正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的DSSM/CDSSM模型,并采用tensorflow2实现。
DSSM模型介绍
DSSM模型来源于2013年《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》论文。由于是13年的论文,所以其实整体思想还是很简单的,直接放图吧~
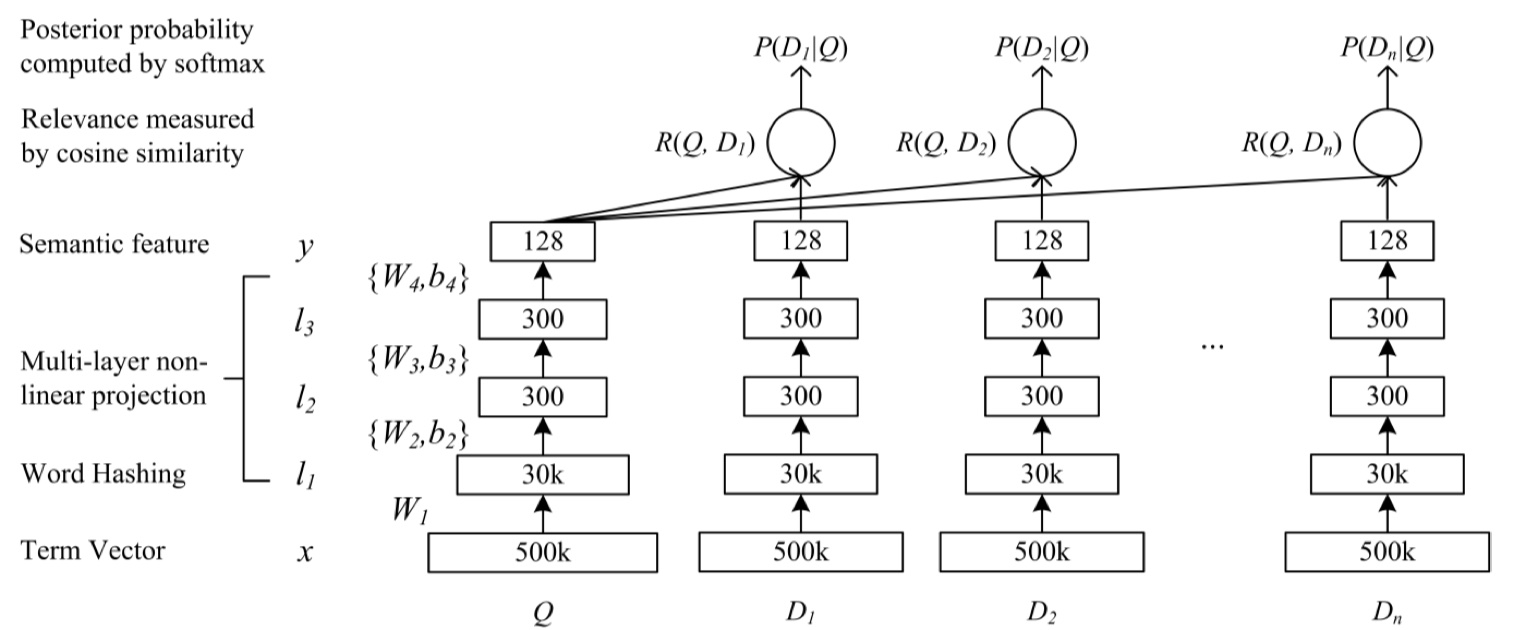
$x$表示term vector, 表示输出向量,$l_i,i=1,…,N$ 表示隐藏层, $W_i$ 表示第$i$层的参数矩阵,$b_i$表示 第$i$个偏置项。
其中,使用 $tanh$ 作为输出层和隐藏层的激活函数。在检索中,使用$Q$表示query,$D$表示doc,,那么它们之间的相关度可以使用余弦相似度来衡量。
在·word2vec还没有兴起之前,一般都是采用BOW构建词汇表,然后使用one-hot进行编码,但是时间上,词汇表会非常大,在DSSM中,使用word hashing的方法,作为模型的第一层。和word2vec比较像,都是将高维稀疏向量转换为低维稠密向量。
Word Hashing是paper非常重要的一个 trick,以英文单词来说,比如 good,他可以写成 #good#,然后按tri-grams来进行分解为 #go goo ood od#,再将这个tri-grams灌入到 bag-of-word中,这种方式可以非常有效的解决 vocabulary太大的问题(因为在真实的web search中vocabulary就是异常的大),另外也不会出现 oov问题,因此英文单词才26个,3个字母的组合都是有限的,很容易枚举光。
在得到余弦相似度之后,再使用softmax,通过softmax 函数可以把query 与样本 doc 的语义相似性转化为一个后验概率:
其中$\gamma$是一个softmax函数的平滑因子, 表示被排序的候选文档集合,在实际中,对于正样本,每一个(query, 点击doc)对,使用 $(Q,D^+)$表示;对于负样本,随机选择4个曝光但未点击的doc,用
