正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的ESIM模型,并采用tensorflow2实现。
ESIM模型介绍
ESIM模型来源于2017年的论文《Enhanced LSTM for Natural Language Inference》。ESIM模型是文本匹配领域非常有影响力的工作,主要用来解决NLI/RTE问题。直接放图吧~
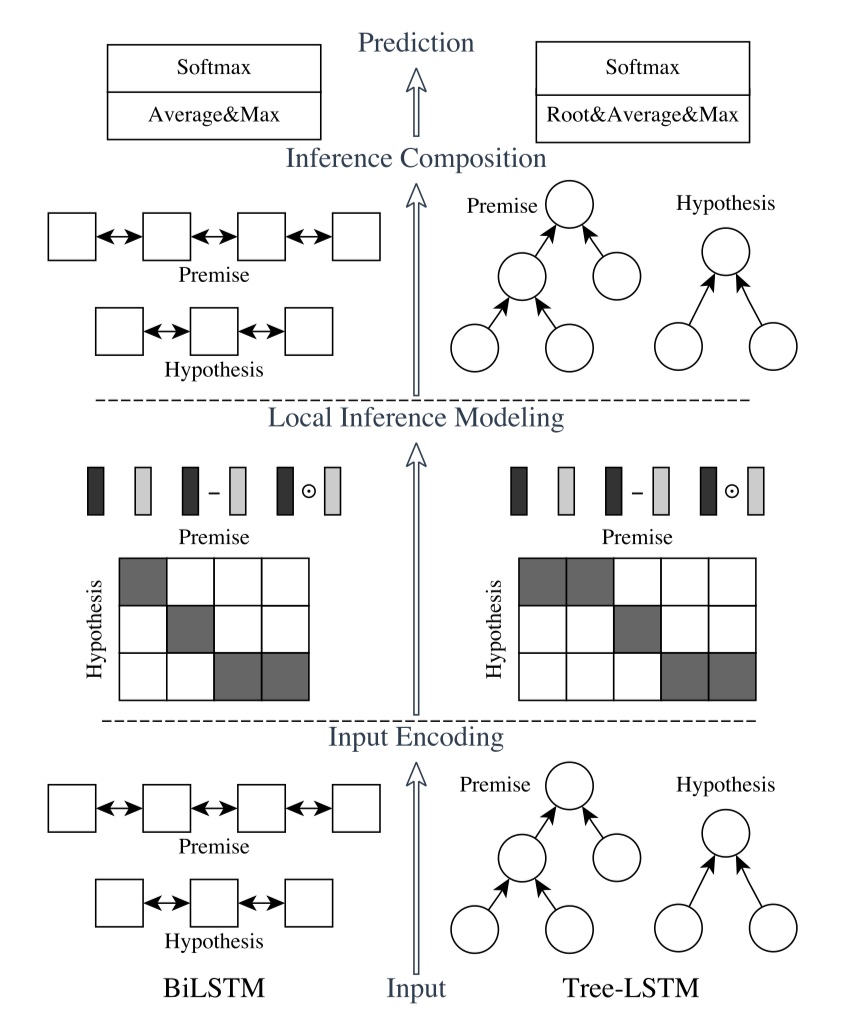
ESIM模型架构总共分为三个部分:input encoding、local inference、inference composition。下面一一介绍~不过在此之前,给定一些符号:两个句子$a=(a_1,a_2,a_3,…,a_{l_a})、b=(b_1,b_2,b_3,…,b_{l_b})$。其中,$a_i\in R^l、b_j\in R^l$。
input Encoding
这一部分就是通过word embedding,得到整个句子的向量化表示,然后输入到BILSTM中(当然也可以使用tree LSTM),得到encode之后的向量。具体公式如下:
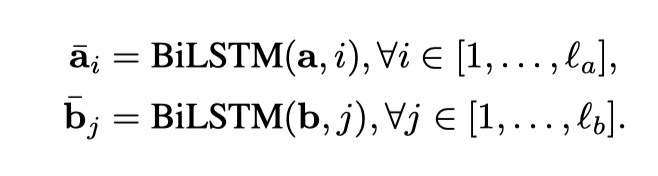
另外,在这里,之所以没有用更加简单方便的BIGRU,是因为作者发现结果不如BILSTM来的更好。
local inference
在得到encode之后的新向量之后,我们需要对两个句子进行局部推理建模,也就是利用attention让两个句子发生交互。具体计算方法DecAtt模型一模一样,只不过去掉了FFN,直接计算Attention weights。具体公式如下:
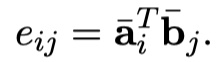
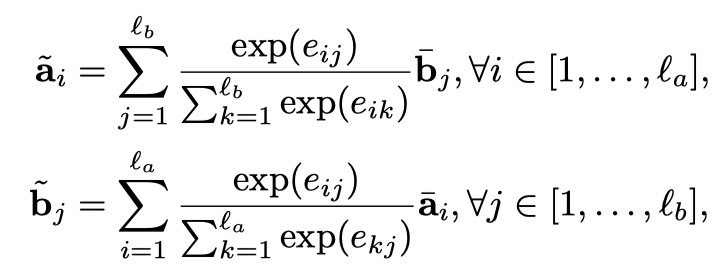
注意:加权得到新的向量的长度没有发生变化,仍然是$l_a、l_b$。在得到新向量之后,再做了local inference information的enhancement,这里的enhancement指的是:原来的向量与加权之后的向量的差与点积。然后将这些向量都进行concat。如下:
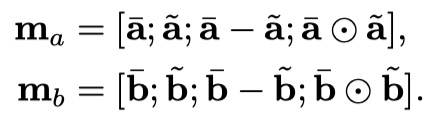
这样做的目的,实际上就是希望能够捕捉到更多的high level的交互信息。
inference composition
最后一步就是inference composition。仍然是将local inference得到的结果输入到BILSTM中,提取上下文信息,然后同时使用averagepooling与maxpooling进行池化,最后使用tanh进行激活,最后加上softmax层,得到最终的分类结果。
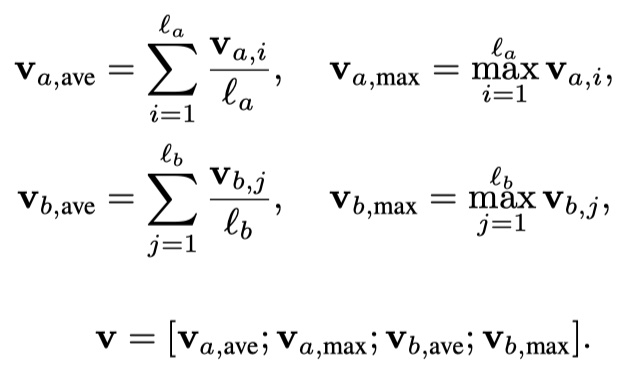
注意,这里,$v_{a,i}、v_{b,j}$是经过BILSTM之后得到的输出。
training details:使用Adam,两个参数为0.9,0.999;初始学习率为0.0004;batch size为32;word embedding为300,使用Glove词向量,并且在训练的时候微调word embedding;对于所有FFN,使用dropout ,rate为0.5。以上就是ESIM模型的全部内容啦!不过说实话,ESIM模型架构上没有啥太新颖的地方,但是效果是真的好!🥰
ESIM模型实现
参考文献
Enhanced LSTM for Natural Language Inference

