正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的CompAgg模型,并采用tensorflow2实现。
CompAgg模型介绍
CompAgg模型来源于《A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES》论文,于2016年提出。CompAgg模型并不是非常新的模型,它是对之前的模型进行了一个总结,提出了Compare-Aggregate模型框架,并对compare function进行了探索。与DecAtt模型类似。总而言之,CompAgg模型提出的原因在于:1.之前的模型只在一两个task上测试,泛化性不强。(换个数据集可能表现就比较差) 2.没有关注于comparison function。
首先直接上模型架构图吧~
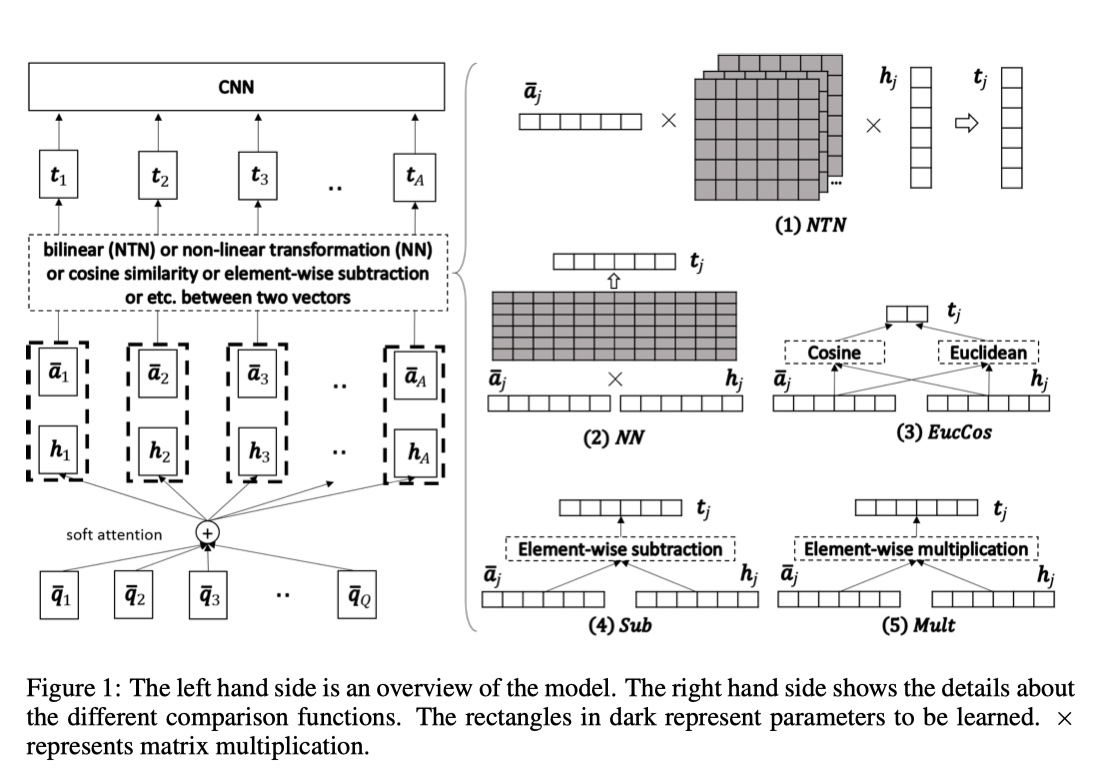
CompAgg模型架构
首先,定义一下训练集$\{Q,A,y\}_{1}^{N}$,(pointwise)其中,$Q、A$分别表示两个句子的向量化表示,并且:$Q\in R^{d\times Q},A\in R^{d\times A}$,其中,$d$表示每一个token的维度,也就是说,每一列表示一个token的embedding。CompAgg模型共分为:Preprocessing、Attention、Comparison、Aggregation这四个部分,下面详细的讲一下。
Preprocessing
这一步是对原始的$Q$与$A$进行一些处理,从而使得每一个词能够获取上下文的信息,从而让每一个token的embedding能够表示更加丰富的语义信息。(直接放图片吧,公式太难敲了😩)
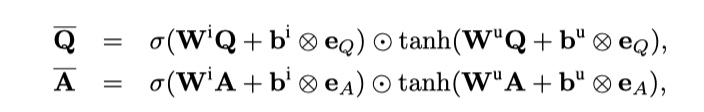
注意,得到的$\hat Q$与$\hat A$的维度分别是:$R^{l\times Q}、R^{l\times A}$。
Attention
这里就是传统的Attention机制。用Q对A进行attention,然后得到加权后的Q,即H。公式如下:
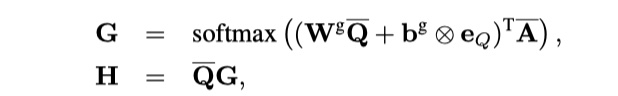
注意,G与H的维度分别是:$R^{Q\times A}、R^{l\times A}$。
Comparison
