在如今的NLP领域中,预训练模型占据着愈发重要的地位。而BERT的出世,更是几乎横扫了NLP中所有的任务记录。本篇博客将详解几大预训练模型:ELMo、GPT、BERT、XLNet、ERNIE、ALBERT。(下图是可爱的bert😋注意,这真不是芝麻街啊喂!)

本篇文章致力于讲解清楚各个预训练语言模型的原理,但是细节部分不会展开讨论,譬如transformer架构的原理、self-attention的原理、highway network的原理等等,这些基础的东西请自行查找资料进行补充~
ELMo模型介绍
ELMo模型,全称:Embedding from Language Models。这个模型所要解决的问题是:1.词向量要更好地表达语法与语义等信息;2.单词在不同的上下文会有不同的意思,而传统的word2vec等word embedding模型,每一个单词的词向量都是固定的,也就是与上下文无关,这对于处理单词的多义性非常地不友好。所以,ELMo模型就是利用深度的双向LSTM模型来解决这些问题。
ELMo模型的大体结结构
ELMo模型的大体结构是:多层的biLSTM语言模型。结果如下:
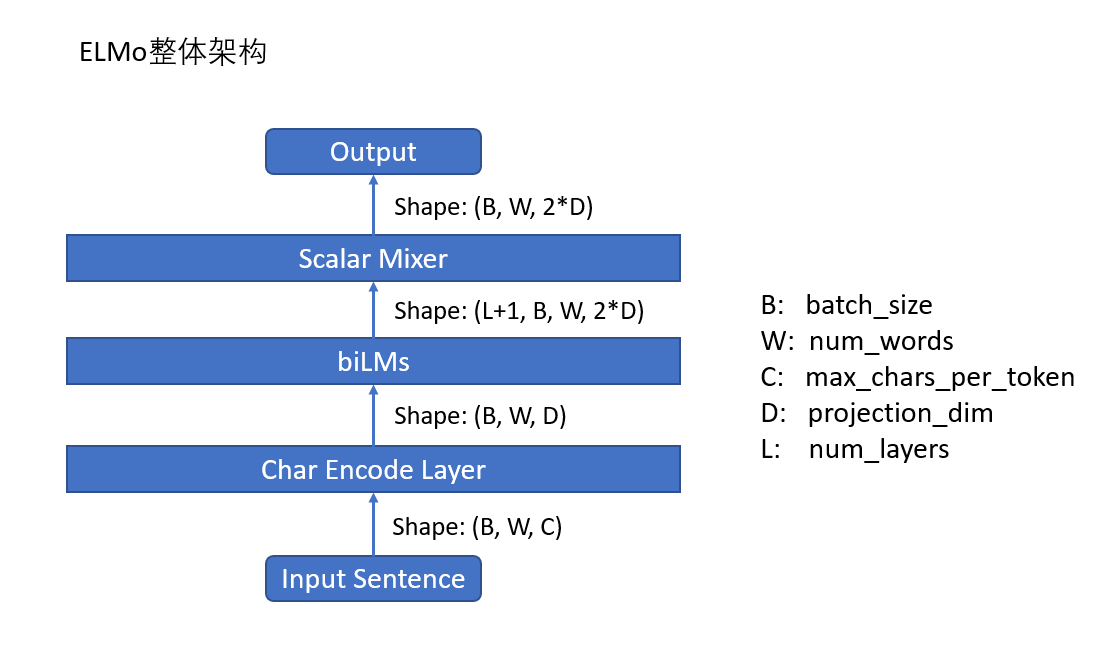
- 首先是输入
Input Sentence。它的shape是(B,W,C)。其中,B表示batch_size,W表示一个句子的token的数目,C表示一个token的最大字符数,在论文里是固定的数目:50。在这里,需要明确的是:ELMo模型是以字符为单位进行编码的。 - 接着,进入 char encoder layer。在ELMo模型,会对每一个字符进行编码,也就是给每个字符进行embedding。然后,经过一些一维卷积操作,以及highway操作,最后的输出维度为:
(B,W,D)。 - 将char encoder layer的输出作为biLSTM layer的输入,假设 biLSTM layer有L层,最终输出的维度为:
(L+1,B,W,2*D)。在这里,之所以+1,是因为把 char encoder layer的输出也算进去了。 - 最后,将
(L+1,B,W,2*D)的输出作为 scalar Mixer的输入,其实就是将这L+1个输出进行加权平均并且放缩,最终的输出的维度是:(B,W,2*D)。这就是最终生成的ELMo词向量。
下面来具体介绍一下每一层的结构。
Char Encoder Layer

- char encoder layer的输入维度是
(B,W,C),然后需要被reshape为(B*W,C)。之后针对每一个token的每一个字符进行编码。字符表总共有262个,其中,0-255是unicode编码,其余的是:<bos>,<eos>,<bow>,<eow>,<pow>,<pos>。其中每一个字符的embeddng的维度是d。所以,整个词表的维度是:262*d。经过char embedding之后,输出为:(B*W,C,d)。 - 紧接着,我们需要使用一维卷积。这里需要注意的是:并不是在纵向上叠加很多卷积层,而是在横向上使用若干个一维卷积层。在ELMo中,使用了m个一维卷积。以第一个为例:卷积核为k1,个数为d1,那么一维卷积后得到的维度是:
(B*W,C1,d1);接着,再使用maxpooling(之所以要使用maxpooling,是因为经过卷积之后,各个向量维度可能不一致,无法合并,所以才需要进行pooling操作),从中选择出最大的单词,其维度变为:(B*W,d1),最后再经过激活函数,就完成了一个操作。 - 在完成m个卷积操作之后,我们将得到的m个向量在d维进行concat,并且需要reshape,即得到的维度为:
(B,W,(d1+d2+d3+...+dm))。 - 接着,我们在经过若干个highway层。所谓的highway层的作用与残差连接是一样的,能够让网络训练的效率随着深度的增加不降低。具体的公式请参看highway的原始论文。
- 最后,需要进行一个线性变换,将维度从
(B*W,(d1+d2+d3+...+dm))变为(B,W,D)。这里的D是最后我们得到的ELMo词向量维度的一半。
biLSTM layers
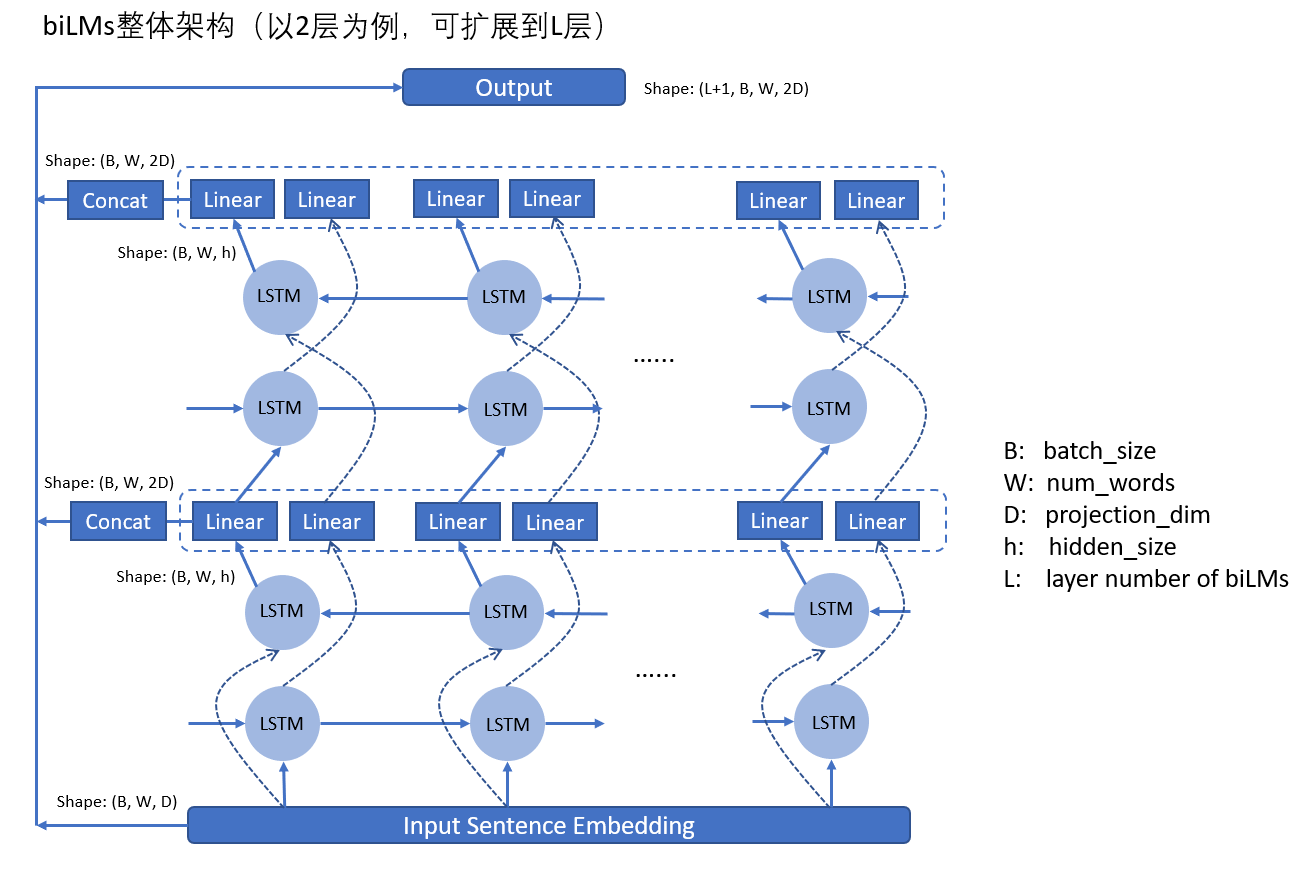
- biLSTM layers是接在 char encoder layer之后的,它的输入维度是:
(B,W,D)。biLSTM相信大家都很熟悉了,在这里,假设LSTM的 hidden state的维度是h,那么LSTM的输出是(B,W,h)。当然,我们需要进行一个线性变换,将维度从(B,W,h)变成(B,W,D)。由于是双向的,所以,我们concat之后,得到的一层的输出是:(B,W,2D)。 - 注意,在biLSTM层,每一层的LSTM的输出作为下一层LSTM的输入。假设有L层biLSTM,那么,我们最后得到的输出向量个数为L+1个,因为最初的char encoder layer的输出也要算进去。所以biLSTM layers最终的输出维度是:
(L+1,B,W,2D)。
这里需要着重讲一下ELMo中biLSTM的使用,这也是其与BERT最大的不同。
在ELMo中,其实是训练了两个正反向的语言模型。前向的语言模型的概率如下:
后向的语言模型的概率如下:
ELMo模型的目标函数是:
其中$\theta_x$表示词嵌入的参数;$\theta_s$表示softmax之前的参数,即输出层的参数;$\overrightarrow{\theta_{LSTM}},,\overleftarrow{\theta_{LSTM}}$表示biLSTM层的参数。所以,我们可以看出,ELMo模型是分别训练两个LM,并不是真正的双向语言模型,这就是ELMo模型与BERT最大的区别。
Scalar Mixer
在biLSTM layers之后,我们需要输入到scalar mixer,即做一个变换,得到最终的ELMo词向量。我们需要注意的是,在每一个位置k,每一层都会生成一个关于词向量的表示$\overrightarrow {h_{k,j}^{LM}}$。其中,j表示第j层。一个L层的biLSTM,会生成2L+1个词汇表征。
第k个位置的最终的词向量如下公式:
其中,$s_j$表示经过softmax之后的概率值,可以理解为各个层的输出的权重;常数参数$\gamma$是缩放参数,用来对整个ELMo词向量进行缩放。这两个参数是需要学习的超参数。此外,每一层的输出的分布会有比较大的差别,有时候使用layer normalization。经过 scalar mixer之后,我们得到的最终的ELMo词向量的的维度是:(B,W,2*D)。
之后如果介入NLP下游任务,那么可以固定ELMo模型,不让其参与训练,也可以让ELMo模型参与训练,对词向量模型进行fine-tune。
总结,ELMo的优势在于:
- 得到的词向量更好,词向量与其上下文内容有关,能够解决单词的多义性问题;
- 使用了深层网络的所有的输出,比只是用顶层的LSTM layer更好;具体来说,低层的LSTM layer能够表示单词的语法信息;高层的LSTM layer能够表示单词的语义信息;
- 基于字符进行embedding,解决了OOV问题。但是注意,我们最后得到的是词向量!
