最大熵模型(MaxEntropy),是机器学习中一个非常重要的分类模型,其是最大熵思想应用到分类问题的结果。本篇博客将对最大熵模型的原理进行详细的讲解,并采用python实现对最大熵模型进行实现(scikit-learn库没有关于最大熵的类库)。此外,还会对比讲解其logistic回归的区别,并实现logistic回归模型(python与scikit-learn库)。
最大熵模型概述
关于使用最大熵模型,我们最终要求的是:给定实例的特征向量$x$,使得条件概率$p(y|x)$最大的$y$。但是它与朴素贝叶斯不一样,朴素贝叶斯是通过求联合概率,然后根据贝叶斯定理求得$p(y|x)$;而最大熵模型是直接求$p(y|x)$。它所使用的思想就是:最大熵思想。所谓的最大熵思想就是:当我们要求一个条件概率分布的时候,如果我们没有任何的先验知识的时候,那么我们应该选熵最大的分布;如果我们已经有了一些先验知识,那么我们应该选满足这些先验知识的情况下,熵最大的分布。下面我将介绍最大熵模型如何贯彻最大熵思想的。
最大熵模型
首先我们来看一下熵的概念,如果离散随机变量的概率分布是$P(x)$,那么它的熵如下:
其中,$x$表示随机变量$X$的取值。那么对于条件概率分布$P(y|x)$,它的熵,我们可以套用公式,如下:
但是这样还不够。因为我们要保证在所有情况下,熵都是最大的,所以需要引入$\tilde P(x)$。如下:
关于$\tilde P(x)$,我们可以这么理解:由于我们要求的是最大熵,也就是说,在满足先验知识的基础上,总的熵是最大的。由于对于每一个$x$,都会对应一个概率分布$P(y|x)$,也就会对应一个熵。所以,最大化熵,也就是最大化这些所有的熵的和。此外,我们还需要体现出每一个概率分布的熵的重要性,我们需要对其进行加权求和,$\tilde P(x)$就相当于权重。
接下来,我们还需要定义一些约束条件。因为训练集就相当于是先验知识,最大熵就是满足先验知识的基础上的熵最大的条件概率分布。我们定义特征函数$f_i(x,y)$,如下:
其中$i$表示第$i$个特征,$i=1,2,3,…,n$。那么$f(x,y)$关于$\tilde P(x,y)$的期望如下:
如果说我们的模型正确的话,那么$P(y|x)=\tilde P(y|x)$。所以这就是一种约束,约束我们必须要去得到正确的模型!
最大熵模型总结如下:
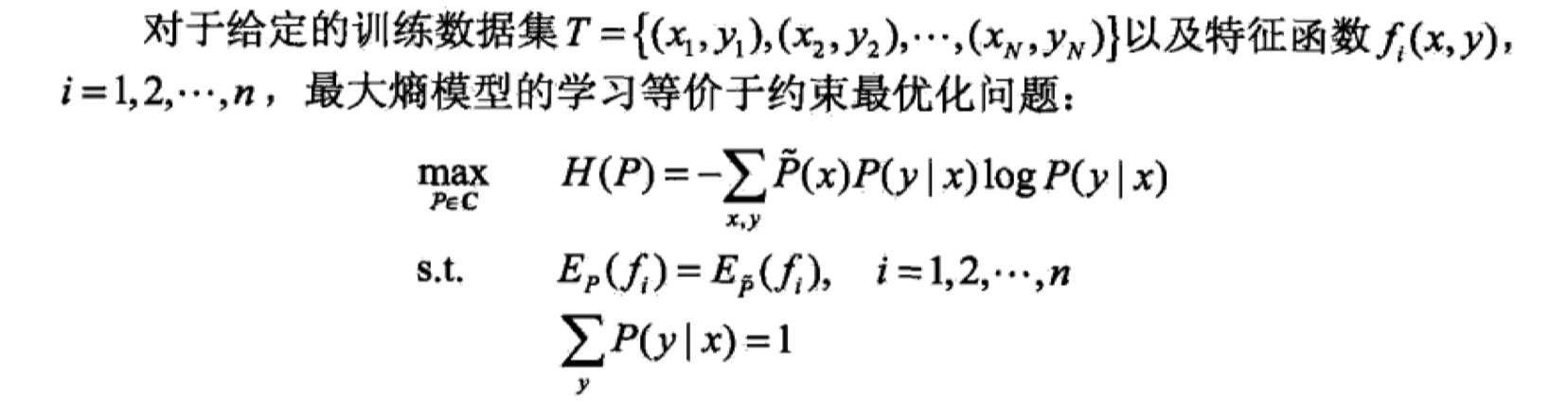
由于我们习惯最小化问题,所以:
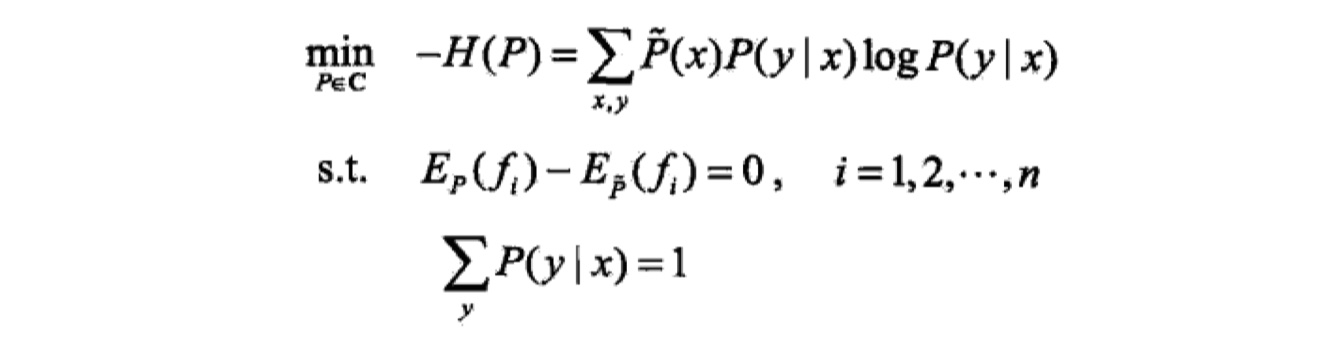
最大熵模型的学习
我们首先将最大熵模型摘抄下来:
