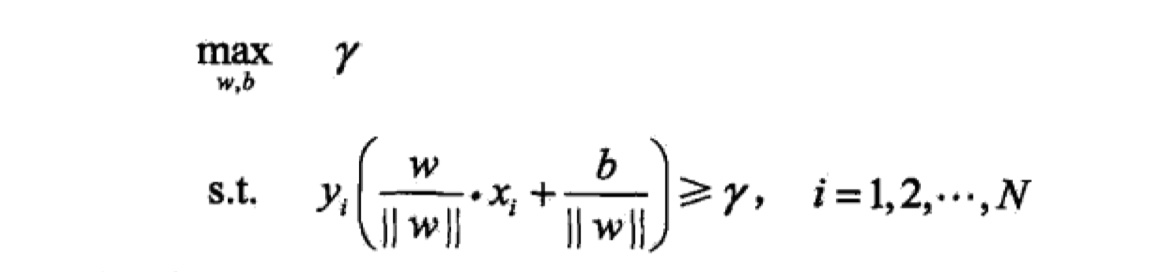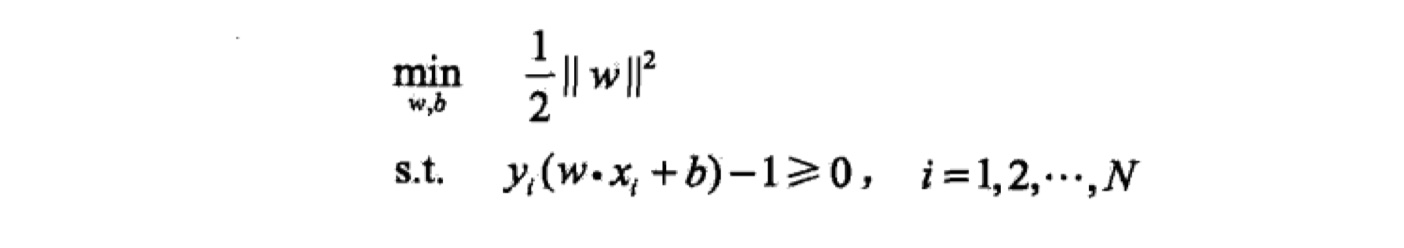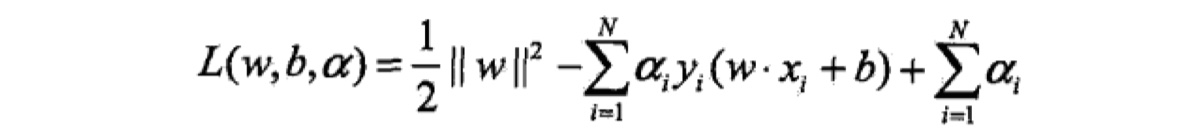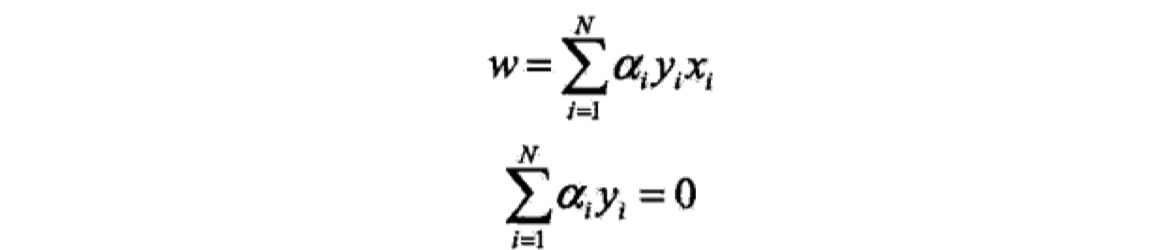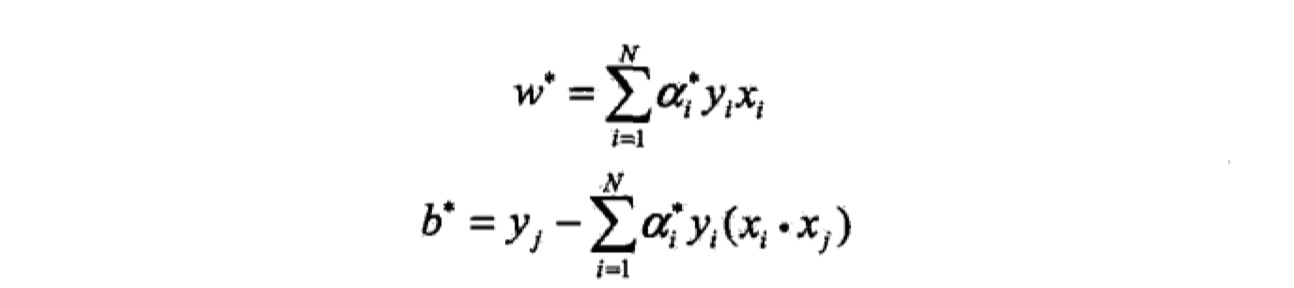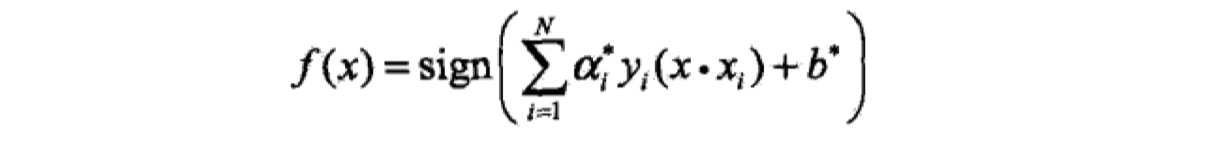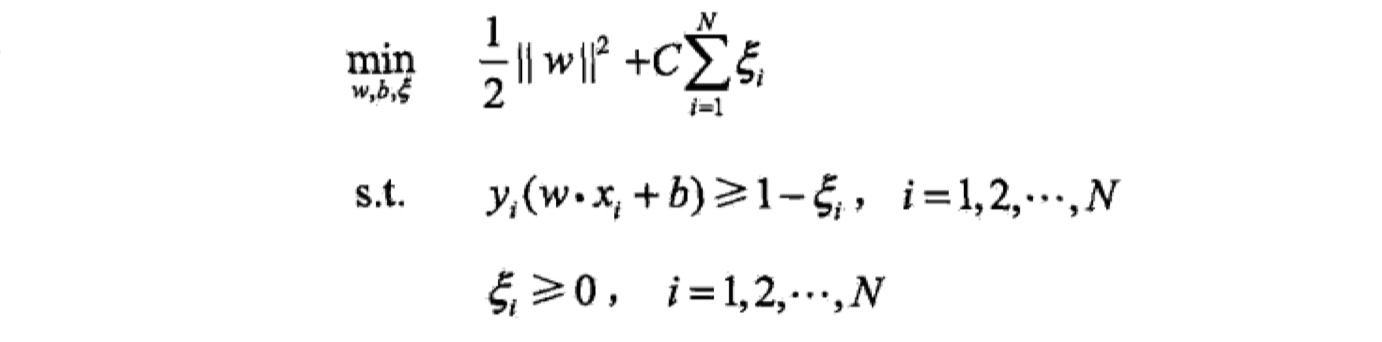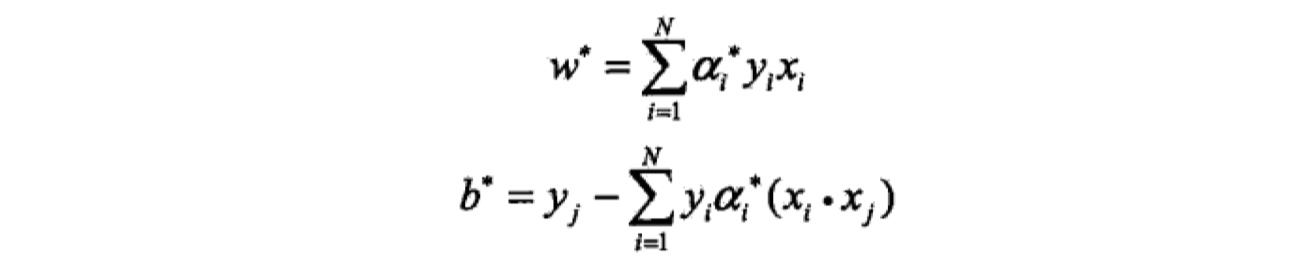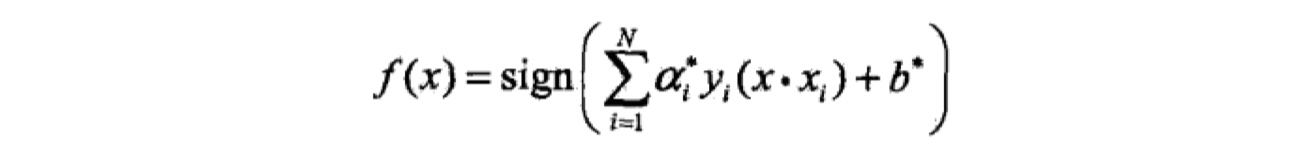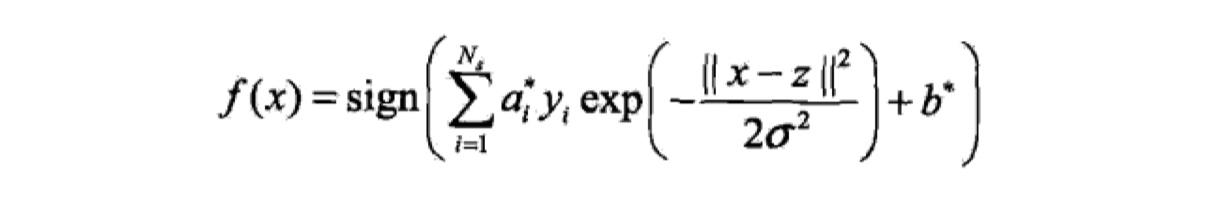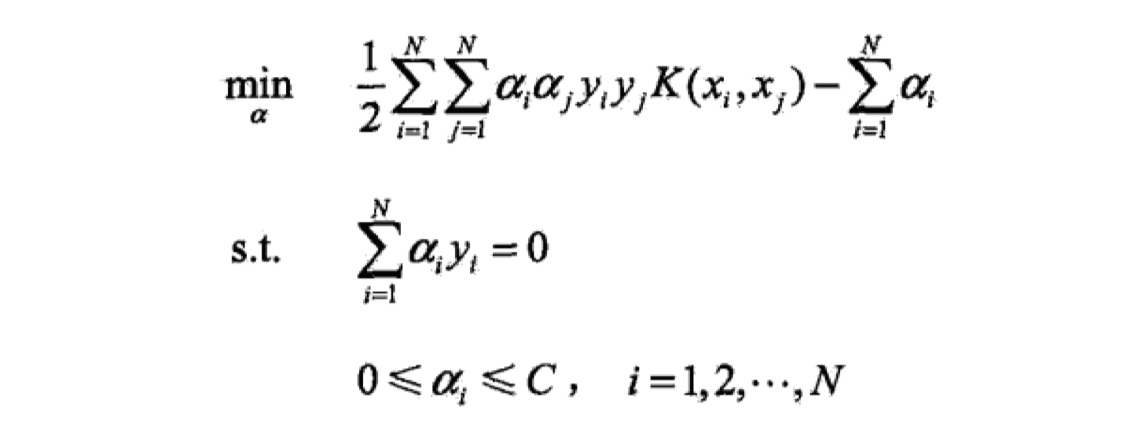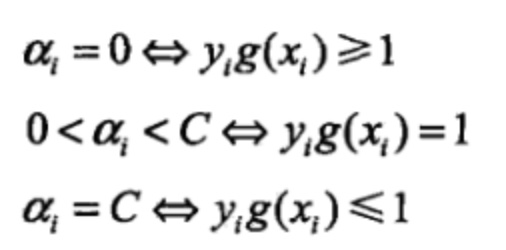支持向量机(SVM)是一种二类分类模型,属于监督学习,能够用来解决数据线性不可分的问题,是对感知机模型的补充和扩展。本篇博客将对SVM的三种情形进行详细地讲解,并采用纯python实现以及调用scikit-learn库实现,这两种方式对感知机模型进行实现。
支持向量机模型概述 支持向量机模型本身是一种二类分类模型,当然目前已经有很多方法,从而使得SVM实现多分类。SVM可以属于硬分类模型,它打破了感知机训练数据集线性可分的假设,从而能够处理训练数据集线性不可分的情况。SVM有三种情形:训练数据集线性可分、训练数据集近似线性可分、训练数据集线性不可分 。当训练数据集线性可分时,我们使用硬间隔最大化策略,训练一个线性分类器,称为线性可分SVM ;当训练数据集近似线性可分时(严格来说就是线性不可分),我们使用软间隔最大化策略,训练一个线性分类器,称为线性SVM ;当训练数据集线性不可分时,我们使用核技巧+软间隔最大化策略,训练一个非线性分类器, 称为非线性SVM或kernel SVM 。接下来,我们将逐步讲解这三种情况,依然从模型、策略、算法 的角度,来进行讲解。
线性可分SVM 当训练数据集时线性可分时,训练出来的分类器。我们称为线性可分SVM。
线性可分SVM模型 线性可分SVM模型如下:
其中,$x$是模型输入,$y$是模型输出,并且$x\in R^n,y\in \{1,-1\}$;$w,b$是模型参数,并且$w\in R^n,b\in R$。看到这个模型,是不是非常熟悉?对,就是之前讲过的感知机模型(perceptron)!实际上,我们就是要找一个分离超平面,将数据集中的正例与负例完全分开。但是在感知机中,分离超平面不唯一。那么,到底哪个超平面才是最优的呢?在SVM中,就是要找到最优的超平面。
那么,一般来说,对于被模型分类的点,我们关注两个方面:模型分类的确信程度,模型分类是否正确。对于模型分类的确定程度,我们可以使用点到平面的距离来表示;对于模型是否分类正确,我们使用模型的预测值与该实例本身的类别标号是否一致来表示。所以,我们可以使用$y_i(wx_i+b)$来表示模型的正确性与确信程度,这就是函数间隔。但是,只有函数间隔是不够的,因为当$w,b$增大若干倍的时候,超平面没变,但是函数间隔却变大了,所以我们需要对其加一些约束,这就是几何间隔。几何间隔越大,那么点距离超平面就越远(距离超平面越近的点,那么越难被正确分类),那么说明这样的超平面的泛化能力应该越好。所以,线性可分SVM的策略就是找到能够正确分类并且几何间隔最大的分离超平面。