GPT模型介绍
GPT模型,全称:Generative Pre-Training。它的整个过程分为两个阶段:1.无监督的预训练;2.有监督的微调。下面依次介绍这两个阶段。
pre-training
GPT模型,采用的是Transformer的 decoder部分作为language model,但是稍微有点不同:其去掉了encoder-decoder attention layer。它的目标函数是:
这就是一般的LM的目标函数。其中,$k$表示的是context window。(使用了markov假设?) $\theta$表示网络的参数;我们使用SGD来进行训练。

上图就是GPT的模型。左边就是使用transformer的去掉了encoder-decoder attention layer的decoder。注意,既然使用了decoder部分,那么网络在预测当前词的时候,就不能看到未来的信息,并且也无法并行化操作。如果使用公式来表示的话,则有:
fine-tune
以分类任务为例,我们在使用LM得到最后一步的输出之后,我们再接上一个线性层。譬如现在有一个句子,表示为:$(x_1,x_2,…,x_m)$,其标签为$y$。我们使用LM得到最后一个输出是$h_l^m$,在将其喂入一个线性层,从而得到结果,表示如下:
目标函数如下:
那么,我们将LM作为一个辅助的目标函数,这样做的好处有两个:1. 提高模型的泛化能力;2. 加速收敛。如下:
模型的一些修正细节:

总结,GPT模型的优势如下:
- 使用了transformer而不是biLSTM,这样大大增强了模型的捕捉依赖关系的能力;
- GPT是把模型接入到下游任务进行训练,可以加上原来的LM作为辅助目标函数。不侧重生成offline的词向量。
BERT模型介绍
终于写到BERT啦,哈哈哈。BERT可以说是带火了预训练模型,BERT系现在大有统一NLP之势啊。废话不多说,直接进入正题!🤩
BERT模型,全称叫做:Bidirectional Encoder Representations from Transformers。从名字看就很直观,BERT是双向transformer的encoder部分。它所要解决的问题是:不管ELMo还是GPT,语言模型都是单向的,而BERT的作者发现,单向语言模型限制了fine-tuning的表达能力。所以,BERT所采取的方式是:使用双向的Transformer的encoder部分进行预训练,并采用MLM与NSP两种任务对BERT进行pre-training,之后在对接下游任务的时候,fine-tuning。
输入是什么?
BERT的输入,可以是单个句子,也可以是句子对。但是在预训练的时候,实际上都是输入的句子对。在BERT中,使用的是BPE vocabulary,size为30000,最长的输入长度为512。之所以是512,是为了减少padding的计算浪费。这个在源码中可以看到。
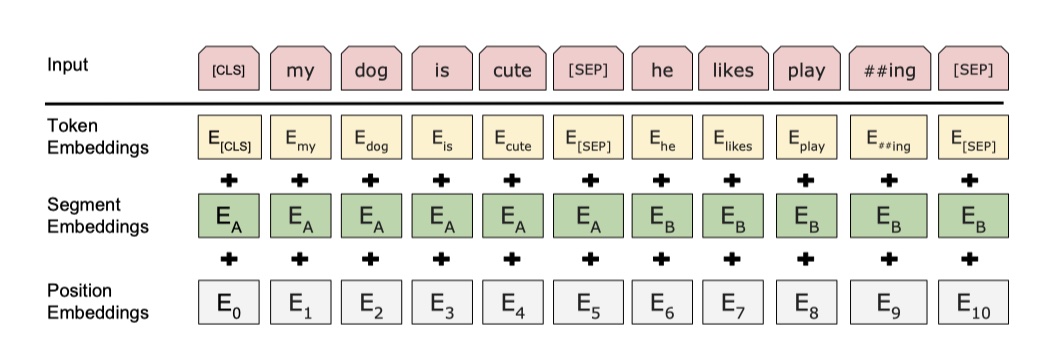
这是BERT的输入,有三部分:token embedding,就是每一个token的embedding,这个可以使用 word2vec的结果,也可以随机初始化;segment embedding,就是就来区别两个句子;position embedding,就是用来表示每一个token的位置信息,和transformer一样。这里需要注意的是:句子的第一个token一定是CLS,这是为了给后面做分类准备的,实际上是NSP任务来训练CLS token的。
BERT中给的例子如下:
1 | This text is included to make sure Unicode is handled properly: 力加勝北区ᴵᴺᵀᵃছজটডণত |
这是BERT给的例子的输入。BERT对与输入的文本的要求是:1. 一个句子一行;2. 不同文章之间空一行,防止跨文章读取。那么,处理原始文本之后,得到的输出有:
- tokens:包括了普通的token,以及CLS、SEP、MASK。
- segment_id:0表示是第一句话,1表示第二句话
- is_random_next:是否为下一句,NSP人物的label
- masked_lm_positions:被MASK的token的位置
- masked_lm_labels:被MASK的token的原本的值
1 | tokens: [CLS] for more than a [MASK] up [MASK] great main street , [MASK] [MASK] [MASK] centre of the city , at right angles , [MASK] one equally magnificent , at each end ##ミ which , miles away , appeared , dim and distant over the heads of the living stream of passengers , the yellow [MASK] - hills of [MASK] [MASK] ; while at the end of the vista in front [MASK] them gleamed the blue harbour , through a network [SEP] possibly this may have been the reason why early rise ##rs in [MASK] locality , during the rainy season , adopted [MASK] [MASK] [MASK] of body , and seldom lifted [MASK] eyes [MASK] the rift [MASK] or india - ink washed skies above them . [SEP] |