来表示。在训练阶段,通过极大似然估计来最小化损失函数:
其中$\Lambda$表示神经网络的参数。模型通过随机梯度下降(SGD)来进行优化,最终可以得到各网络层的参数 $W_i,b_i$。
DSSM模型的缺点在于:使用word hashing会造成冲突,因为不同的单词有可能产生同样的n-gram;采用词袋模型,损失了上下文结构信息。
CDSSM模型介绍
CDSSM是DSSM的改进,在DSSM中,由于采用词袋模型来表示输入的query与document,完全丧失了句子本身应有的上下文结构信息,而CDSSM采用词n-gram与卷积池化操作,捕获上下文关系。模型图如下:👇
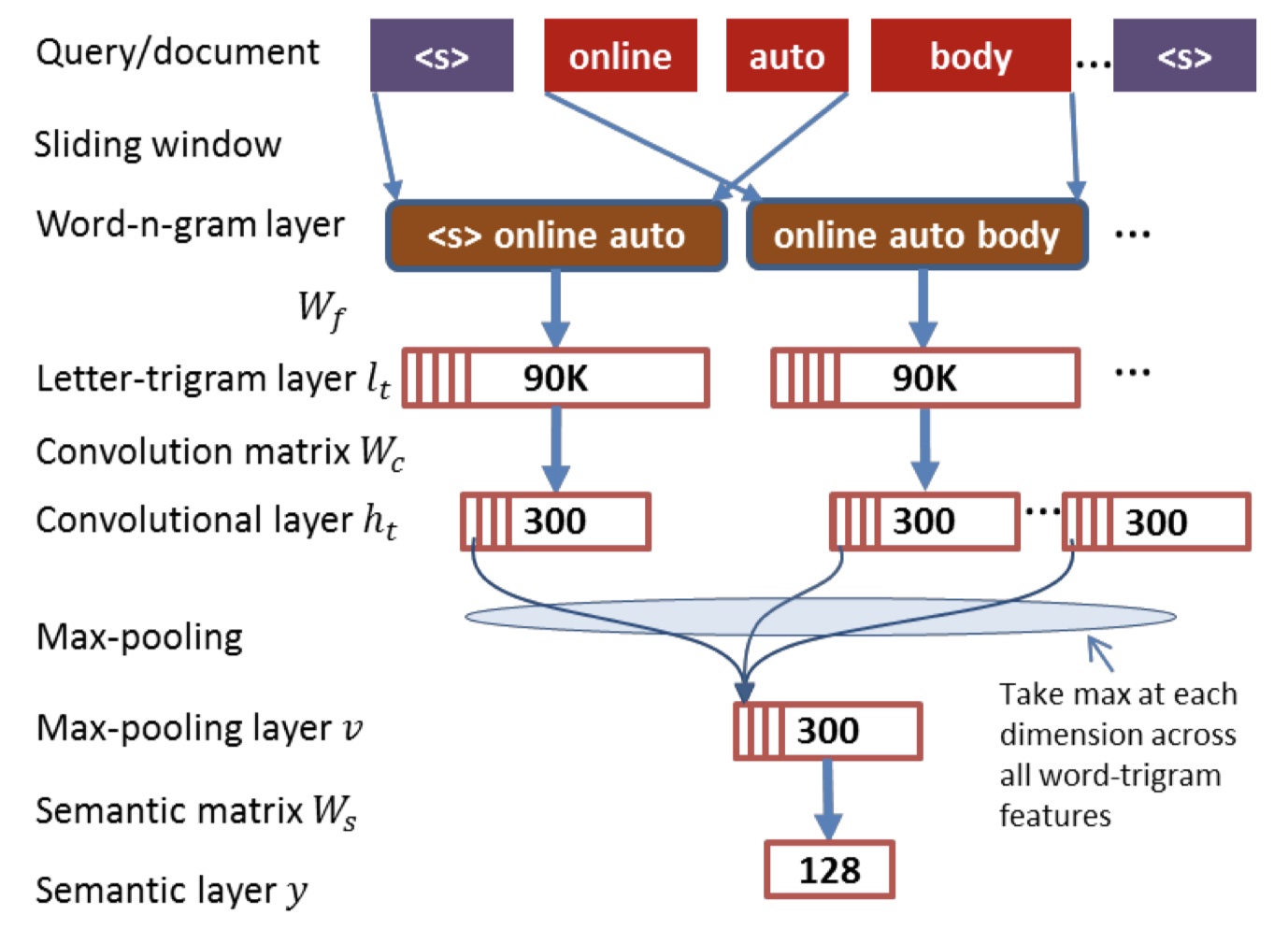
Query/document:输入的query与doc句子,并且使用了<s>进行填充,保证进行卷积的时候,前后都有词。
Sliding window 是定义滑动窗口对输入的句子做n-gram,来获取word-n-gram,文章用的tri-gram。
word-n-gram layer 是经过滑窗处理后的word-n-gram 数据。
Letter-trigram layer 是对word-n-gram 按原始dssm说的那个把单词用n-gram进行切割的方式进行处理,不过在进行词袋模型统计的时候统计的是word-n-gram了,不再是整个句子。
卷积层:一维卷积。
max-pooling :池化层也是经常和卷积一起配合使用的操作了,这里之所以选择max-pooling是因为,语义匹配的目的是为了找到query和doc之间的相似度,那么就需要去找到两者相似的点,max-pooling则可以找到整个特征图中最重要的点,而avg-pooling则容易把重要的信息平均掉。
之后加一层全连接,损失函数什么的都与DSSM一样。
CDSSM模型实现
参考文献
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval

