词向量是NLP中最为重要的概念。词向量的好坏直接影响到下游任务的效果。然而,即便在ELMo、BERT、ALBERT等预训练模型大行其道的当今,word2vec、GloVe、fastText仍然是目前最为流行的词向量训练方式。因此,本篇博客将具体讲解这三种词向量训练的原理,并使用gensim来展示如何使用这些词向量模型,以便得到我们想要的词向量。
注意:本篇博客尽可能讲解清楚三种词向量训练模型的原理,但是很多细节的部分,需要大家自行去了解,比如huffman树的原理、softmax的原理等等。如若不尽意,可参考我在参考文献中例举的原始论文~
word2vec模型介绍
word2vec模型其中有两种训练方式:skip-gram与CBOW,此外,还有两种加速训练的trick:hierarchical sofmtmax与negative sampling。所以,word2vec其实有4种方法。细节见细节、skip-gram详细介绍
skip-gram模型
skip-gram模型是给定目标词,来预测其上下文。由于skip-gram模型是一个简单的神经网络模型。我们知道使用神经网络来训练的过程分为:
- 确定训练数据$(X,Y)$
- 确定网络架构
- 确定损失函数
- 确定优化器、迭代次数
- 存储网络
确定训练数据
假设语料库只有一句话:The quick brown fox jumps over the lazy dog。所以总共只有8个词。在skip-gram中,训练数据的形式其实非常简单,其实就是使用n-gram的方法生成词对。譬如
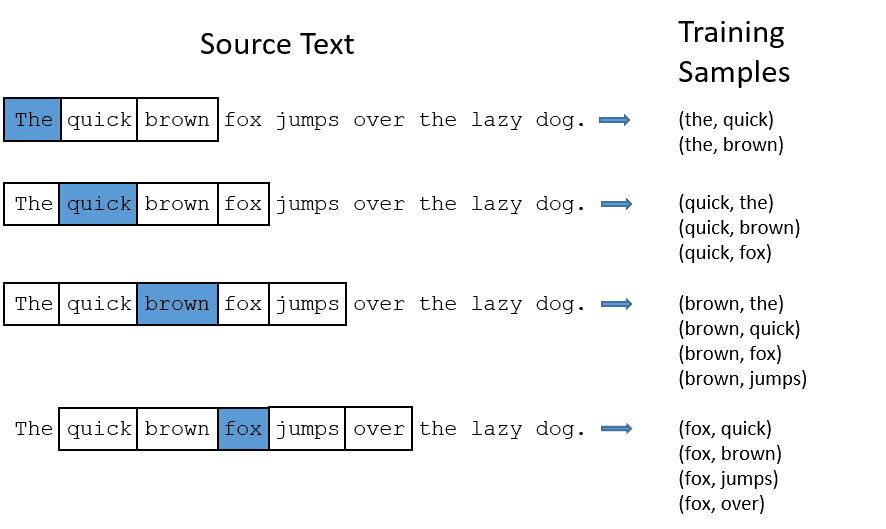
上图的窗口大小是2,左右各取2个词。实际上窗口大小为5时比较好的,这里只是为了展示。在得到训练数据后,我们将其用one-hot编码后,就可以输入网络了。譬如:(the, quick)单词对就表示$[(1,0,0,0,0,0,0,0),(0,1,0,0,0,0,0,0)]$,输入网络。当然,对target单词也是需要进行抽样的。链接:对target抽样
确定网络架构
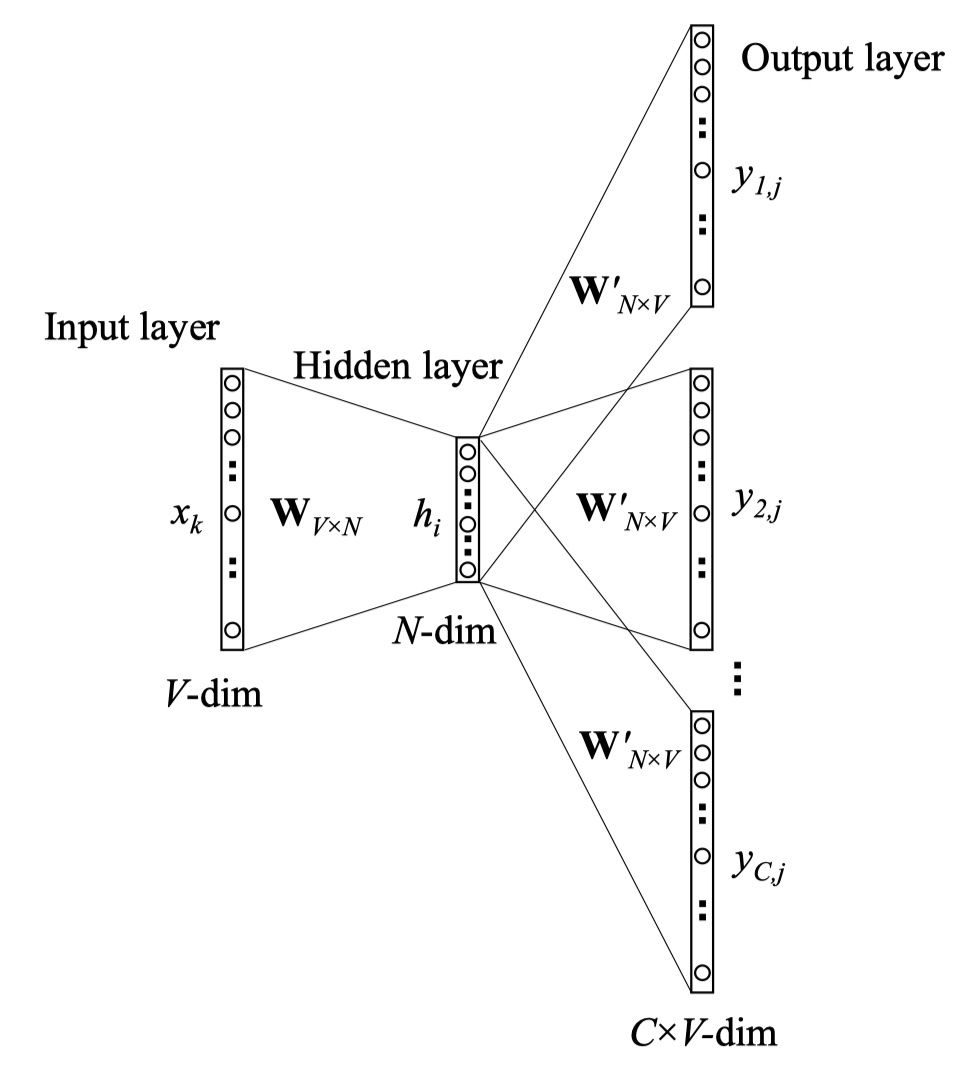
上面就是skip-gram模型的架构,输入是一个单词的vector,输出是softmax后的概率分布,每一个概率值对应词汇表中的一个单词,表示词汇表中的单词出现在输入单词的上下文的概率。中间只有一个线性的hidden layer。还是紧接着我们的例子,词汇表有8个单词,所以,输入时8维的vector,输出也应该是一个8维的vector。而hidden layer的维度则是我们想要得到的词向量的维度,比如说我们使用3个hidden units,那么,权重矩阵就是8*3维的矩阵。(实际上google推荐使用300维。)注意:在网络中,其实有两个权重矩阵,我们只需要选择其中一个就可以了,因为它们互为转置。我们最后需要的额就是权重矩阵,并不需要输出层的结果。
确定损失函数
由于在输出层使用softmax函数,那么很自然地,损失函数就是交叉熵函数。即:
我们可以发现,使用sotfmax,需要计算词汇表中所有词汇的和,而一般的词汇表数目在几十万到几百万不止,那么,这个计算代价是非常昂贵的,所以,我们需要使用一些技巧来加速训练。
Negative sampling
Negative sampling主要就是解决网络难以训练的问题。在skip-gram模型中,我们使用SGD来训练网络,这需要计算词汇表中所有单词的和,当词汇表很大的时候,这是非常难的。那么negative sampling,就是在在输出层中,我们抽取几个应该为0的维度,再加上为1的维度,来进行训练。这样就能大大加快训练速度。
譬如说,我们的词汇表为10000,hidden layer的维度300,我们nagative sampling的维度个数为5个,那么我们需要更新的维度就是6个,所以我们需要更新的权重系数为300*6=1800,这是输出层系数的0.06%。注意:在隐藏层的权重10000*300=3000000是必须需要训练的。这样一来,我们就将softmax问题转换为V个logistic二分类问题,并且我们每次只更新其中K个负样本与一个正样本的参数,从而大大降低了计算成本。
但是问题来了:我们应该怎么抽取这5个应该为0的维度呢?具体做法是:根据单词在语料库中出现的次数来决定。出现次数越多,那么约有可能被抽中。公司如下:
其中,$P(w_i)$表示单词$w_i$被抽中的概率;$f(w_i)$表示单词$w_i$在语料库中出现的次数。
hierarchical softmax
所谓的hierarchical softmax,实际上就是采用Huffman树。huffman树的叶子结点就是词汇表中的单词,从根节点到叶子结点的路径就表示单词的概率。这样一样,我们就不需要对所有单词的得分进行求和,就大大降低了计算成本。注意:在构造huffman树的时候,常用的词的深度会更小一些,即更靠近根节点;而不常用的词会更深一点。
CBOW模型
CBOW模型与skip-gram的训练方式相反。它是给定目标词上下文,然后来预测目标词。
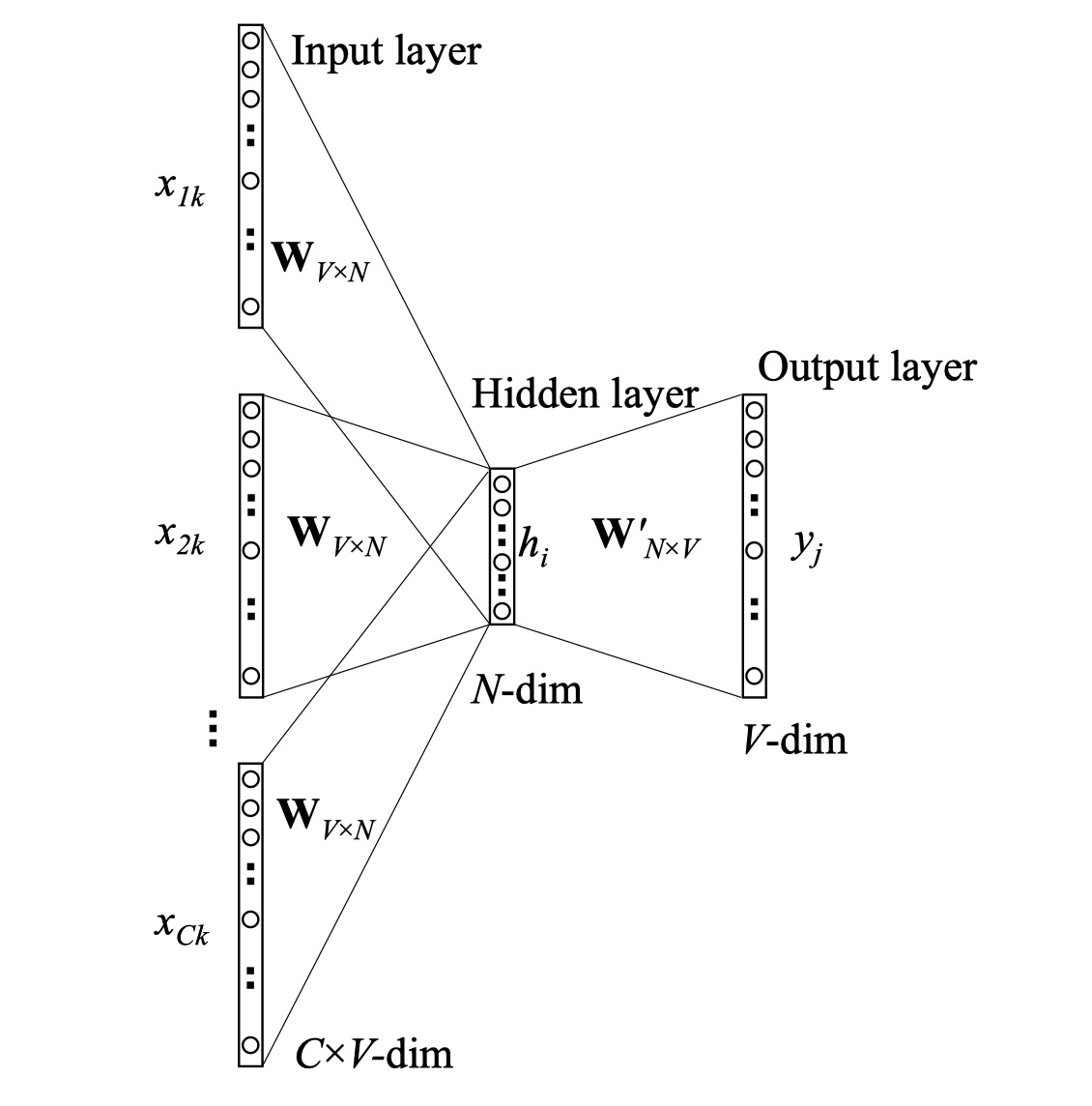
其中网络架构与skip-gram模型非常的类似。但是需要注意输入。CBOW模型的输入是多个单词的one-hot vector的和,而隐藏层需要对其求平均。如下:
其中,$x_1,x_2,..,x_C$是输入的vector,$h$是隐藏层的输出,$C$是输入的单词的数目。
其余与skip-gram模型一样,输出层也是使用了softmax。此外,negative sampling与hierarchical softmax这两种trick也都可以用在CBOW模型中。
GloVe模型
GloVe模型出自于另一篇论文《Global Vectors for Word Representation》。强力推荐大家去读一读,这是一篇非常好懂的论文!🤩
GloVe模型的目标是:得到单词的词向量,让其尽可能的包含语义与语法信息。输入是语料库(没错,不需要去构建训练集),输出是词向量。GloVe模型的思路是:从语料库中统计共现矩阵,然后根据共现矩阵与GloVe模型来学习词向量。
统计共现矩阵
我们记共现矩阵为:$X=[X_{ij}]_{N\times N}$。其中,$X_{ij}$表示单词$j$在单词$i$的上下文中出现的次数,$N$表示词汇表中的单词数目。至于如何构建的,其实就是根据统计窗口,遍历整个语料库,来进行统计。接下来,我们再引入一些符号:
其中,$P_{ij}$表示单词$j$在单词$i$的上下文出现的概率,$ratio_{i,j,k}$表示单词$i$与单词$k$的相关度,以及单词$j$与单词$k$的相关度的比值。为什么要有这个东西?因为,如果我们直接看$P_{ij}$来表示单词$i$与单词$j$的之间的相关度的话,其实是不够的,因为这很有可能受语料库的影响。所以,需要需要它们之间的比值。我们可以发现$ratio_{i,j,k}$有如下性质:
- 当$i$与$k$相关,$j$与$k$不相关的时候,那么$ratio_{i,j,k}$的值会非常的大;
- 当$i$与$k$相关,$j$与$k$相关的时候,那么$ratio_{i,j,k}$的值会趋于1;
- 当$i$与$k$不相关,$j$与$k$相关的时候,那么$ratio_{i,j,k}$的值会非常的小;
- 当$i$与$k$不相关,$j$与$k$不相关的时候,那么$ratio_{i.j.k}$的值会趋于1。
那么,GloVe模型的想法是:假设我们现在以及得到了单词的词向量$v_i,v_j,v_k$,那么,如果说我们通过某个函数,能够求得$ratio_{i,j,k}$的话,那么就说我们的词向量与共现矩阵是一致的,也就是说我们的的词向量包含了共现矩阵中的信息。
学习词向量
假设我们的函数为:$g(v_i,v_j,v_k)$,那么,我们的目标就是:$g(v_i,v_j,v_k)=\frac {P_{ik}}{P_{jk}}$。所以,很自然地,我们可以想到:
只要让这个式子最小,我们就能求出所有的词向量。但是,这个式子存在一个问题:那就是这个计算复杂度太高了,为:$O(N\times N\times N)$。所以,我们必须想办法减小复杂度。
由于我们想衡量$v_i$与$v_j$的相似度,那么,我们引进$v_i-v_j$这个是很自然的;此外,由于$ratio_{i,j,k}$是一个标量,那么我们引入内积也是很自然的,$(v_i-v_j)^Tv_k$,最后我们在外面加一层$exp$,从而能够简化运算。所以我们的函数可以变为如下式子:
由于我们的目标是:$g(v_i,v_j,v_k)=\frac {P_{ik}}{P_{jk}}$,将g函数带入,得到:
所以,我们只要令:$P_{ik}=exp(v_i^Tv_k),P_{jk}=exp(v_j^Tv_k)$,即可。我们再将这两个式子统一一下,如下:
我们可以看看最后的化简的式子,右边是对称的:$v_i^Tv_j=v_j^Tv_i$;而左边是不对称的。所以,我们需要再化简一下:
所以,我们的最优化式子可以化简如下:
此外,我们还想让出现频率高的词对有更高的权重,所以,我们需要再加一个权重项,最终如下:
其中,权重项函数为:
以上就是GloVe模型的全部内容~
GloVe模型与word2vec的对比:
- GloVe模型最大的优点是利用了全局的信息,而word2vec中,尤其是skip-gram,只利用了目标词周边的一小部分上下文。尤其当引入negative sampling训练的时候,丧失了词与词之间的关系信息。
- GloVe模型能够加快模型训练速度,并且能够控制词的相对权重。
fastText模型
fastText是Facebook在2016年所提出的方法。其实,整个模型架构并没有特别创新的地方,和CBOW模型非常地像。其创新的地方在于:子词嵌入的引入。(论文写的太简洁了,导致看了很久😫)
模型架构
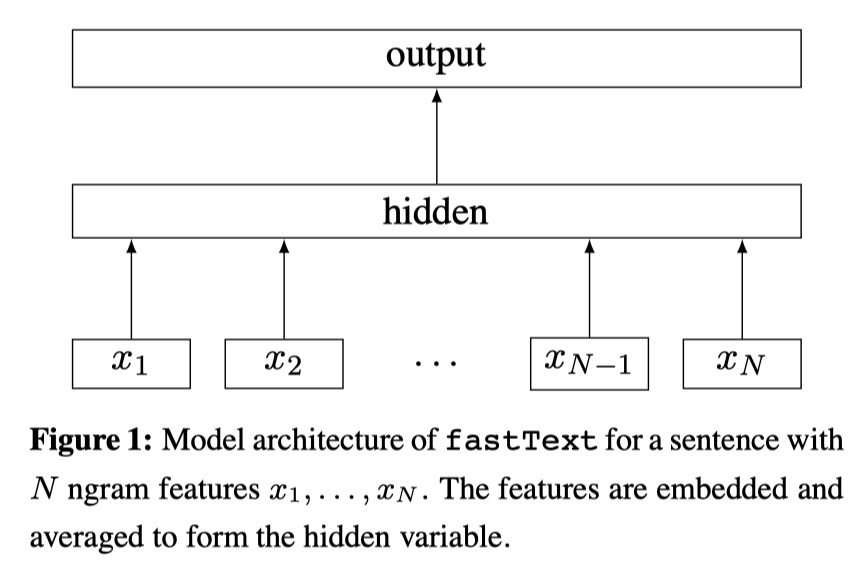
整个模型架构与CBOW模型非常的类似。输入是一段序列,输出是这段序列的标签类别。中间层仍然是线性的。输出层仍然是softmax。并且在训练的时候,使用hierarchical softmax来加速训练。
子词嵌入
这个才是fasttext模型真正创新的地方。在word2vec或者其他的模型中,相似形态的单词由不同的向量来表示。譬如,老师们,老师。但是,老师们、老师这两个单词,意思其实非常的相近,不应该被编码成不同的向量。所以,在fasttext中,引入了子词嵌入。具体做法是:我们将Apples,使用trigram,得到:<ap,app,ppl,ple,les,es>,在训练过程中,每一个n-gram都会由一个向量来表示,我们可以用这6个trigram的叠加来表示Apples这个单词。序列中所有单词的向量以及n-gram向量同时相加平均,作为训练的输入。譬如:一段序列中3个词,$w_1,w_2,w_3$表示3个词的向量,$w_{12},w_{23}$表示bigram特征的向量。那么hidden layer的输出是:$h=\frac 15W^T(w_1+w_2+w_3+w_{12}+w_{23})$。
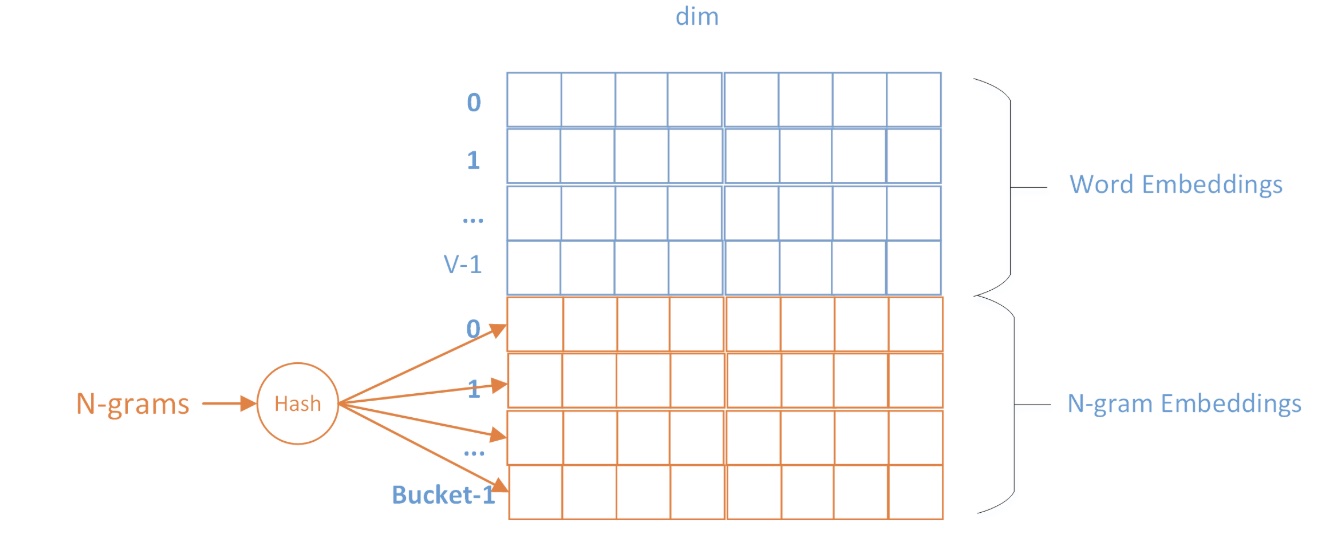
这里有一个问题需要注意:在实际中,我们往往会使用多种n-gram,所以得到的n-gram结果比单词数目多得多。所以来存储这么多的n-gram是不太现实的。所以,我们的做法是:将所有的n-gram映射到一张hash桶中,这样的话,就能够实现n-gram的vector共享。
子词嵌入的好处:对低频词汇的词向量训练效果会更好,因为它可以和其他词共享n-gram;此外,对于UNK,我们仍然可以构建它们的字符级n-gram向量。
理论部分就到这里,我们再回顾一下:fastText到底快在哪里?
- 使用了hierarchical softmax,这本来就是对普通的softmax很大的加速了;
- 在hierarchical softmax中,使用Huffman树来构建,对于文本分类而言,其分类树远远小于skip-gram模型中的词表数目,所以,相比于skip-gram模型,更加快速;
- 一些trick,譬如使用提前算好exp的值。(在使用logisitic进行二分类的时候使用。)
实战
在实战部分,我主要是使用gensim。当然,如果有兴趣的小伙伴们,可以去看它们的源码,这个在github上都能够搜的到。
fasttext
1 | from gensim.models import FastText |
参考文献
1 《word2vec Parameter Learning Explained》,Xin Rong(强推, 比原始论文详细的多!)
2 《GloVe: Global Vectors for Word Representation》
3 《Bag of Tricks for Efficient Text Classification》