线性可分SVM模型的学习策略 原始形式
线性可分SVM模型的学习策略叫做最大间隔法。就是找到间隔最大的分离超平面。那么就转换为下面这个最优化问题:
其中,$\gamma$ 表示几何间隔,此外,带有一个约束条件:所有的点到超平面的几何间隔都必须大于最小的几何间隔,这是显而易见的。又由于几何间隔与函数间隔的转换关系,那么,我们可以将上述最优化问题,变换一下形式,如下:
我们仔细分析一下这个最优化问题,我们会发现函数间隔$\hat \gamma$ 不影响目标函数与约束条件。因为当函数间隔$\hat \gamma$ 增大$\lambda$倍后,及$w,b$均增大$\lambda$倍后,将其带入上述目标函数与约束条件,会发现整个问题并不会发生变化,因为$\lambda$都被约掉了。所以,我们不妨就设$\lambda=1$。此外,在机器学习中,我们更加习惯求解最小化问题,那么,化简后就是最终的最优化问题。公式如下:
总结一下 :
输入:给定训练数据集$X=\{(x_1,y_1),(x_2,y_2),(x_3,y_3),…,(x_N,y_N)\}$,其中$x_i\in R^n,y\in R,i=1…N$。
输出:参数$w,b$,从而得到SVM模型与分离超平面。
通过求解凸二次规划问题的最优化算法,求得$w^{\ast},b^{\ast}$。
将$w^{\ast},b^{\ast}$ 带入公式中,得到SVM模型与分离超平面。如下:
对偶形式
对于凸二次规划问题,我们可以通过求解其对偶问题,从而来求原始问题的解。我们使用拉格朗日乘子法,构造拉格朗日函数,如下:
那么,我们要求的公式就是:$max_{\alpha}min_{w,b}L(w,b,\alpha)$。所以就分两步:先求令$L(w,b,\alpha)$最小的$w,b$(此时的$w,b$的值时带有未知变量$\alpha$的,还不是最终的值),再求令令$L(w,b,\alpha)$最大的$\alpha$的值,最后根据$\alpha$的值,得出$w,b$最终的值。
先求$min_{w,b}L(w,b,\alpha)$。我们对$w,b$求偏导,即令$\frac {\partial L}{\partial w}=0,\frac {\partial L}{\partial b}=0$,可以得到下述式子:
将上述式子带入到最初的拉格朗日函数中,并化简得到如下公式:
接下来,我们求$max_{\alpha}min_{w,b}L(w,b,\alpha)$。
由于其满足KKT条件,所谓KKT条件如下:
我们会根据KKT条件,尤其是互补松弛条件,可以得出b的值。参数$w,b$最终的值如下:
总结一下:
输入:给定训练数据集$X=\{(x_1,y_1),(x_2,y_2),(x_3,y_3),…,(x_N,y_N)\}$,其中$x_i\in R^n,y\in R,i=1…N$。
输出:参数$w,b$,从而得到SVM模型与分离超平面。
求得最优解$\alpha^{\ast}=\{\alpha^{\ast}_{1},\alpha^{\ast}_{2},…,\alpha^{\ast}_{N}\}$。
根据$\alpha^{\ast}$,计算得到最优参数$w^{\ast},b^{\ast}$,公式如下:
将参数$w^{\ast},b^{\ast}$带入SVM模型与超平面公式中,就得到了结果。
学习算法 即便在对偶形式的SVM中,最终还是要求$\alpha^{\ast}$的值,这个时候就需要采取求解凸二次规划问题的算法求解,在SVM中,我们采取的方法叫做:序列最小最优化算法(SMO) 。后面会介绍。
