正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的HCAN模型,并采用tensorflow2实现。
HCAN模型介绍
HCAN模型来源于2019年的《Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling》论文。整体来说不算太难。
HCAN模型提出的原因
在NLP中,存在着两大任务:relevance matching(RM)与semantic matching(SM)。所谓的RM常见于信息检索中,其目的在于根据query与documents的relevance,对documents进行排序,其核心是关键字匹配;而SM,其目的在于计算两个句子的相似度或者匹配度,其核心是句子语义上的匹配。从这个定义中,可以看出RM本质上也是语义匹配,所以RM与SM有一定的相似性。那么问题来了:能不能提出一种模型,在RM与SM上都能取得非常好的效果呢?这就是HCAN模型提出的原因。
HCAN模型架构
整个架构比较简单:word embedding层、hybrid encoder层、relevance matching与semantic matching层、最后的分类层。直接放图吧~
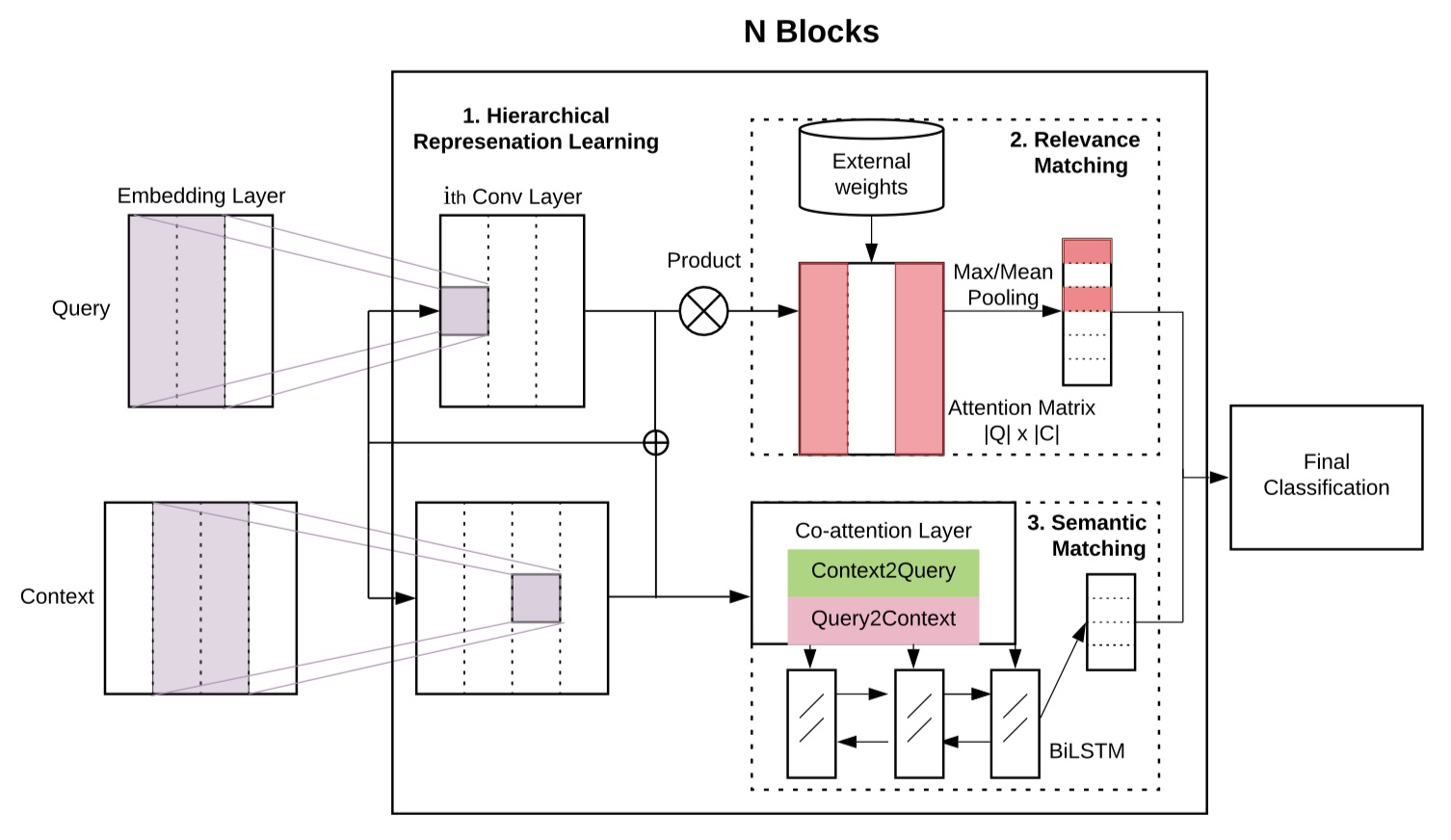
Embedding layer
输入句子对,记作$(q,c)$,在QA任务中,其表示question与answer,在信息检索中,其表示query与document。其中,$q、c$均表示句子的token的集合,它们的embedding记作:$\{w_1^q,w_2^q,w_3^q,…,w_n^q\}$与$\{w_1^c,w_2^c,w_3^c,…,w_m^c\}$,embeddding的维度为$L$,$n、m$是句子的长度,所以,$q\in R^{n\times L}、c\in R^{m\times L}$。
Hybrid Encoders
在得到句子的embedding后,为了进一步得到更加丰富的表示,在HCAN中,使用了三种不同类型的encoders:deep、wide、contextual。
Deep Encoder:所谓的Deep encoder,就是叠加多个卷积层,从而得到更加丰富的语义表示,在论文中,称作phrase-level representation,第$h$个卷积层的输出记作:$U^h$。这个和DPCNN中的region embedding有点相似,不熟悉DPCNN的,可以移步我的文章:DPCNN
注意,q与c是共享这些参数的!
Wide encoder:wide encoder则是换了一种思路,并联多个卷积层,也就是“变宽”。给定$N$个卷积层,假设第一个卷积层的窗口大小为k,那么N个卷积层的窗口大小依次是:$[k,k+1,k+2,k+3,..,k+N-1]$.
Contextual encoder:contextual encoder不使用卷积层,转而使用BILSTM来提取更为丰富的语义特征。给定$N$个BILSTM层,第$h$个BILSTM层的输出是:$U^h$。
三种encoder的比较
- deep与wide由于使用CNN,所以并行计算效率比contextual要高,训练要快;此外,使用CNN的话,我们可以控制窗口大小,能够得到不同phrase level的语义表示。同时,这样对于relevance matching也是非常有用的。
- deep的参数数量更少,因为deep中所有层的filter是一样的,所以可以实现参数共享。
Relevance Matching
注意:下面所示的维度均没有带上batch_size!
通过hybrid encoders之后,我们可以得到q与c的深层次的向量化表示:$ U_q\in R^{n\times F}、U_c\in R^{m\times F}$。在此基础上,我们首先要去得到relevance matching。采用的方式就是dot。公式如下:
然后,在此基础上,在context列上使用softmax,公式如下:
这一步的意义在于让得到的similarity score的范围处于[0,1],此外,softmax也能够让score之间的区分度变大。
然后再对其使用最大池化和平均池化(注意,是全局池化,也就是说,池化后,会减少一个维度),论文中指出,平均池化要好一点。公式如下:
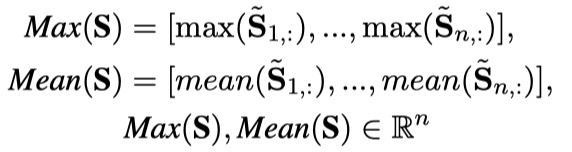
接下来,作者还引入了IDF来作为不同的query term与phrase的权重,衡量其重要性程度。
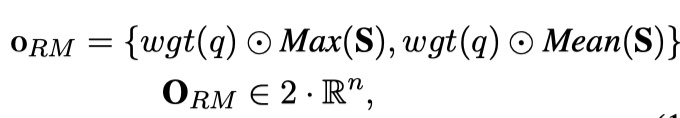
这样加权的方法也可以减小得分比较大的token(譬如停用词)的影响。
Semantic Matching
