最近在看文本分类系列模型,应该会陆续更新几篇有关文本分类模型的博客,大概一周内更新完成,之后开始做文本匹配的东西。虽然这些模型网上有很多解读了,但是只有自己写出来了,才算是自己的呀。本篇博客讲解最为经典的DPCNN模型,并采用tensorflow2来进行实现。
DPCNN模型简介
DPCNN模型是张潼博士在2017年提出的模型。这个模型可以说是非常的出色,是第一个word level的深层文本分类卷积神经网络,优点在于:能够非常长的文本依赖的同时,时间复杂度又相对较低,废话不多说,直接上图。👇
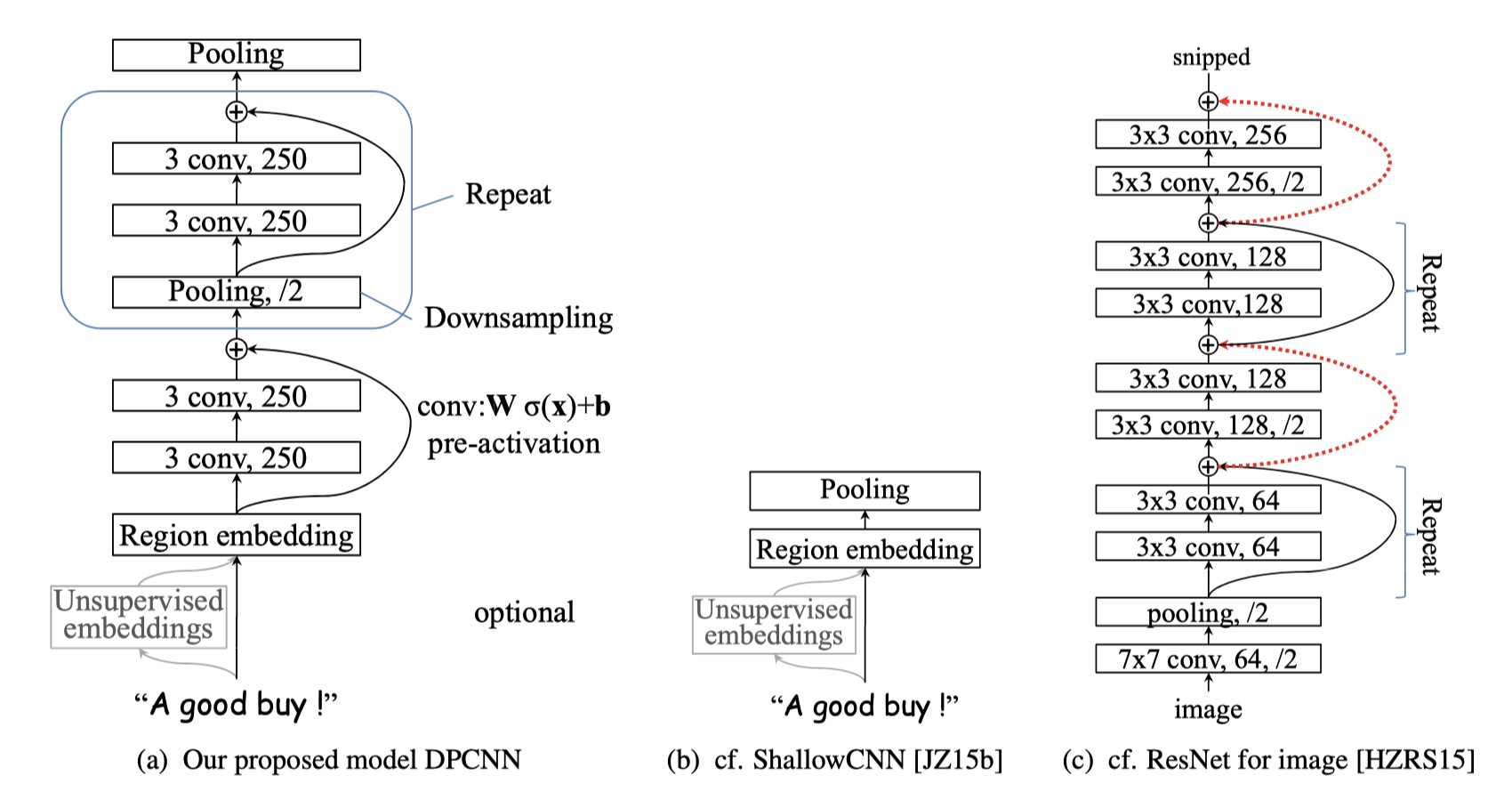
DPCNN(深度金字塔卷积神经网络)之所以被提出,主要有这么几点:1.CNN比RNN更有优势,这在于CNN良好的并行计算效率;2.作者发现word level的CNN比深层的character level CNN效果要更好,所以word level的CNN有进一步的挖掘的潜力;3.但是如果只是单纯的加深网络,得到的效果反而不好,所以需要进行设计,就提出了DPCNN。
整个网络架构还是挺好懂的,下面主要介绍一下DPCNN模型几个重要的部分。
text region embedding
正如字面意思,text region embedding是针对一个文本区域进行卷积操作,得到的embedding。需要注意的是,这里使用的是等长卷积。为什么要使用等长卷积呢?原因在于:通过等长卷积,我们能够克服textCNN模型中缺点,从而能够捕获长距离信息,从而提高embedding的表示的丰富性。
固定feature map的数量
为什么要这么做呢?原因在于:通过固定feature map的数量,实际上就可以得到更高层次的语义信息。
1/2池化层
我们通过使用池化层,就可以将模型感受文本的范围扩大一倍。在论文中,使用的是stride=2,size=3的池化层。
残差连接
当然了,非常深的网络,非常容易导致梯度消失问题。在DPCNN中,借鉴了ResNet的思想,使用残差连接。
DPCNN模型实现
暂无。
参考文献
- Deep Pyramid Convolutional Neural Networks for Text Categorization
- https://zhuanlan.zhihu.com/p/35457093