那么,对于有约束的最优化问题,很自然地就想到拉格朗日乘子法,所以我们可以写成如下形式:

所以,对于原始问题,我们的目标是:$min_Pmax_wL(P,w)$;对于对偶问题,我们的目标就是:$max_wmin_PL(P,w)$。我们首先求$min_PL(P,w)$,也就是求$\frac {\partial L}{\partial P}=0$,假设我们得到的最优解记为:$P_w(y|x)$,最后结果是:

在求得了$P_w(y|x)$之后,我们就只需要求$max_w(P_w,w)$即可。将$P_w$ 带入到原来的拉格朗日函数,化简,然后求导,即:$\frac {\partial L(P_w,w)}{\partial w}=0$。但是我们会发现,化简后太难求了,所以我们就采用另外一种方式,就是将对偶函数的最大化转化为最大熵模型的极大似然估计。下面是推导出最大熵模型的极大似然估计过程(《统计学习方法》中并没有给出推导过程):
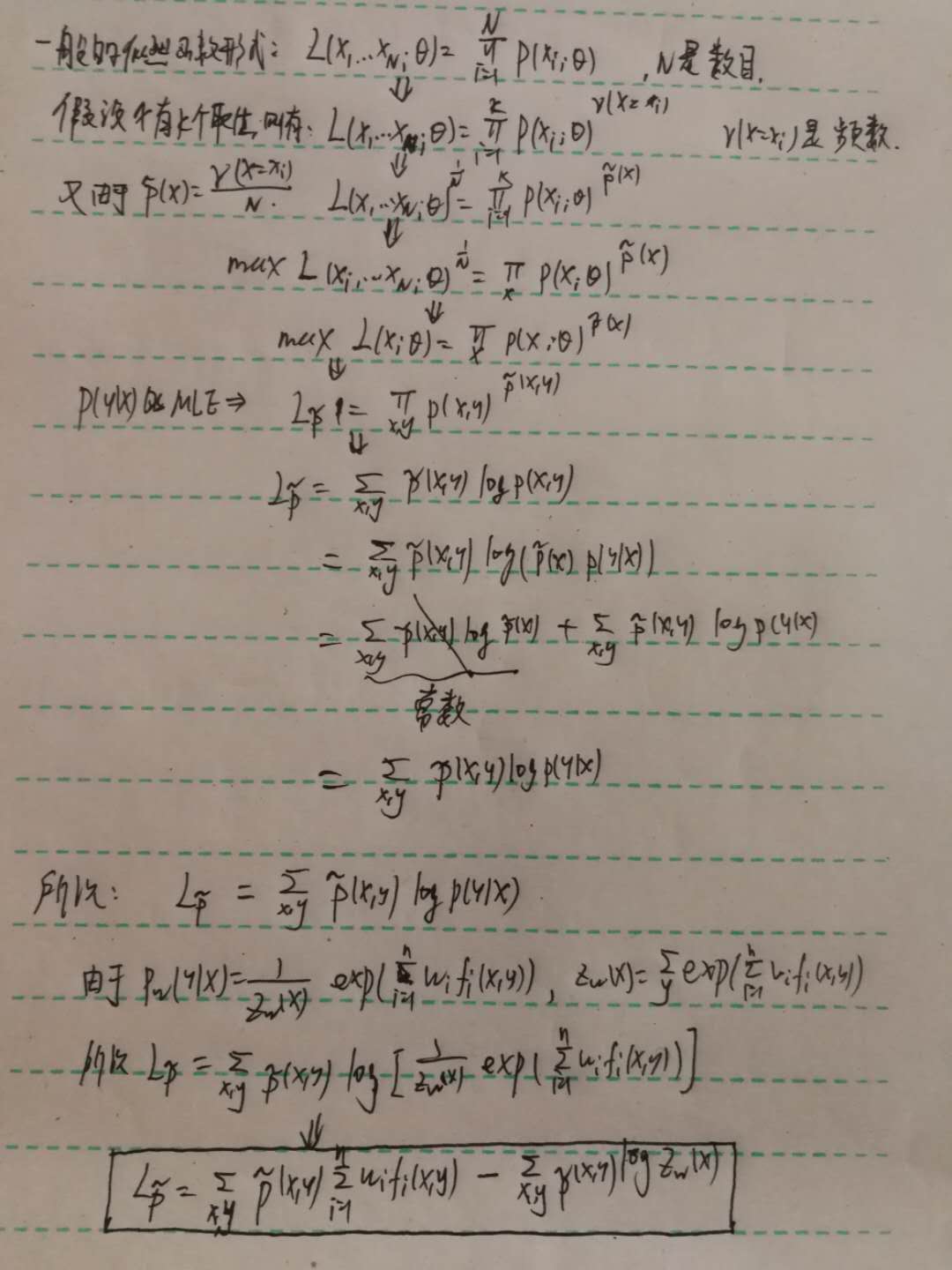
此外,可以证明化简后的对偶问题与最大熵模型的对数似然函数是一样的,感兴趣的读者可以自行证明一下。
最大熵模型学习的优化算法
现在,我们整理一下,我们已经得到的东西:最大熵模型、模型的对数似然函数。那么,接下来,我们只要对对数似然函数求导,得出参数$w$的值,就可以得到最大熵模型$P_w(y|x)$。由于最大化对数似然函数是一个凸优化问题,我们可以使用牛顿法、IIS等算法求解。在这里主要介绍IIS(改进的迭代程度法)。
IIS的思想是:如果我们能找到一种参数更新方法:$r:w->w+\delta$,使得对数似然函数能够增大,那么,我们就可以重复使用改方法,从而得到最优解。我们可以首先计算似然函数的改变量:
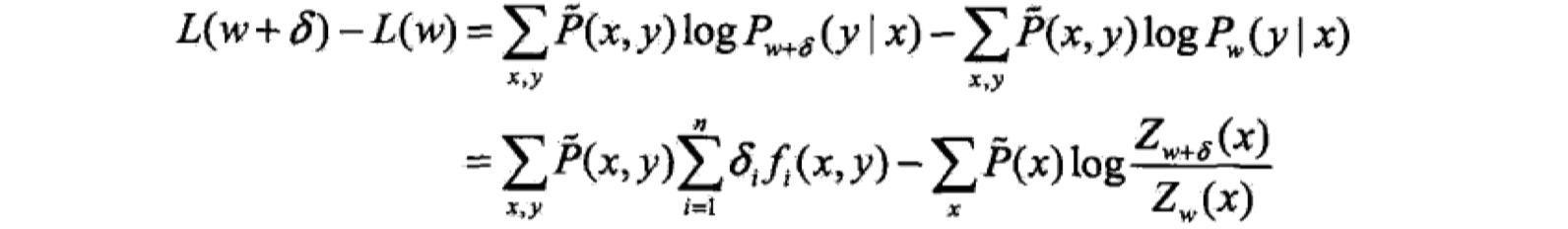
根据不等式:$-loga>=1-a$,那么将上式进行放缩,得到如下式子:
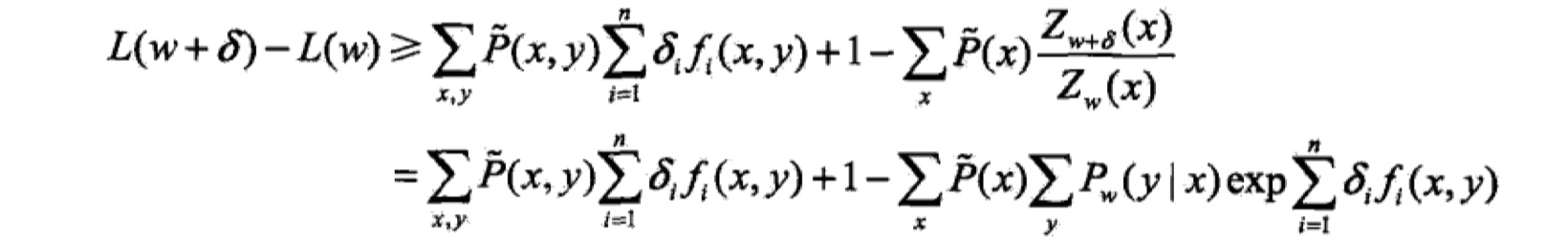
我们记右边的式子为:$A(\delta|w)$。这就是似然函数改变量的下界。也就是说,只要我们找到合适的$\delta$,不断提高下界,就能够使得似然函数不断增大。但是IIS算法一次只能优化一个参数$w_i$,所以我们需要再对下界进行放缩(这其中用到了Jensen不等式)。如下:
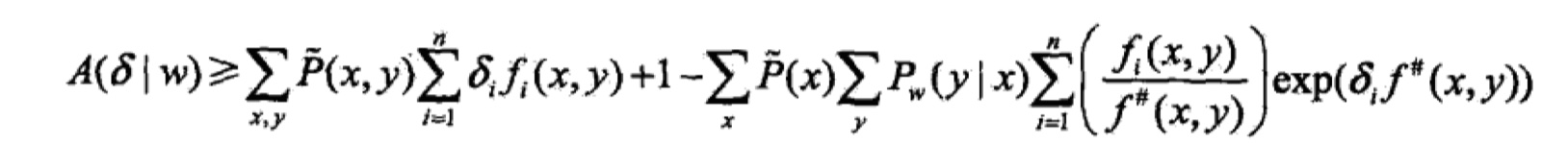
记右边的式子为$B(\delta|w)$,接下来我们只要对$B(\delta|w$求导,就可以得到最后的结果了。总结如下:

到此,最大熵模型的理论部分求讲解完了~
最大熵模型与LR模型的区别与联系
由于最大熵模型与LR模型总是被放在一起讲,所以这里就简单概括一下两者的区别与联系。最大熵模型与logistic回归模型最大的相似之处在于:最后都是求条件概率分布关于训练集的对数似然函数的最大化,区别在于:条件概率分布的形式不同,LR模型的条件概率分布就是sigmoid函数。具体关于LR模型的细节,我就不讲了,因为实在太简单了,我就放一张LR模型的对数似然函数的最大化的推导过程吧~
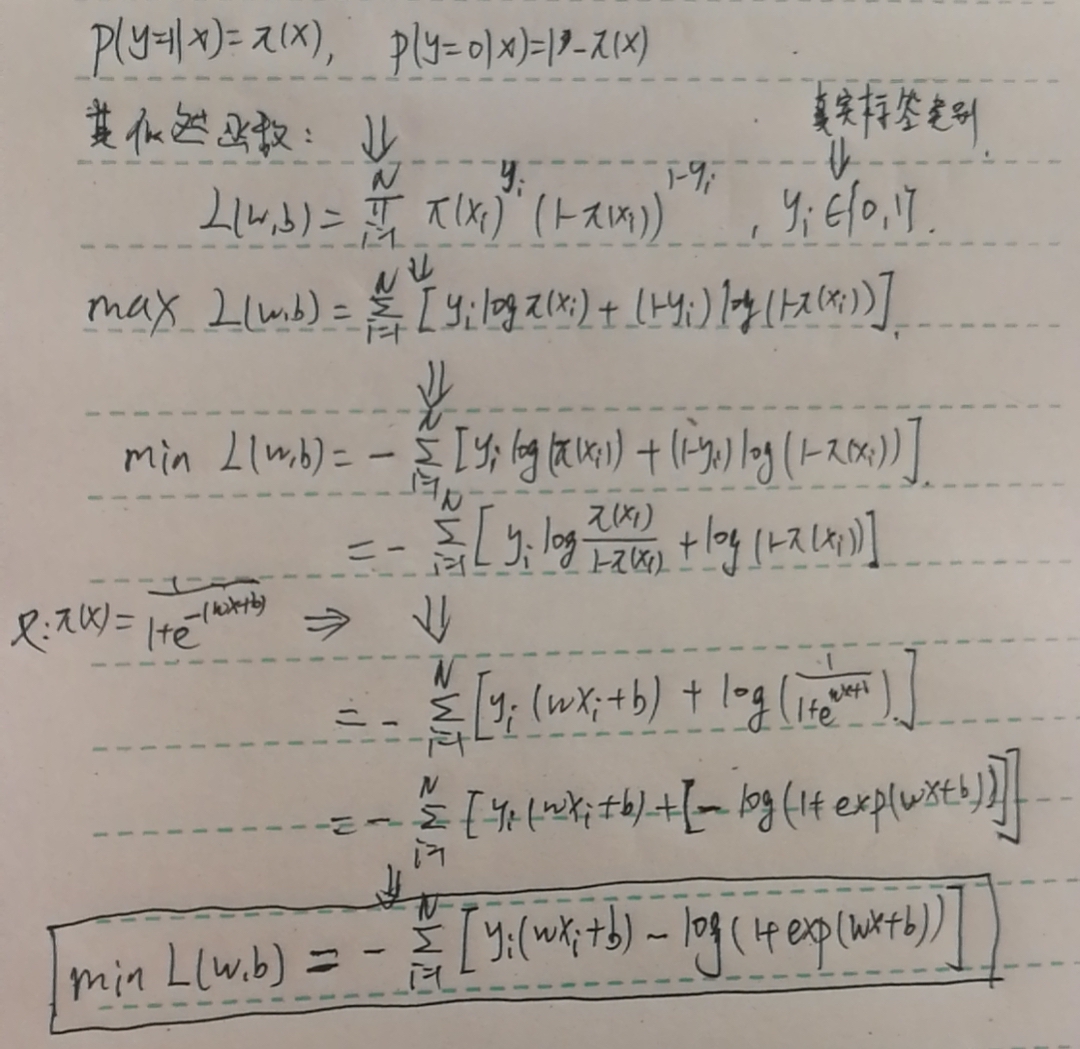
最大熵模型的实现
把模型实现一遍才算是真正的吃透了这个模型呀。在这里,我采取了python来实现最大熵模型与logistic回归模型。我的github里面可以下在到所有的代码,欢迎访问我的github,也欢迎大家star和fork。附上GitHub地址: 《统计学习方法》及常规机器学习模型实现。具体代码如下:
logistic回归模型python实现
1 | # coding:utf-8 |
logistic回归模型sckit-learn实现
1 | # coding:utf-8 |
最大熵模型的实现
此实现借用于pkudodo的实现,因为实在是写的太好了!
1 | #coding:utf-8 |