Semantic Matching的输出仍然采用hybird encoders的输出,即q与c的深层次的向量化表示:$U_q\in R^{n\times F}、U_c\in R^{m\times F}$。在此基础上,使用co-attention机制,不熟悉co-attention机制的童鞋,可以参看论文《BIDIRECTIONAL ATTENTION F LOW FOR MACHINE COMPREHENSION》,这是在MRC任务中大名鼎鼎的BIDAF模型,非常值得一看🤩。使用co-attention机制的公式如下:
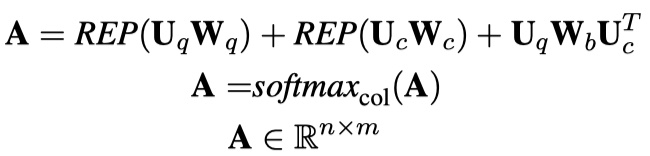
其中,REP表示将input转化为n✖️m的矩阵,$W_q,W_c\in R^{F},W_b\in R^{F\times F}$。
在两个方向上使用co-attention机制:query-to-context和context-to-query。
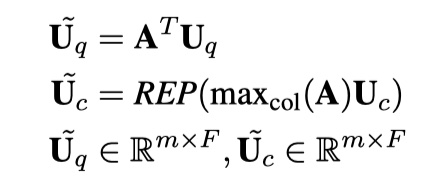
然后对得到的向量进行concat,再使用BILSTM来进行编码,得到输出。公式如下:
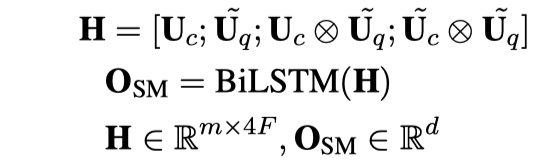
注意,我们只使用BILSTM的最后一个输出。
Final classification
对relevance matching与semantic matching得到的输出进行concat,然后使用两层的MLP,从而得到最终的输出。
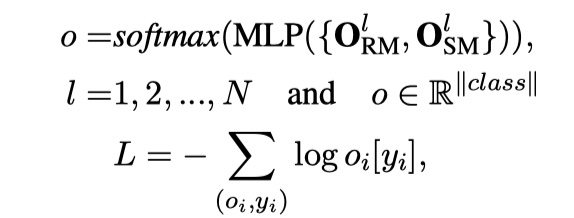
HCAN在answer selection(使用TrecQA数据集、评价指标MAP与MRR)、paraphrase identification(使用TwitterURL数据集、评价指标macro-F1)、semantic textual similarity(使用Quora数据集,评价指标准确率)、Tweet Search(TREC Microblog数据集、评价指标P@30)。结果如下:
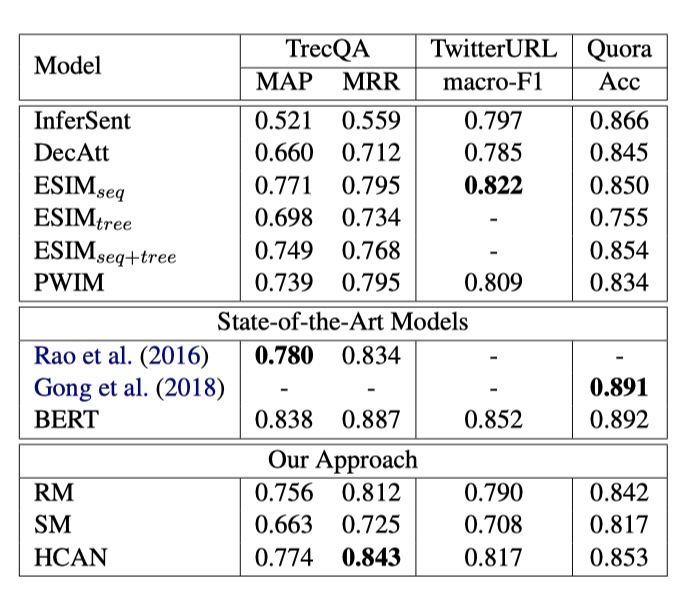
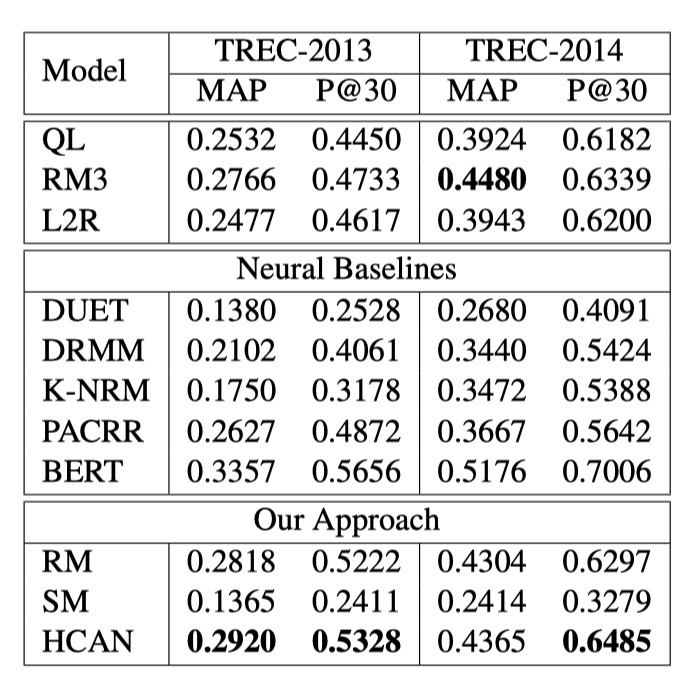
从结果可以看到,HCAN模型吊打了DecAtt、ESIM、InferSent等一众模型,但是仍然打不过BERT。所以,要在文本匹配任务重取得更好的结果,目前还是离不开预训练模型。
HCAN模型实现
参考文献
Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling

