正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的SSE模型,并采用tensorflow2实现。
SSE模型介绍
SSE模型来源于2017年《Shortcut-Stacked Sentence Encoders for Multi-Domain Inference》论文,用于解决NLI问题。SSE模型主要是基于InferSent模型,然后借鉴了resNet的残差连接的思想,从而在SNLI上取得了SOTA。直接放图吧~
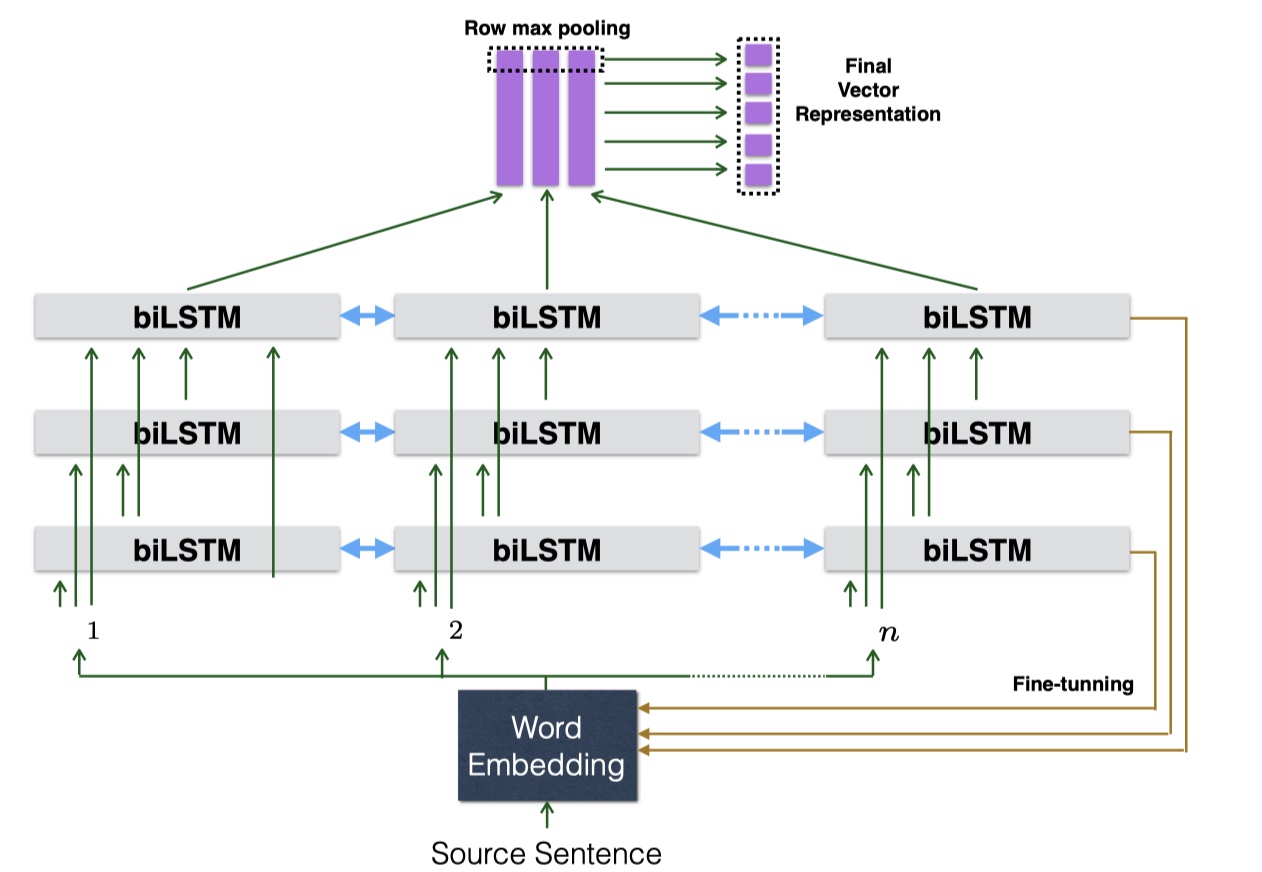
SSE模型是基于表示的文本匹配模型,所以大体上分为两步:sentence encoder、entailment classifier。下面一一介绍~
sentence encoder
这一步,SSE模型主要是通过stack多层的biLSTM,从而得到更加深层语义信息。这其实没有什么新奇的,在SiamLSTM、ESIM、InferSent上都用到了,但是不同的在于:第 $i$ 个blLSTM层的输入是:前 $i-1$ 个biLSTM层的输出与最初的word embedding的concat。这也是SSE模型的改进的地方。公式如下:
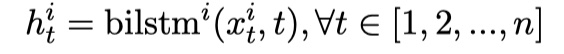
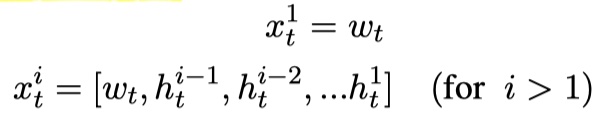
其中,$h_t^i$ 表示第$i$个biLSTM层的第$t$个位置的输出;$x_t^i$表示第$i$个biLSTM层的第$t$时刻的输入;$w_t$是最初token的word embedding。假设有m层,那么最后一层的输出如下:
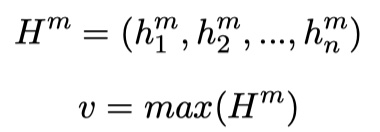
其中,$H^m$表示第m层的输出,长度与原语句长度一致,也就是说,stack这么多层的biLSTM,就是为了能够提取出更加深层的语义信息;$v$表示对$H^m$进行maxpooling之后得到的结果。在这里需要理清一下各个向量之间的维度关系:$h_i^m\in R^{2d_m},H^m\in R^{2d_m\times n},v\in R^{2d_m}$。
Noooooote:premise $p$ 与hypothesis $h$ 都是经过上述的网络结构,得到结果向量 $v_p$与$v_h$,也就是说共享参数!这个在《APPLYING DEEP LEARNING TO ANSWER SELECTION: A STUDY AND AN OPEN TASK》论文里有讨论过!
