FM(Factorization Machines)模型与FFM(Field-aware Factorization Machines)模型,是在推荐系统中常用的两个模型。其实我本不想去写这两个模型的,毕竟我并不是搞推荐系统的,而且NLP方面我还没看的论文太多了😭,但是最近突然发现在看有关LR模型的题的时候,讲到了这两个模型,所以记录一下。
FM模型介绍
FM模型要解决的是:稀疏数据的特征组合问题。在训练样本中,我们往往会碰到样本的特征中会有很多的categorical feature。譬如:国家,性别,名字等等。这些数据往往不能直接使用,我们需要将其转换为数值型数据才能使用。处理categorical feature的一般方法是:one-hot编码(当然还有其他的方式,比如说在catBoost中介绍了好几种方法)。具体来说如下:

上图中,Clicked?是label,Country、Day、Ad_type这三个都是feature,并且这三个feature都是categorical feature。我们需要对其进行one-hot编码,结果如下:

转换后,特征就能使用了。但是,如果我们仔细观察一下,就会发现:使用one-hot编码后,特征数量增多了,并且大部分的特征值都是0,这就是数据稀疏问题。数据稀疏是不好的,因为这会导致模型难以训练,梯度下降的特别慢。
此外,对于线性模型或者在LR模型中,我们其实都是假设特征之间是相互独立的,但这是不对的。因为在具体的情况中,特征之间应该是有关系。譬如:<厨房,米饭>这样两个特征之间应该会有一定的相关性。所以我们对特征之间进行组合,对于模型的表达能力来说,是有好处的。
那么,如何对特征进行组合?
多项式模型是包含特征组合最为直观的模型。我们是用$x_ix_j$来表示特征$x_i$与特征$x_j$的组合,只有当$x_ix_j$不等于0的时候,组合特征才有意义。在FM模型,一般是使用二阶的多项式模型,如下:
其中,$n$表示特征的数量。我们可以看到,公式的前半部分就是LR模型的线性组合,后半部分就是组合特征,也叫做交叉项。所以,FM模型的表达能力比LR模型是要强的,并且当$w_{ij}$为0的时候,FM模型就退化成LR模型了。(当然,如果要用于二分类的话,需要在多项式模型之上用上sigmoid函数)。我们需要训练的参数是:$w_0,w_i,w_{ij}$。
但是如果直接训练的话,参数$w_{ij}$是很难训练的。因为其参数规模为:$O(n^2)$,当$n$很大的时候,那么计算复杂度非常的大。而且,训练$w_{ij}$需要大量的满足$x_ix_j$非零的样本,而现实生活中样本往往都是稀疏的,所以满足要求的样本就很少,所以训练$w_{ij}$是很难的。
那么,如何训练参数$w_{ij}$呢?
在FM模型中,它的解决办法是:为每一个特征引入一个隐向量$v_i=(v_{i1},v_{i2},v_{i3},…,v_{ik})^T$。 其中,$k$是隐向量的维度,也是超参数,需要我们去调整。

所以,我们化简之后发现,我们对于参数$w_{ij}$的训练,只需要知道样本那些不为0的特征就可以了,计算复杂度为:$O(kn)$。所以,这样一来,我们就可以在线性时间复杂度完成FM模型。所以总结一下:FM模型的优势有两点:1.能够用来解决数据稀疏的问题;2.具有线性的计算复杂度。
FFM模型介绍
FFM模型是FM模型的一个特例,它引入了filed这个概念。什么意思呢?如下:

上面有4个特征,其中$User、Movie、Genre$这三个特征是categorical feature。我们将其使用one-hot编码之后,可以得到5个特征,4个 field。如下:
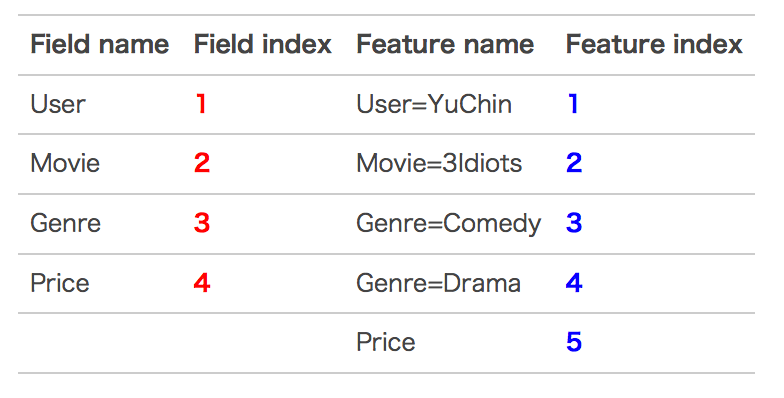
所以使用FFM模型之后,其组合特征就有10个。下面具体给出模型:
其中,$f_j$表示第j个特征属于的filed。这个模型的二次项参数是$nkf$。预测复杂度为$O(nk^2)$。
在FFM模型中,将问题定义为分类问题的时候,其损失函数是logsitic loss,但是与平常的logistic loss有所不同,如下:
这样看是不是很奇怪?和咱们平时看到的LR模型的loss不太一样?其实这里我们都忽略了一个条件:平时我们孙推导的LR loss的标签是0与1,而这里的loss是-1与1。其实和平时我们推导的方式是一样的。推导过程如下:

之后,我们就可以使用SGD来进行优化,这就不介绍了,相信大家都很熟悉了。
FM模型、LR模型、SVM模型的联系
- FM模型是LR模型的扩展,在LR模型的基础上,增加了交叉项,这就让FM模型的表达能力至少要超过LR模型,也即是它能处理更加复杂的问题;同时它来能以与LR模型同样的时间复杂度来训练模型,这使的FM模型要比LR模型要更加优越。
- FM模型适合处理数据稀疏问题,这比使用多项式核的SVM要更加好,因为FM模型可以在原始形式下进行训练,而SVM模型需要转换成对偶形式才能训练;此外,FM模型的预测是与训练样本独立的,而SVM则与训练样本有关(支持向量)。
- LR模型与SVM模型的很重要的区别在于:其使用的损失函数。LR模型使用的是交叉熵 cross entropy,而SVM模型使用的合页损失hinge loss。

