最近在看文本分类系列模型,应该会陆续更新几篇有关文本分类模型的博客,大概一周内更新完成,之后开始做文本匹配的东西,虽然这些模型网上有很多解读了,但是只有自己写出来了,才算是自己的呀。本篇博客讲解最为经典的textCNN模型,并采用tensorflow2来进行实现。
textCNN模型简介
textCNN是2014年所提出的一个模型,可以说是非常早了。它的模型也非常简单,直接放图👇。
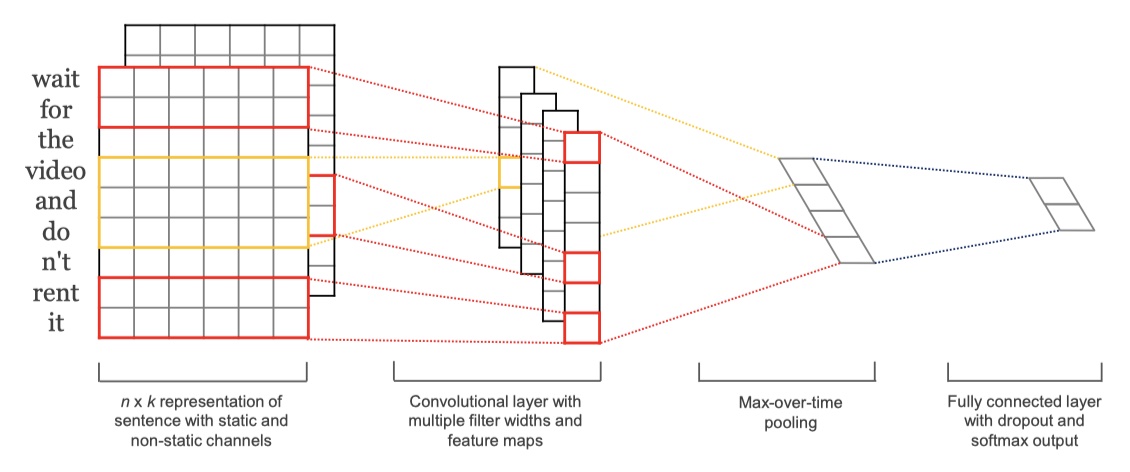
- 首先是输入层,是单词的embedding得到的矩阵,维度是(batch_size,seq_length,embedding_size)。在论文中,作者实验了好几种策略:1.CNN-rand:对单词的词向量随机初始化;2.CNN-static:使用word2vec得到的word embedding,并且在训练过程中,不更新embedding;3.CNN-non-static:使用word2vec得到的word embedding,但是在训练过程中,更新word embedding;4.CNN-multichannels:使用两个channel,两个channel都是使用word2vec使用的word embedding,但是一个不随着训练过程更新,一个随着训练训练过程更新。(这样做的目的主要是防止过拟合)结果证明,第三种效果最好。
- 然后是卷积层,类似于n-gram,可以使用多个不同尺寸的卷积核,在论文中,使用(3,4,5)三种卷积核,激活函数为relu,每一种卷积核都有100个,即每一种卷积核得到的feature map都有100个。
- 之后是全局最大池化层(max-over-time pooling layer),也就是对于每一个feature map,我们从中得到一个数值最大的feature。譬如:3种卷积核,每种100个,那么得到300个feature map(3*100),经过max-over-time pooling之后,得到的结果是300维的向量。
- 最后是一个softmax层。在论文中,对经过全局最大池化层之后的输出,进行了dropout操作,防止过拟合。
这就是整个textCNN模型,可以说是非常简单的思路了~
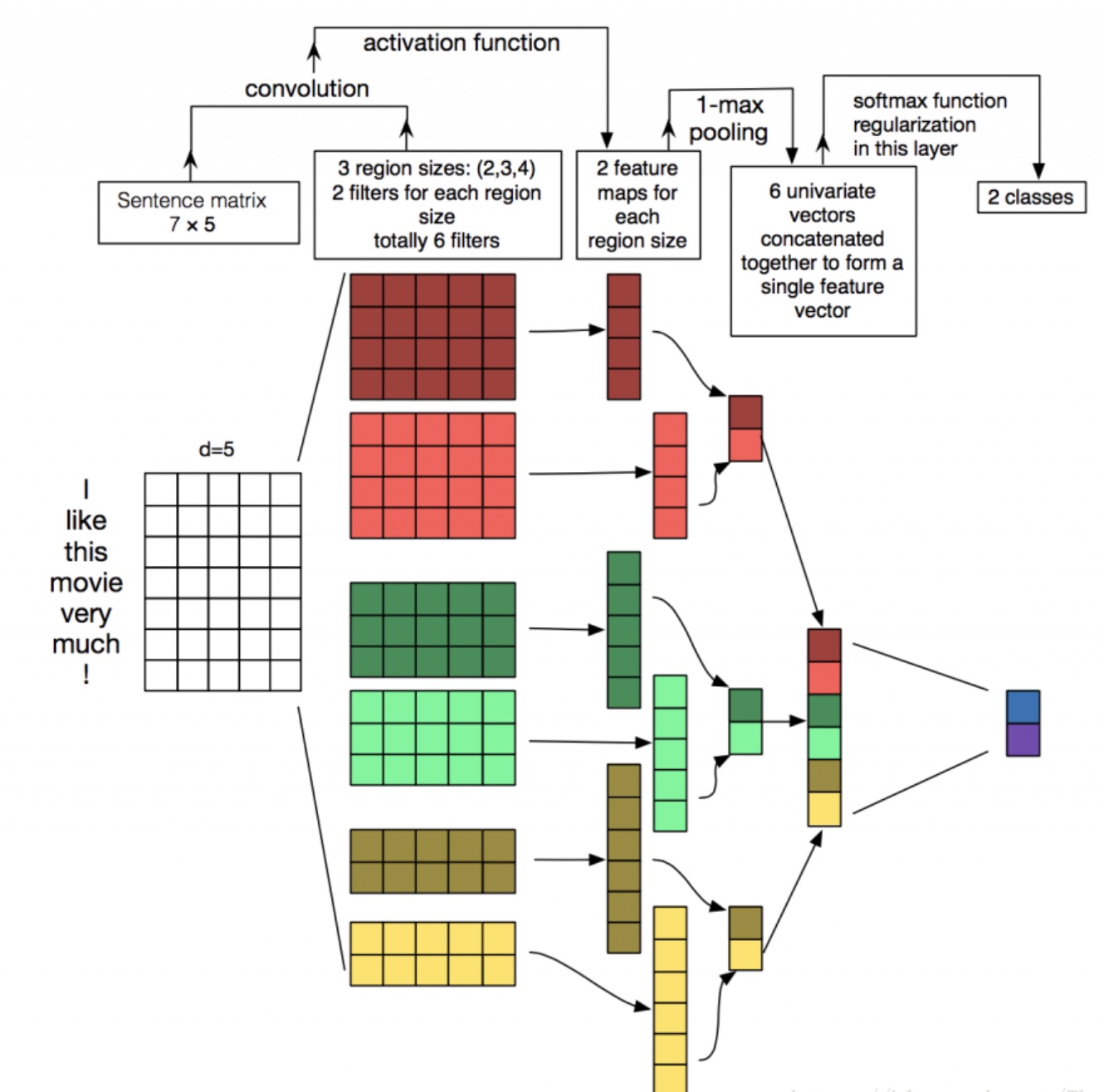
(放一张卷积操作的过程图~图片来源)
textCNN模型实现
暂无。
参考文献
Convolutional Neural Networks for Sentence Classification