entailment classifier
通过sentence encoder,我们得到两个句子的向量化表示$v_p$与$v_h$,首先要对其进行concat,得到matching vector $m$,公式如下:
然后将concat之后$m$输入一个dense层,使用relu进行激活,然后输入到softmax,得到最终的结果。
training details:数据集使用Multi-SNLI;优化器为Adam;batch size为32;初始学习率为0.0002,每两个epoch衰减一半;dense层的输出维度为1600,对dense层输出的结果使用dropout,rate为0.1;使用Glove词向量,并在训练过程中微调;实验证明,使用3层的biLSTM的效果最好,每一层的输出维度依次是:512,1024,2048。下面是实验结果。
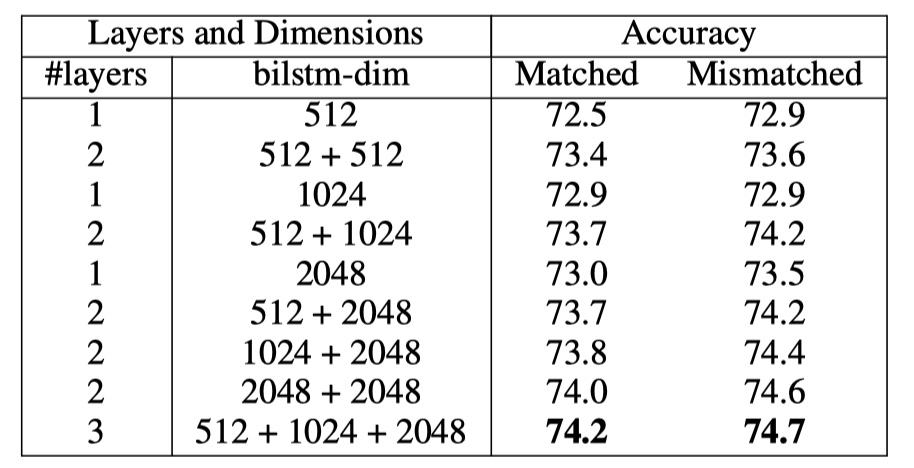
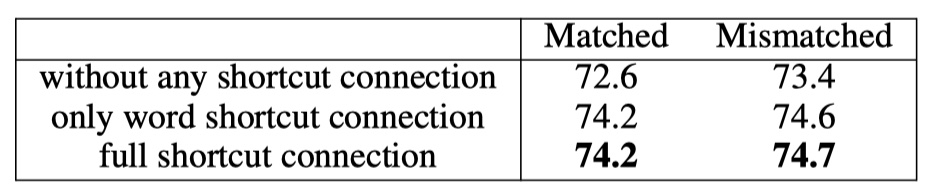

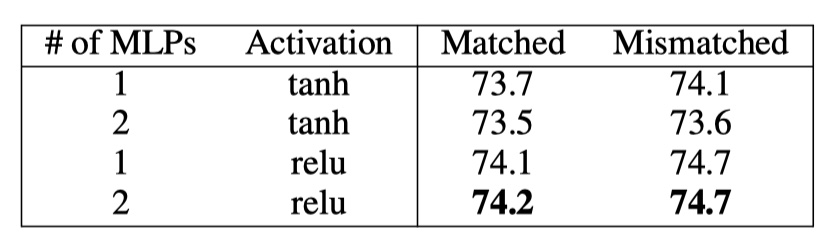
以上就是SSE模型的全部内容啦!效果是比InferSent好,但是估计训练时间要多得多。🥰
SSE模型实现
参考文献
Shortcut-Stacked Sentence Encoders for Multi-Domain Inference

