正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的InferSent模型,并采用tensorflow2实现。
InferSent模型介绍
InferSent模型来源于2018年Facebook发表的《Supervised Learning of Universal Sentence Representations from Natural Language Inference Data》论文。这是一篇非常有影响力的工作。首先谈谈InferSent提出的原因吧:目前word embedding已经被广泛应用了,但是大多数时候,我们想要得到的是sentence embedding,即句子的向量化表示(甚至是段落、文章的向量化表示),只是单纯对所有word embedding相加取平均,无法提取到有意义并且丰富的语义信息,所以怎么才能提取出有意义并且丰富的sentence embedding,并且提取的方法要非常的generalize,能在各种task中得到sentence embedding,成为了一个亟待解决的问题。从结构上来讲,InferSent是一个基于表示的文本匹配模型,但是它的真正目的是提出一种有监督的sentence embedding的学习方法,从而完成迁移学习。废话不多说,直接上图吧~
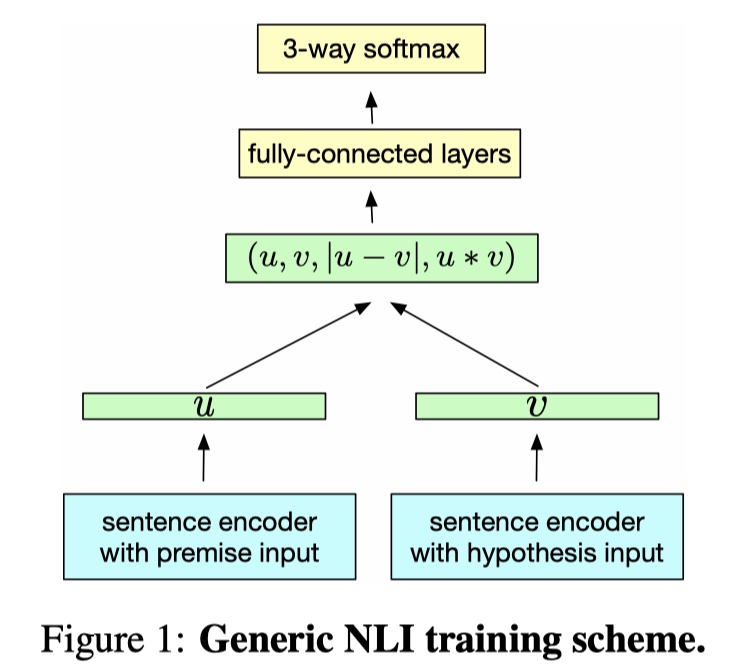
由于InferSent仍然是一种基于表示的文本匹配模型,所以整个模型架构分为两个部分,下面一一介绍~
sentence encoder
这一步就是对premise与hypothesis两个句子进行encoder。作者尝试很多的方法,最后发现使用BILSTM+maxpooling的方式效果最好。
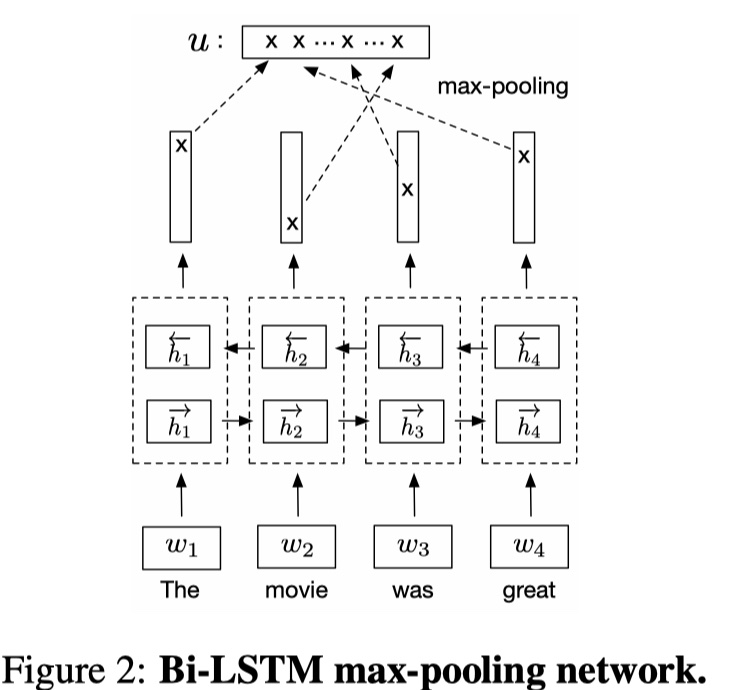
公式如下:
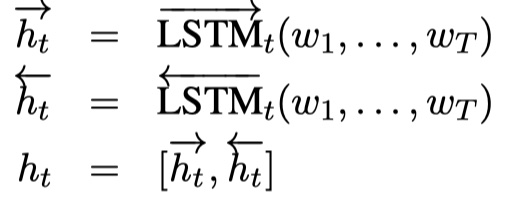
其中,$w_i$表示premise或者是hypothesis的第$i$个位置的word embedding。然后再对$h$进行max-pooling,得到premise与hypothesis的sentence embedding:$u,v$,其中$u,v\in R^{2d_m}$,$d_m$是前向LSTM或者后向LSTM输出的维度。具体可以参见我的关于SSE的文章SSE模型
classifier
这一步就是将得到的$u,v$以及它们之间element-wise的difference与product进行concat,得到向量$m$。即:
然后将$m$输入到dense层,激活函数为relu,最后送入softmax层中,得到最终的结果。
training details:BILSTM的输出维度为4096,使用Adam。
Noooooooote:像word embedding,我们可以存储下来,等到要用的时候,直接查询embedding lookup table即可,但是sentence embedding不行,那么sentence embedding的本质是什么呢?其实没有所谓的sentence embedding算法,因为我们没有用来评价得到的sentence embedding的方法,我们只有将sentence embedding嵌入到下游任务中,通过下游任务的好坏,来评价得到的sentence embedding的质量。所以,我们追求的通用的sentence embedding,实际上我们是要得到一个网络架构,或者称作encoder,在InferSent中,指的就是sentence encoder模块。我们输入文本序列,能够通过encoder,得到文本序列的向量化表示。这才是sentence embedding的本质,或者说其与word embedding的不同之处链接。🥰
简单唠叨一下sentence embedding的发展
目前来说,得到sentence embedding的方法分为监督学习与无监督学习两大类。一般来说,使用无监督学习就可以得到比较好的sentence embedding,代表性模型有SkipThought以及FastSent。监督学习的代表性模型就是InferSent,所以InferSent真的是一项非常有影响力的工作。而目前,sentence embedding的热点是多任务学习,即在一次训练中,组合不同的训练目标。代表性模型有:Universal Sentence Encoder(Google)。大致就是这样,之后有空再更新一篇关于sentence embedding的文章吧🥰~
InferSent模型实现
参考文献
Supervised Learning of Universal Sentence Representations from Natural Language Inference Data

