最近在看文本分类系列模型,应该会陆续更新几篇有关文本分类模型的博客,大概一周内更新完成,之后开始做文本匹配的东西。虽然这些模型网上有很多解读了,但是只有自己写出来了,才算是自己的呀。本篇博客讲解最为经典的HAN模型,并采用tensorflow2来进行实现。
HAN模型简介
HAN模型大体的思想是:将word embedding通过attention机制得到sentence embedding,再通过sentence embedding 得到document embedding,最后加上一个分类层,得到最终的文本分类结果。模型架构如下:👇
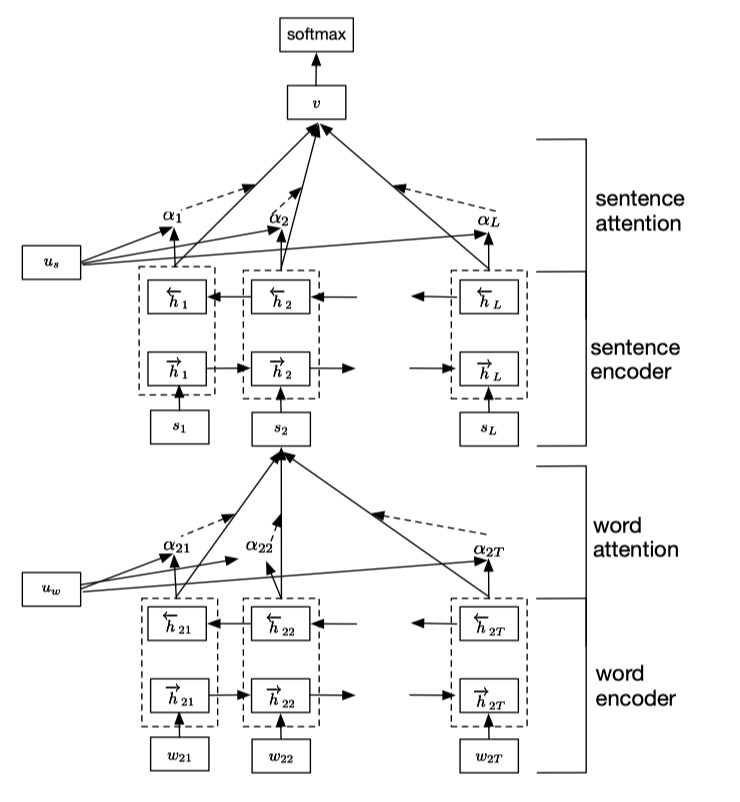
整体架构比较简单,在这里,说几点需要注意的地方:
模型的输入是:(batch_size,max_sentence,max_word),这点非常重要。
HAN模型实现
暂无。
参考文献
Hierarchical Attention Networks for Document Classification