pre-training
Masked Language Model
标准的语言模型,是单向的,只能根据之前的所有词来预测当前词。在BERT中,使用的是双向的transformer的encoder,这样不就让单词能够看到未来的内容了吗?BERT的处理方式就是使用MLM。MLM的核心思想是:随机mask掉句子的一部分内容,然后使用上下文来预测被mask的词。在论文中,具体的是mask掉句子的15%的token。但是这样做存在一个问题:在fine-tune中,模型可能会从来没见过mask掉的词,这样就会导致与fine-tune的输入分布不一样,为了减小这个问题。论文中提出,在每次选定一个单词进行mask的时候:
- 有80%的概率,使用MASK替换;
- 有10%的概率,随机选定一个token进行替换;(加入噪声,使得模型更加具有鲁棒性)
- 有10%的概率,保持原样。(为了能够靠近fine-tune的输入分布)
所以,我们可以看到,模型每次只预测15%的token,所以收敛的速度会非常慢,这也是BERT的缺陷之一,也是后来XLNet提出的原因之一。
Next Sentence Prediction
之所以设计这个任务,主要是为了解决需要确定句子对之间的关系的任务而设计的,譬如QA、文本蕴含、NLI等等。因为作者认为LM里面学不到这样的知识。这个任务要做的是:预测后面一个句子是不是前面一个句子的下一句。具体的做法是:以50%的概率选择一个句子是前面一个句子的下一句,label是:isNext;以50%的概率选择不是前面一个句子的下一句的句子,label是:NotNext。(然而,实验证明,NSP任务并没有什么用,所以,后来ALBERT改进了NSP任务,产生了很好的效果。)
fine-tuning
fine-tuning与GPT没什么大的不痛,都是根据下游任务更改很少的顶层参数。对于分类任务,只加了一层分类层。
总结,BERT模型的优势:
- 使用了transformer的encoder部分,特征抽取能力比lstm要强;
- 使用了MLM,是真正的双向语言模型,能够使用上下文的信息来预测被MASK掉的单词。
XLNet模型介绍
XLNet模型是对BERT模型收敛太慢的改进,当然,XLNet模型并不只是这些。在了解XLNet模型之前,需要去了解transformer-xl这个模型,因为,XLNet模型就是基于transformer-xl而得来的。这里,我就不具体讲transformer-xl,简单提一下transformer-xl相较于transformer的改进的地方吧,有兴趣的筒子们可以自己去看transformer-xl的原始论文~(注意,目前基本没有延续XLNet的研究,所以这块大家如果不感兴趣的话,可以不去细看;当然也可以仔细研究,说不定在这上面就能搞出新点子也说不定哈哈~)
- transformer-xl是基于vanilla transformer的得来的。vanilla transformer的训练方式是:将训练文本进行分段,在每一段中分别去训练LM。在预测的时候,我们使用limited context来预测下一个单词,没预测完一个单词,就讲window向右移动一个字符。这样做的缺点在于:1.单词的上下文的长度受限,在原始论文中,只能处理512长度的输入文本;2. 推理速度非常慢,每次预测一个单词,都要重新计算;3.段与段之间没有上下文依赖性,影响模型性能。transformer-xl在此基础上引入了两个两个机制:循环机制与相对位置编码。
- 循环机制。循环机制的引入是为了解决段与段之间没有上下文依赖性。它能够让当前段在进行LM建模的时候,能够利用之前段的信息,从而实现长期依赖性。在预测的时候,就可以前进一整段,并且可以利用之前段的信息来预测当前的输出。
- 相对位置编码。在普通的transformer中,使用固定的position embedding来表示token之间的顺序关系,但是如果分段处理的话,那么,不同分段的同一位置使用的是同一个position embedding,这显然是不对的。所以,在transformer-xl中,提出新的位置编码方式:相对位置编码。也就是说,会根据单词的相对位置进行编码,而不是像transformer的那样,按照绝对位置进行编码。最后,我们得到的结论是:transformer-xl的长期依赖性比LSTM高出80%(LSTM平均上下文长度200个左右),比transformer高出450%!(transformer平均上下文长度低于50)是不是非常牛逼!
