属于pointwise的学习方式。
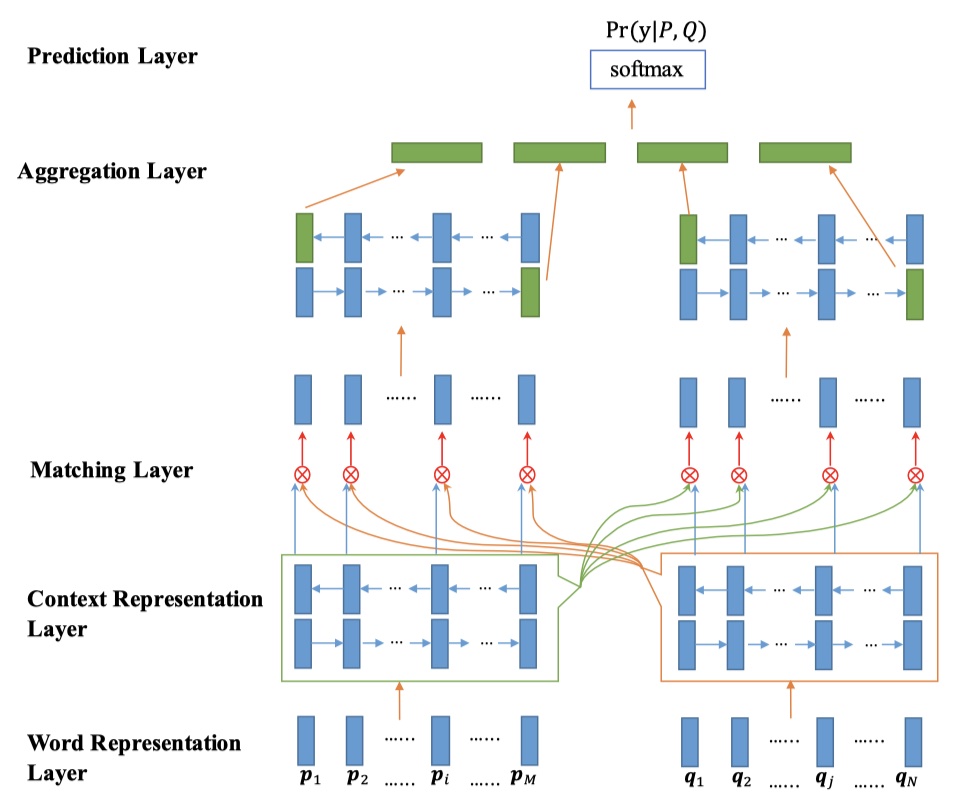
上图就是BIMPM模型的整体架构。可以看到,BIMPM模型分为五层,下面一一介绍。
word representation layer
这一层包含两个部分:一部分是固定的词向量,比如使用Google的300维的word2vec词向量或者Glove词向量;另一部分是将每一个单词的每一个输入到LSTM网络中,得到的词向量,这一层最终的输出是将这两部分的词向量进行concat之后的结果。
context representation layer
这一层是对P和Q进行进一步的encoding,将上下文信息融入到每一个time step。具体来说,是使用一层BILSTM。注意:P与Q使用同样的BILSTM,即共享参数。
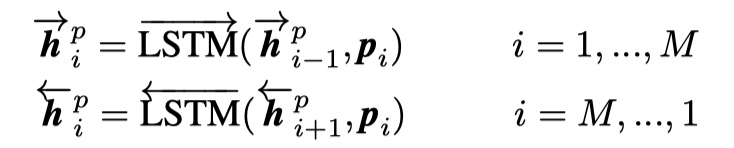
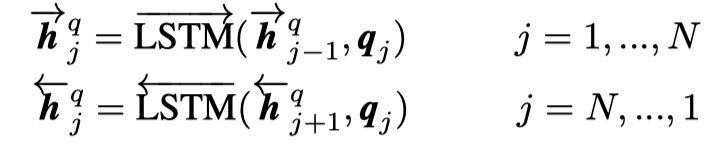
matching layer
这一部分是BIMPM模型真正创新的地方。它采用了双向的matching方法,即:比较P的每一个timestep的向量与Q的所有timestep向量,比较Q的每一个timestep的向量与P的所有timestep向量。在论文中,作者设计了一种multi-perspective的方法。整个multi-perspective方法包含两步:第一步:给出cosine matching function的定义;第二步,在给出的函数的基础上,使用四种匹配策略(full-matching、Maxpooling-matching、attentive-matching、max-attentive-matching),从而得到最终的输出。
step1:首先要明白给出的cosine matching function的定义,如下:
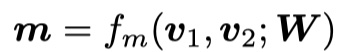
其中,$v_1,v_2$是两个向量,假设其维度是$d$维;$W$是参数,其维度是$R^{l\times d}$,$l$是perspective的数量;得到的输出$m=\{m_1,m_2,m_3,…,m_l\},m\in R^l$。具体来说,$ m_k=cosine(W_kv_1,W_kv_2) $。
step2:在第一步的基础上,给出了四种匹配策略。下面演示的是P对Q的matching,即P的每一个timestep对Q进行matching。
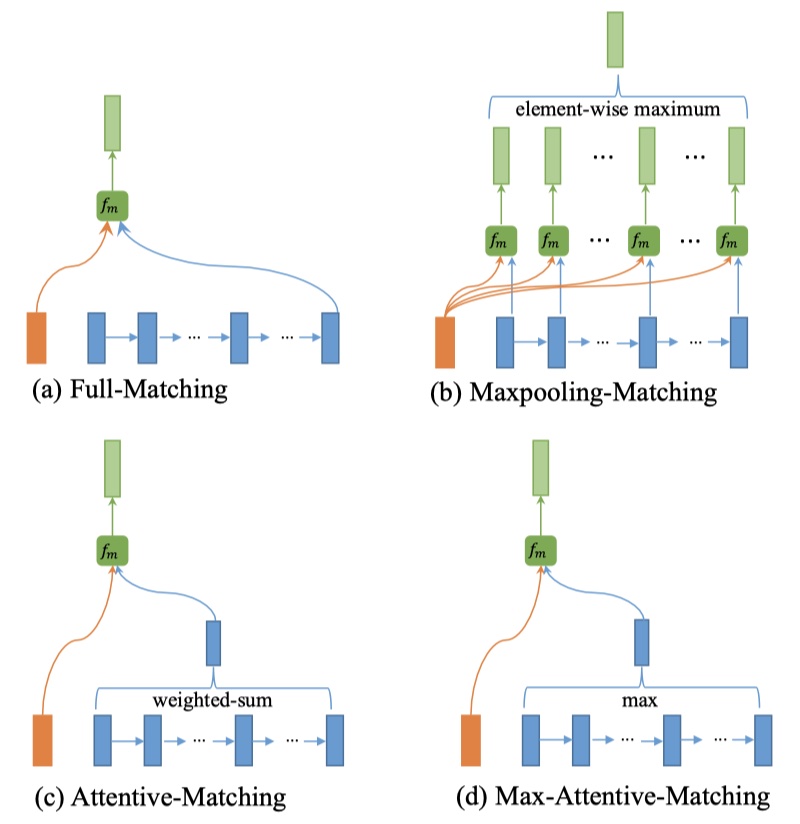
- full matching:对于P的一个timestep的向量,只与Q的最后一个状态相比较(前向的或者后向的)。对应上图的a,具体公式如下:
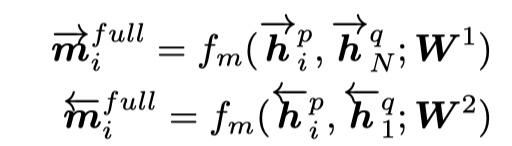
- maxpooling matching:对于P的一个timestep的向量,分别与Q的每一个timestep的向量进行比较,最后选择结果最大的输出。对应于上图的b,具体公式如下:
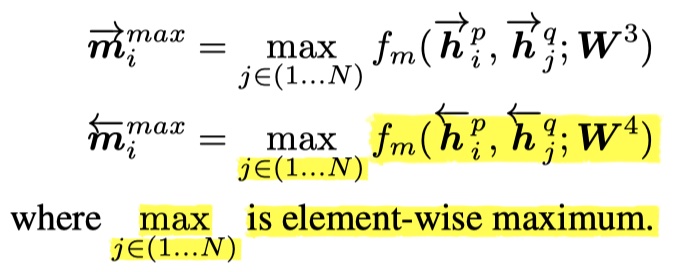
- attentive matching:对于P的每一个timestep的向量,分别与Q的每一个timestep进行余弦相似度的计算,最后得到加权后的向量。对应于上图的c,具体公式如下:
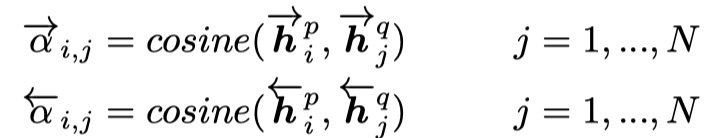
得到余弦相似度,然后得到进行加权,如下:
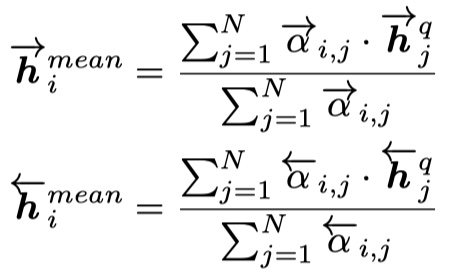
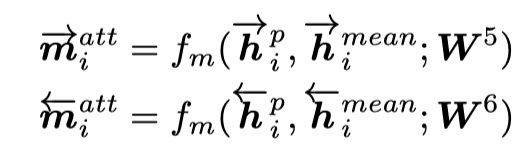
- max-attentive matching:与attentive matching不同·的地方在于,注意力向量并不是加权得到的,而是从中选取最大的作为注意力向量,启宇的与attentive matching一样。
最后,这一层的输出是上面四种策略的concat之后的结果。注意,因为是双向的BLSTM,所以一个句子最后聚合的是8个向量!!!
aggregate layer
这一层主要是去聚合两个句子。具体来说,使用的是一个BILSTM,我们取前向的LSTM与后向的LSTM的最后一个状态,由于是两个句子,所以最后是concat4个向量。
prediction layer
这一层就是要得到最后的分类结果啦。具体来说,就是使用两层的MLP,最后使用softmax,得到最终的输出。
上述就是BIMPM模型的全部内容啦🎉
稍微啰嗦一下吧,目前基本的文本匹配模型就看完了,总的来说,还是比较简单,实现起来也不难。要说难的地方,就是pairwise的训练方式与listwise的训练方式了吧,这个对于数据的处理是需要下一点功夫的,最好去借鉴一下别人的代码是怎么写的。pointwise是比较简单的,这个不用说什么。接下来的话,如果还需要接触文本匹配的模型的话,那就是MRC了吧。说实话,这个单独搞真不好搞,但是MRC毕竟是目前研究的热点方向,经典的BIDAF、R-net等模型还是需要去看的,VQA也需要去接触一下。不过,主线还是要放在检索式对话这块,先把检索式对话看完,然后再去熟悉生成式对话。毕竟生成式任务真的不好弄,而且还是对话这块,还是需要有人带。
BIMPM模型的实现
参考文献
Bilateral Multi-Perspective Matching for Natural Language Sentences