线性SVM 当线性可分中数据集混入一些噪音(outlier),也就是分类不正确的点,那么这个时候,整个数据集就变得线性不可分了;但是由于噪音的数量较小,所以我们可以通过改变一下线性可分SVM的学习策略,从而训练处线性SVM。
注意:由于线性可分SVM与线性SVM的模型与对偶最优化问题的化简求解是一样的,所以在这里,我只会将讲解其与线性可分SVM不通的地方,也就是学习策略:软间隔最大化。
所谓的噪音$(x_i,y_i)$,也就是它的几何间隔不满足约束,也就是$y_i(wx_i+b)<1$。那么,我们就可以加入一个松弛变量$\varepsilon_i$,使得其约束条件大于或等于1。此外,我们需要在目标函数中加入惩罚项$C$,惩罚被误分类的点,从而使得实例更难被误分类。具体公式如下:
这是一个凸二次规划问题,同样地,我们可以通过求其对偶最优化问题,来求解参数$w,b,从而得到SVM模型与分离超平面,步骤与线性可分SVM步骤一样(这个推导步骤,最好自己手推一遍~)。最后结果如下:
非线性SVM / kernel SVM 当线性可分数据集中,混入了大量的噪音,导致整个数据集完全不可通过线性模型来进行分类的话,这个时候就需要非线性SVM了。当然,在这种SVM中,一个非常重要的概念叫做 kernel trick 。下面就简单地介绍一下什么是kernel trick。(关于kernel trick详细的数学证明与推导,请参看《统计学习方法》或者PRML ,在这里,我只讲解kernel trick的原理。)
kernel trick 由于在原来的输入空间中,我们得到的分离超平面最终会是一个曲面,那么这样的非线性模型是不好训练的。那么一种想法是:将原来的输入空间通过非线性变换,将其映射到一个高维空间,将非线性问题转换为线性问题,从而在新的特征空间中学习线性分类模型。(这是有定理保证的,高维比低维更易线性可分。)这其实就是kernel trick的思想。
这个公式中,$\phi$是非线性映射,$x,z$均属于原来的输入空间,正定核函数$K(x,z)$是变换后的结果。通过这个变换,我们就可以将原来输入空间中的内积$x_ix$,变换到新的特征空间中的内积$\phi(x_i)\phi(x)$,从而在新的特征空间中学习线性分类模型即可。
但是,这样带来一个问题:非线性映射$\phi$是非常难求的,求它们的内积更加难求。那么,在实际操作中,我们通常的做法是直接去$K(x,z)$,而不通过找$\phi$来计算结果,这样大大减少了计算量。那么如果判断一个函数是正定核函数(kernel function)呢?在这里有一个定理,叫做Mercer定理 。它其实是从核函数的定义出发的(这里可能和《统计学习方法》表述不一样,但是意思是一样的)。如下:
设$x,z\in\cal X\in R^n$,$\cal X$表示原来的输入空间,对于任意的$x,z$,存在函数$K:\cal X *\cal X ->R^p$,并且这个函数$K$满足两个性质:对称性与正定性,那么就说函数$K$是正定核函数。 所谓对称性,就是$K(x,z)=K(z,x)$。所谓正定性,就是$K(x,z)$所对应的Gram矩阵是半正定的,半正定的意思是该矩阵的特征值大于等于0。对称性显而易见,那么判断一个对称函数是不是的正定核函数的充要条件就是其构成的Gram矩阵是半正定的 。具体证明过程,可以参看《统计学习方法》。我们常用的正定核函数是高斯核函数,如下:
那么,根据高斯核函数,我们可以得到SVM模型,也就是分类决策函数如下:
序列最小最优化算法(SMO) 这是SVM中最后一个部分,主要是用来求解凸二次规划问题,也就是求$\alpha$的值,只有求出了$\alpha$的值,$w,b$的值才算是真正的求出来。我们将核函数带入到最优化问题当中,得到如下式子:
其实有很多最优化算法来求解这个凸二次规划问题,在SVM中,我们使用SMO算法来求解,因为当数据量很大的时候,该算法也能很好很快地求解。该算法的思想是:由于KKT条件是最优化问题最优解的充要条件,如果所有的变量$\alpha$都满足KKT条件的话,那么最优解就求出来了。如果不满足的话,那么我们就不断地去调整$\alpha$的值,直到所有的$\alpha$都满足KKT1条件。那么怎么调整呢?方法是:我们构建多个只有两个变量的二次规划问题,最终找到所有最优的$\alpha$的值 。具体过程如下:
通过上述计算,我们就可以得到未修建的$\alpha_2$与$\alpha_1$的值。但是在得到这个值的时候,我们并没有考虑约束条件,所以我们要将约束条件加上,得到最终的$\alpha_2$的值,计算过程如下:
那得到$\alpha_2$的后,其实$\alpha_1$的就很容易求出来了,如下:
之后,我们不断去重复这样的过程,便可将所有的$\alpha$的值都求出来。但是,问题来了,我们每次怎么去选择这两个变量呢? 也就是说,我们怎么知道选择哪两个变量,才能使得最优化问题能够朝着最小的方向走呢?
在SMO中,第一个变量,我们可以选择违反KKT条件最明显的变量作为$\alpha_1$。 KKT条件如下:
在实际操作中,可以遍历所有的样本点,看哪个违反最严重,从而将该点最为第一个变量。
第二个变量,找使$|E_1-E_2|$的变量 。$E_i$的计算公式,前面已经提到了。
以上就是全部的SVM的理论部分了~
SVM的实现 把模型实现一遍才算是真正的吃透了这个模型呀。在这里,我采取了两种方式来实现SVM模型:纯python实现以及调用scikit-learn库来实现。我的github里面可以下在到所有的代码,欢迎访问我的github,也欢迎大家star和fork。附上GitHub地址: 《统计学习方法》及常规机器学习模型实现 。具体代码如下:
python实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 ''' 数据集:Mnist(实际只使用了前1000个,当然可以全部使用,如果算力够的话。) 准确率:0.98 时间:0.98 ''' import numpy as npimport timedef loadData (fileName ): ''' 加载数据 :param fileName:路径名 :return: 返回特征向量与标签类别 在这里需要注意的是:最后使用要np.array,以保证维度。 当然使用np.mat等也没有问题,但是相关操作容易搞混。 ''' data_list = [] label_list = [] with open (fileName, "r" ) as f: for line in f.readlines(): curline = line.strip().split("," ) if (int (curline[0 ]) ==0 ): label_list.append(1 ) else : label_list.append(-1 ) data_list.append([int (num)/255 for num in curline[1 :]]) data_matrix = np.array(data_list) label_matrix = np.array(label_list) return data_matrix, label_matrix class SVM (object def __init__ (self, data_matrix, label_matrix, sigma, C, toler, iteration ): ''' 构造函数 :param data_matrix: 训练数据集矩阵 :param label_matrix: 训练数据标签矩阵 :param sigma: 高斯核函数的sigma :param C: 惩罚参数 :param toler: 松弛变量 ''' self.train_data = data_matrix self.train_label = label_matrix.T self.input_num,self.feature_num = np.shape(self.train_data) self.sigma = sigma self.C = C self.toler = toler self.K = self.kernel_for_train() self.b = 0 self.alpha = np.zeros(self.input_num) self.E = np.zeros(self.input_num) self.iteration = iteration self.support_vector = [] def kernel_for_train (self ): ''' 计算核函数 使用的是高斯核 详见“7.3.3 常用核函数” 式7.90 :return: 高斯核矩阵 ''' k=np.zeros((self.input_num,self.input_num)) for i in range (self.input_num): if i % 100 == 0 : print('construct the kernel:' , i, self.input_num) X = self.train_data[i, :] for j in range (i, self.input_num): Z = self.train_data[j, :] result =np.matmul((X - Z) , (X - Z).T) result = np.exp(-1 * result / (2 * self.sigma**2 )) k[i][j] = result k[j][i] = result return k def is_satisfied_kkt_condition (self, i ): ''' 判断alpha_i是否满足KKT条件 :param i: 索引第i个alpha :return: 返回true/false ''' g_xi = self.cal_g_xi(i) y_i = self.train_label[i] if ((abs (self.alpha[i]) < self.toler) and (y_i * g_xi >= 1 )): return True elif (abs (self.alpha[i] - self.C) < self.toler and (y_i * g_xi <= 1 )): return True elif (self.alpha[i] > -self.toler) and (self.alpha[i] < (self.C + self.toler)) \ and (abs (y_i * g_xi - 1 ) < self.toler): return True return False def cal_g_xi (self, i ): ''' 计算g_xi,从而辅助判断变量是不是满足KKT条件 :return: 返回g_xi的值,是标量 ''' g_xi = 0 index = [i for i,alpha in enumerate (self.alpha) if alpha!