以上就是transformer-xl的大致内容,还是那句话,想要了解全部内容,请读transformer-xl的原始论文,其实只要看懂了transformer的话,transformer-xl决定小菜一碟🤩~接下来正式讲XLNet模型的内容~
语言模型目标:排列语言建模
使用这个方法,不仅可以保留AR模型的优点,同时也允许模型捕获双向信息。从所有的排列中采样一种,然后根据这个排列来分解联合概率成条件概率的乘积,然后加起来。也就是说,只要分解的顺序不一样,我们计算的顺序也就不一样。

模型架构:基于目标感知表征的双流自注意力
这个还没具体细看,大致意思是:在teansformer里面,使用了token embedding+position embedding。但是如果我要预测第3个位置的单词的内容,那么,我不能提前获取到第3个位置的内容向量(token embedding),只能只其位置向量(position embedding),但是这在输入的时候,两个向量就已经混在一起了。所以在XLNet中,就计算了两套注意力,一个只包含它的位置信息,一个要包含它的位置信息与内容信息,以便使用。具体的,等我那天有时间了在具体写吧。。。
ERNIE模型介绍
ERNIE是THU与华为诺亚一起提出来的针对于中文的预训练模型。(这里不得不佩服一波隔壁,NLP做的是真不错,小北要跟上啊!🧐)(发现百度也提出了ERNIE,重名了,而且似乎是百度先提出来的,好吧,那就再看一篇吧😭,似乎百度这篇读的比较顺畅!)
ERNIE模型提出的原因:BERT等模型只是针对字或者word粒度来学习,没有充分利用文本中的词法结构、语法结构以及语义信息去建模。譬如:我要买苹果手机这句话,我们MASK一个词,变成:我要买[MASK]果手机,如果使用BERT模型,我们当然可以预测MASK掉的字是苹。但是BERT模型没有学到苹果手机是一个名词这一信息,那么,如果在未知的文本中,出现了香蕉手机这样的词语,那么,BERT等模型是无法对其进行很好的向量表示的。所以ERNIE模型就诞生了。ERNIE模型的核心思想是:将外部知识整合到预训练模型中,让模型能够学习到词法、语法与语义信息。
在ERNIE1.0中,除了BERT中的基础的masking策略,还提出了基于phrase的masking策略与基于entity的masking策略。在ERNIE中,将多个字组成的phrase与entity当一个单元,统一被mask。这样的话,模型就能够潜在的学会知识的依赖与语义依赖。
在ERNIE2.0中,提出一个很重要的概念:连续学习。也就是,模型顺序训练多个任务,以便在下个任务中记住前一个任务得到的结果,从而可以不断的积累新知识。具体的可以参看论文,这是大致的思想。
ALBERT模型介绍
ALBERT模型是对BERT模型的改进。怎么说呢,感觉ALBERT是一个调参调出来的模型🤪。它的目标是:在不损害模型性能的前提下,尽量减少BERT模型的参数。在ALBERT中,首先分析了BERT中模型的参数来源。在BERT中,参数主要分为两部分:token embedding的参数与attention、FFN层的参数。(以下所用到的图片来源于ALBERT第一作者lanzhenzhong博士的讲解。)