这一步主要是matc上一步得到的$\hat A$与$H$。在这一步,作者实验了6中compare function:NN、NTN、EucCos、SUB、MULT、SUBMULT+NN。
- NN:实际上就是将两个向量concat,然后经过一层神经网络。
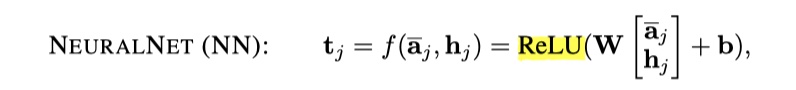
- NTN:实际上就是使用NTN来concat两个向量,然后经过一层神经网络。
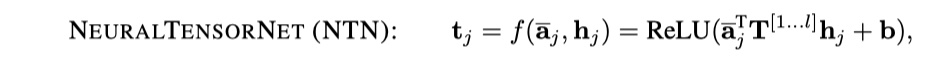
- EucCos:实际上就是计算两个向量的欧式距离和余弦相似度,然后将结果concat。
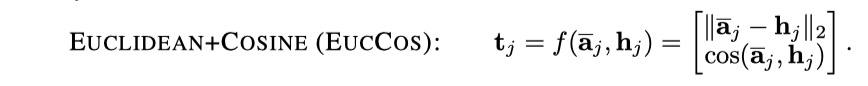
- SUB与MULT:实际上就是两种基于element-wise的方式来对向量进行比较。
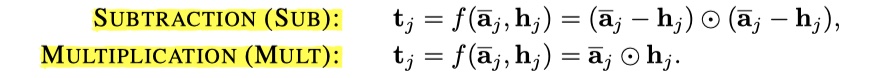
- SUBMULT+NN:实际上就是将上面的结果concat,然后经过一层神经网络。
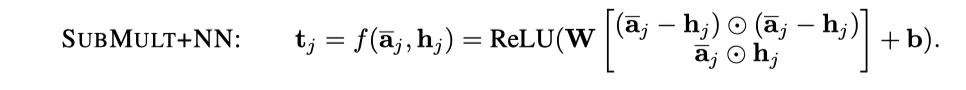
注意,上面的方法,都是两个句子对应位置单词之间的compare,所以compare之后,得到的向量的长度食欲A一样的。
Aggregation
这一步就是将comparison得到的结果,经过一层CNN,得到最后的结果。
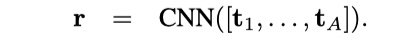
其中,$r$的维度是:$R^{nl}$,$n$表示filter的数量。注意:$[t_1,t_2,t_3,…,t_A]$的维度是:$R^{l\times A}$。
final classification
对于NLI问题,实际上就是一个三分类问题,接一个softmax层就可以啦!对于问答匹配问题来说,假设有K个candidate answer,我们要从中选择出一个answer,我们可以先计算出$[r_1,r_2,r_3,…,r_k]$,然后使用下属公式来预测:
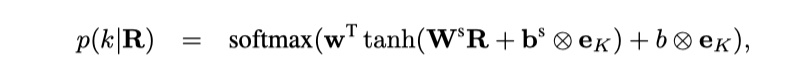
以上就是CompAgg模型的内容,还是蛮好理解的。最后作者进行了实验,发现结果比Siamese NN要好一些,说明基于交互的SiameseNN在分别encode两个句子的过程中,丢失了一些信息,没有充分利用,整个论文还是值得一读的!
CompAgg模型实现
参考文献
A COMPARE-AGGREGATE MODEL FOR MATCHING TEXT SEQUENCES