=0 ] for j in index: g_xi += self.alpha[j] * self.train_label[j] * self.K[j][i] g_xi += self.b return g_xi def cal_ei (self, i ): ''' 计算ei的值,标量 :param i: 表示第i个样本,i=1,2 :return: 返回Ei ''' return self.cal_g_xi(i) - self.train_label[i] def cal_alpha_j (self, e1, i ): ''' 在SMO中,选择第2个变量 :param e1: 第一个变量的e1 :param i: 第一个变量alpha1的下标 :return: 返回E2,第二个遍历变量的下标 ''' e2 = 0 max_e1_e2 = -1 max_index = -1 none_0_e = [i for i, ei in enumerate (self.E) if ei != 0 ] for j in none_0_e: e2_tmp = self.cal_ei(j) if abs (e1 - e2_tmp) > max_e1_e2: max_e1_e2 = abs (e1 - e2_tmp) e2 = e2_tmp max_index = j if max_index == -1 : max_index = i while max_index == i: max_index = int (np.random.uniform(0 , self.input_num)) e2 = self.cal_ei(max_index) return e2, max_index def train (self ): cur_iter_step = 0 params_changed = 1 while ((cur_iter_step < self.iteration) and (params_changed > 0 )): print(f"the current iteration is {cur_iter_step} ,the total iteration is {self.iteration} ." ) cur_iter_step += 1 params_changed = 0 for i in range (self.input_num): if (self.is_satisfied_kkt_condition(i) == False ): e1 = self.cal_ei(i) e2, j = self.cal_alpha_j(e1, i) y1 = self.train_label[i] y2 = self.train_label[j] alpha_old_1 = self.alpha[i] alpha_old_2 = self.alpha[j] if (y1 != y2): L = max (0 , alpha_old_2 - alpha_old_1) H = min (self.C, self.C - alpha_old_1 + alpha_old_2) else : L = max (0 , alpha_old_1 + alpha_old_2 - self.C) H = min (self.C, alpha_old_1 + alpha_old_2) if (L == H): continue k11 = self.K[1 ][1 ] k22 = self.K[2 ][2 ] k12 = self.K[1 ][2 ] k21 = self.K[2 ][1 ] alpha_new_2 = alpha_old_2 + y2 * (e1 - e2) / (k11 + k22 - 2 * k12) if (alpha_new_2 < L): alpha_new_2 = L elif (alpha_new_2 > H): alpha_new_2 = H alpha_new_1 = alpha_old_1 + y1 * y2 * (alpha_old_2 - alpha_new_2) b1_new = -1 * e1 - y1 * k11 * (alpha_new_1 - alpha_old_1) \ - y2 * k21 * (alpha_new_2 - alpha_old_2) + self.b b2_new = -1 * e2 - y1 * k12 * (alpha_new_1 - alpha_old_1) \ - y2 * k22 * (alpha_new_2 - alpha_old_2) + self.b if (alpha_new_1 > 0 ) and (alpha_new_1 < self.C): b_new = b1_new elif (alpha_new_2 > 0 ) and (alpha_new_2 < self.C): b_new = b2_new else : b_new = (b1_new + b2_new) / 2 self.alpha[i] = alpha_new_1 self.alpha[j] = alpha_new_2 self.b = b_new self.E[i] = self.cal_ei(i) self.E[j] = self.cal_ei(j) if abs (alpha_new_2 - alpha_old_2) >= 0.00001 : params_changed += 1 for i in range (self.input_num): if self.alpha[i] > 0 : self.support_vector.append(i) def kernel_for_predict (self, x, z ): ''' 计算核函数,用于测试集与开发集 :param x:向量x :param z: 向量z :return: 返回核函数 ''' result = np.matmul((x - z), (x - z).T) result = np.exp(-result / (2 * self.sigma ** 2 )) return result def predict (self, x ): ''' 预测单个样本的类别 :param x: 样本的特征向量 :return: 样本的预测类别 ''' result = 0 for i in self.support_vector: result_temp = self.kernel_for_predict(x, self.train_data[i]) result += self.alpha[i] * self.train_label[i] * result_temp result += self.b return np.sign(result) def test (self, test_data, test_label ): ''' 在测试集上测试模型 :param test_train:测试集的特征向量 :param test_label:测试集的类别 :return:准确率 ''' test_label=test_label.T error = 0 test_input_num = test_data.shape[0 ] for i in range (test_input_num): result = self.predict(test_data[i]) if (result != test_label[i]): error += 1 else : continue return (test_input_num - error) / test_input_num if __name__ == "__main__" : start = time.time() train_data, train_label = loadData("../MnistData/mnist_train.csv" ) test_data, test_label = loadData("../MnistData/mnist_test.csv" ) print("finished load data." ) svm = SVM(train_data[:1000 ], train_label[:1000 ], sigma=10 , C=200 , toler=0.001 ,iteration=50 ) svm.train() print("finish the training." ) accuracy = svm.test(test_data[:100 ], test_label[:100 ]) print(f"accuracy is {accuracy} ." ) end = time.time() print(f"the total time is {end - start} ." )
scikit-learn实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import numpy as npimport timefrom sklearn import svmdef loadData (fileName ): data_list = [] label_list = [] with open (fileName, "r" ) as f: for line in f.readlines(): curline = line.strip().split("," ) if (int (curline[0 ]) == 0 ): label_list.append(1 ) else : label_list.append(-1 ) data_list.append([int (feature) for feature in curline[1 :]]) data_matrix = np.array(data_list) label_matrix = np.array(label_list) return data_matrix, label_matrix if __name__ == "__main__" : train_data, train_label = loadData("../MnistData/mnist_train.csv" ) test_data, test_label = loadData("../Mnistdata/mnist_test.csv" ) print("finished load data." ) clf = svm.SVC() clf.fit(train_data[:1000 ], train_label[:1000 ]) print("finished training." ) accuracy = clf.score(test_data, test_label) print(f"the accuracy is {accuracy} ." )