Method1:factorized embedding parametrization
token embedding占参数的20%,attention于FFN层的参数占80%。那么,我们就从这两方面入手。对于token embedding方面,我们可以先将其映射到一个地位i空间,再映射为高维空间。那么为什么可以这么做呢?有两点:1. token embedding一般都是与上下文无关的,而attention层的输出一半都是与上下文有关系的,也就是说,输出层应该包含了更多的信息,所以,输出层的维度应该比token embedding的维度要高才比较合理;2. 如果让E与H相等的话,那么,整个词表的维度是V*H,那么这个词表是相当大的,梯度更新的时候,也会比较稀疏。

当然,这样做会损失信息,但是结果表明,损失的性能并不多,而减少的参数却高达80%以上。
Method2: cross-layer parameter sharing
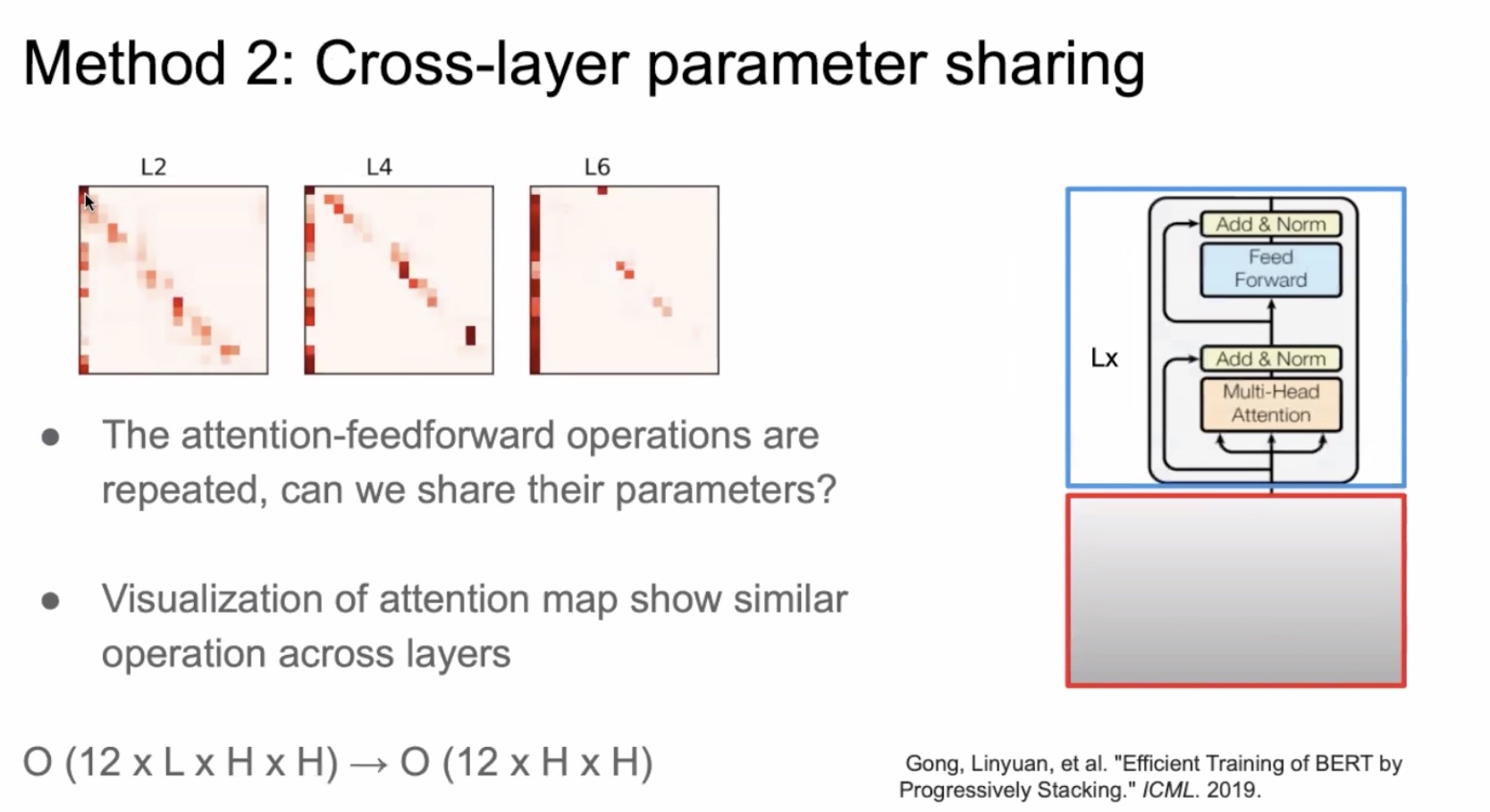
跨层的参数恭喜那个有两种方案:attention模块的参数共享以及FFN层的参数共享。在实验中,作者发现共享FFN的参数是导致参数下降的最主要的原因。
SOP—Sentence Order Prediction
在BERT中,除了MLM之外,还使用了另一种任务——NSP来学习句子之间的关系,但是实现证明:NSP任务对于结果的影响并不大,原因在于:NSP任务实际上是预测两句话是采样于同一个文档中的两个连续的句子(正样本),还是采样于两个不同的文档中的句子(负样本)。所以在ALBERT中,对NSP任务进行了改造,叫做SOP任务。它的思想是:正样本的构建与BERT一样,负样本的构建则是将证样本的句子顺序调换一下。这样的话,就能够专心学习到句子之间的关系,而不会去学习topic。

结果证明,SOP任务比NSP任务表现更加良好。

去掉Dropout
dropout在防止过拟合上有显著效果,但是实际上MLM很难过拟合,去掉dropout,由于可以腾出很多临时变量占用的内存而使得内存上有所提升。
总结,ALBERT模型的优势如下:
- ALBERT模型通过两种技术,降低了参数的数量;
- 通过重新设计NSP任务,得到了SOP任务,最终改善了模型性能;
- 减少参数,同时也就提高了模型的capacity,即可以通过将网络变深变宽,提升模型。
预训练模型总结
整个预训练模型可分为两类:feature based approach与fine-tuning approach。前者的代表性模型就是ELMo,后者的代表性模型就是GPT与BERT。
