正式开始看文本匹配的东西啦!文本匹配对NLPer来说是很重要的,不管是最后是做对话、推荐、搜索,文本匹配都是必不可少的。当然啦,BERT系列的模型出来之后,其实传统的深度学习模型效果是远远比不上的。不过这些预训练模型效果好是好,但是训练代价昂贵,当然啦,有人会说,现在已经有剪枝、量化、蒸馏这样的方法来减小预训练模型的大小,从而降低训练所需的代价(所以说模型压缩、加速这个方向还是很有前景的🤩咦,好像跑偏了,anyway),但是这仍然远远不够,所以熟悉传统的文本匹配模型是非常有必要的。本篇博客讲解经典的SiamCNN模型,并采用tensorflow2实现。
SiamCNN模型介绍
SiamCNN模型来源于《APPLYING DEEP LEARNING TO ANSWER SELECTION: A STUDY AND AN OPEN TASK》(后来查了一下,SiameseCNN最初用来解决图像问题,anyway,都是相通的🤩)。这个模型要解决的就是answer selction(问答匹配)问题。什么是问题匹配问题呢?如下:
给定一个问题 $q$ 以及问题 $q$ 的答案候选池$\{a_1,a_2,…,a_s\}$,通过模型,从中选出最好的答案$a_k$,如果说选出的答案 $a_k$ 在问题 $q$ 的truth set里面的的话,那么,就说问题$q$被正确的回答了,否则就说明问题 $q$ 没有被很好地回答。这就是问答匹配问题。
定义问题之后,接下来就是给出模型架构。SiamCNN模型的架构比较简单:首先学习得到给定的问题及其候选答案池的向量化表示,然后使用相似性度量方法来衡量匹配度。模型的训练实例的构造方式或者说是学习策略,是pairwise。即:我们构建的训练实例是:$(q_i,c_i^+,c_i^-)$,其中 $q_i$ 表示问题,$c_i^+$ 表示给定问题的一个正确答案,$c_i^-$ 表示给定问题的一个错误答案。