正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的SiamLSTM模型,并采用tensorflow2实现。
SiamLSTM模型介绍
SiamLSTM模型来源于《Siamese Recurrent Architectures for Learning Sentence Similarity》论文,是在2016年提出的。SiamLSTM模型所要解决的是预测句子之间的相似度。SiamLSTM模型的架构和SiamCNN非常地类似,毕竟都是Siamese神经网络嘛🥰。直接放图吧~
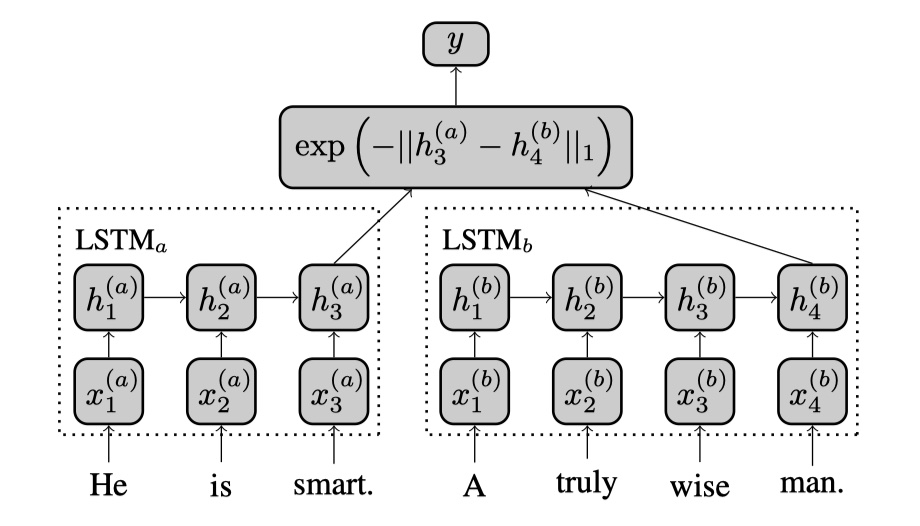
模型本身并不是很难,不过有两个地方需要注意:第一个是,两个句子最后使用的是只有最后一个step的hidden state;第二个是,SiamLSTM所使用的相似度的计算方法(1范数),如下:
最后,SiamLSTM模型使用的是SemEval 2014数据集。训练集:SemEval 2014 train data,共5000条
测试集:SemEval 2014 test data, 共4927条。每条数据的形式是:[“I like playing basketball.”,”My favourite sports is basketball.”, 3.4]。由于SiamLSTM使用的相似度计算方法,导致结果是在$[0,1]$区间的,所以最后需要对结果进行缩放,从而在$[1,5]$之间。SiamLSTM模型使用的损失函数是MSE。
论文提到的训练的一些details:使用AdaDelta,使用梯度裁剪,使用SGD,LSTM的输出维度是50。
以上就是SiamLSTM模型模型的全部内容啦🥰(说实话,最近看文本匹配的论文,真的感觉不难,比起之前看reformer、BERT等的文章,真的是太轻松啦,希望之后不要打脸🥰)
SiamLSTM模型实现
参考文献
Siamese Recurrent Architectures for Learning Sentence Similarity