整个语言模型有两种:AR与AE。AR语言模型指的是使用上下文单词来预测下一个单词的模型。上下文单词被限制了方向:前向或者后向。代表性模型有:ELMo、GPT、GPT2、XLNet。AE模型就是从损坏的数据中重建原始数据。也就是,我们使用MASK标记来替换原单词,然后使用上下文来预测MASK掉的单词。代表性模型有:BERT、ALBERT。
- 另外,说说我的看法吧,feature-based的预训练模型基本上大势已去,从word2vec、fasttext、ELMo等等;现在,pre-train+fine-tune两段式的预训练模型越来越受到欢迎,从GPT、BERT、XLNet、ALBERT、T5等等。未来NLP真有可能像cv那样,一个模型统一天下。我们只需要去改进模型所使用的特征抽取器就可以了。从RNN、CNN到transformer,特征抽取的能力越来越强,未来,我们只要不断改进transformer或者提出比transformer更好的模型,就能够大大提升模型在各项NLP任务上的表现。对于我们NLPer来说,是一件好事吧,因为不需要再去学很多千奇百怪的trick,只要去提升基础模型的能力,就可以得到很大的提高。
参考文献
- 《Deep contextualized word representations》(ELMo)
- https://blog.csdn.net/Magical_Bubble/article/details/89160032 (ELMo)
- 《Improving Language Understanding by Generative Pre-Training》(GPT)
- https://blog.csdn.net/Magical_Bubble/article/details/89497002 (GPT)
- 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
- https://blog.csdn.net/Magical_Bubble/article/details/89514057. (BERT)
- 《XLNet: Generalized Autoregressive Pretraining for Language Understanding》
- https://blog.csdn.net/weixin_37947156/article/details/93035607 (XLNet)
- https://blog.csdn.net/u012526436/article/details/93196139 (XLNet)
- 《ALBERT: A LITE BERT FOR SELF—SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》
- 《ERNIE: Enhanced Representation through Knowledge Integration》
- https://blog.csdn.net/PaddlePaddle/article/details/102713947 (ERNIE)