损失函数为hinge loss,公式是:$L=max\{0,m-h_\theta(q_i,c_i^+)+h_\theta(q_i,c_i^-)\}$,其中,$m$表示边界阈值,如果说$L$大于0,那么说明模型把错误答案排在正确答案之前;如果说$L$等于0,那么说明模型把正确答案排在错误答案之前。所以hingle loss的目的就是要促使正确答案的得分比错误答案的得分高m。在预测阶段,得分最高的候选答案被当作正确答案。
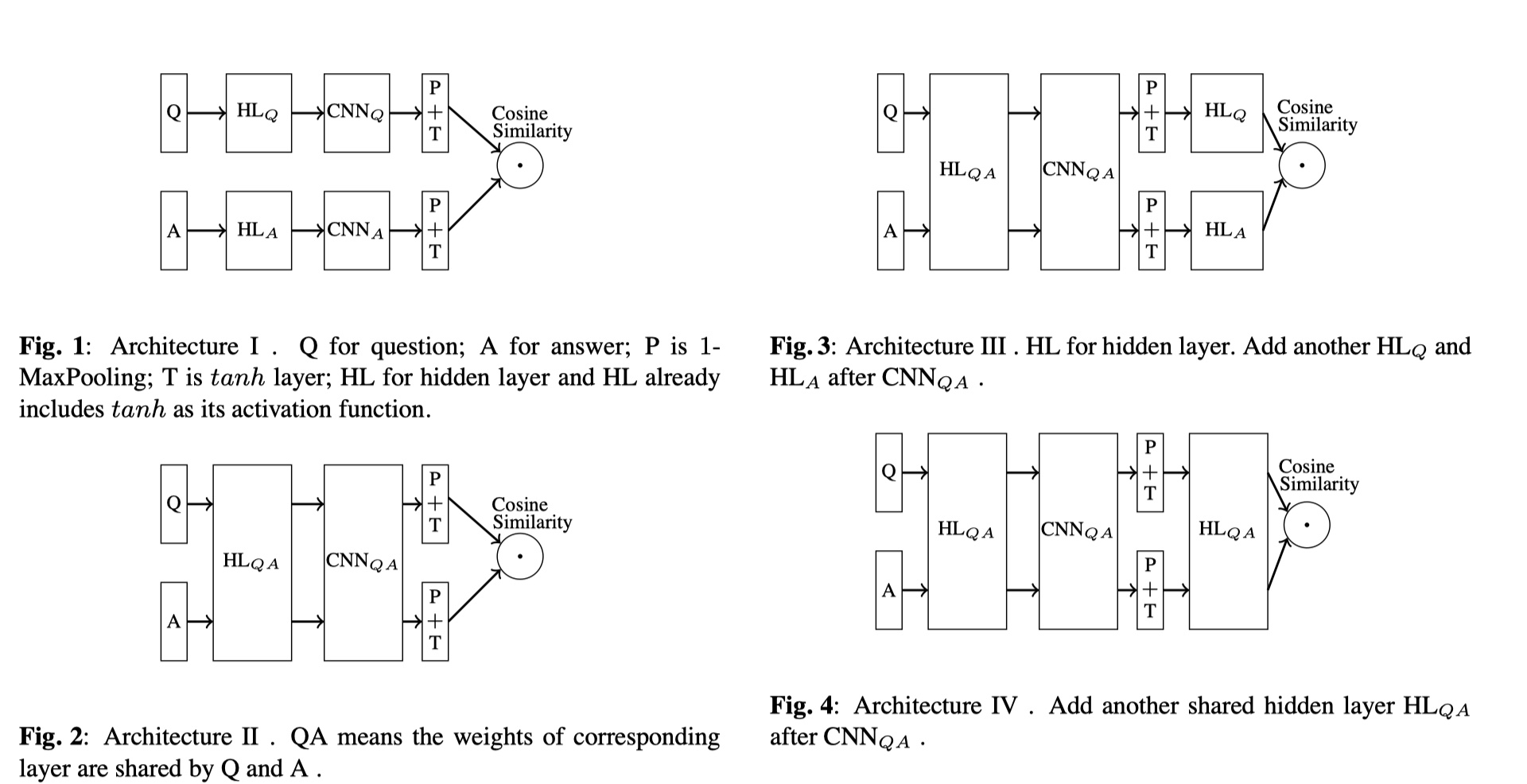
上面这张图就是作者给出的SiamCNN模型的结构。作者做了很多实验,对架构做了很多改进。最后发现第二中架构是最好的,即:首先是tanh层,也就是对Q、A的向量化表示进行激活,但是两者共享权重参数;第二层是卷积层,同样也是共享权重参数;第三层是max ppoling层,一般是使用1 max pooling,选出与input最相关的特征;第四层是tanh层;最后根据相似度衡量方法来得到结果。
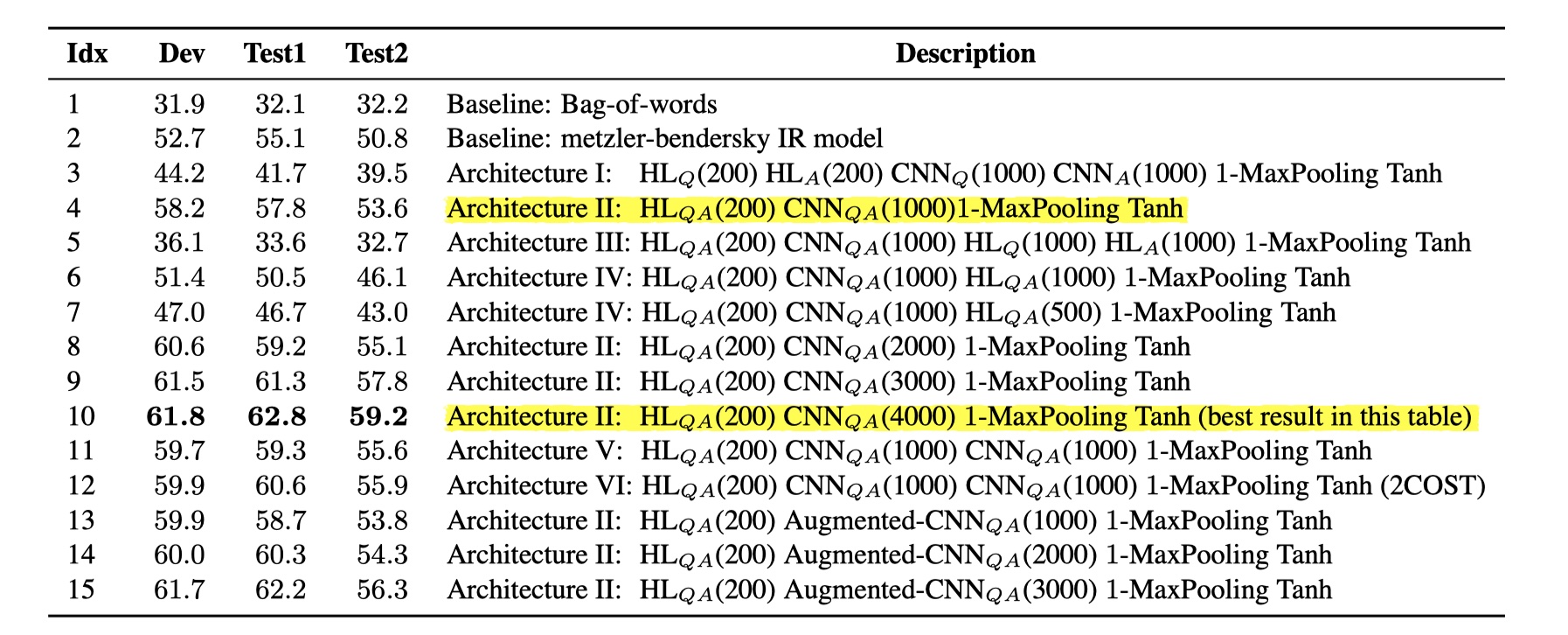
这是作者的实现结果,第10行就是第二个架构的结果。经过实验之后,作者给出了几个有意思的结论:
- 参数共享层的使用比参数分开的情况,效果要好得多;
- 不需要在卷积层之后,再添加hidden layer,因为卷积层已经能够很好的提取出有用的特征,而加入hidden layer反而会降低效果;
- 提高filter的数量会提高效果;
- 多层的卷积层能够提取更加高层次的语义特征,也可以提高效果;
- 不同的相似度衡量方法会对结果产生很大的影响,所以要慎重选取相似度衡量方法。
以上就是SiamCNN模型的内容,我个人觉得这是一篇非常好的文章,虽然内容较为简单,但是给了我们很多启发,之后,我们在做文本匹配的时候,也可以参考。当然啦,在BERT面前,这些模型都显得逊色许多,不过仍然非常具有启发性。🤩
SiamCNN模型实现
参考文献
APPLYING DEEP LEARNING TO ANSWER SELECTION: A STUDY AND AN OPEN TASK

